AI agents aren't magic🪄🙅♂️. They're language models trained to predict very specific text.
When ChatGPT says 🔍"searching..." it's generating structured text that triggers actual tools.
Here's what's really happening 👇
SK Telecom + @AdaptiveML trained Gemma 3 4B with PPO obtaining impressive results, specially for a model of such size
Learn more about how they did this https://t.co/A1Iqriut09
Kimi K2 is a vision into the future of 𝘀𝘆𝗻𝘁𝗵𝗲𝘁𝗶𝗰 𝘁𝗼𝗼𝗹 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 and 𝗮𝗴𝗲𝗻𝘁𝗶𝗰 𝗺𝗼𝗱𝗲𝗹 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴.
Leveraging 3,000+ MCP tools, the team generated 20,000+ synthetic tools and used them to train their 1T MoE model.
📜Paper and pipeline ⬇️
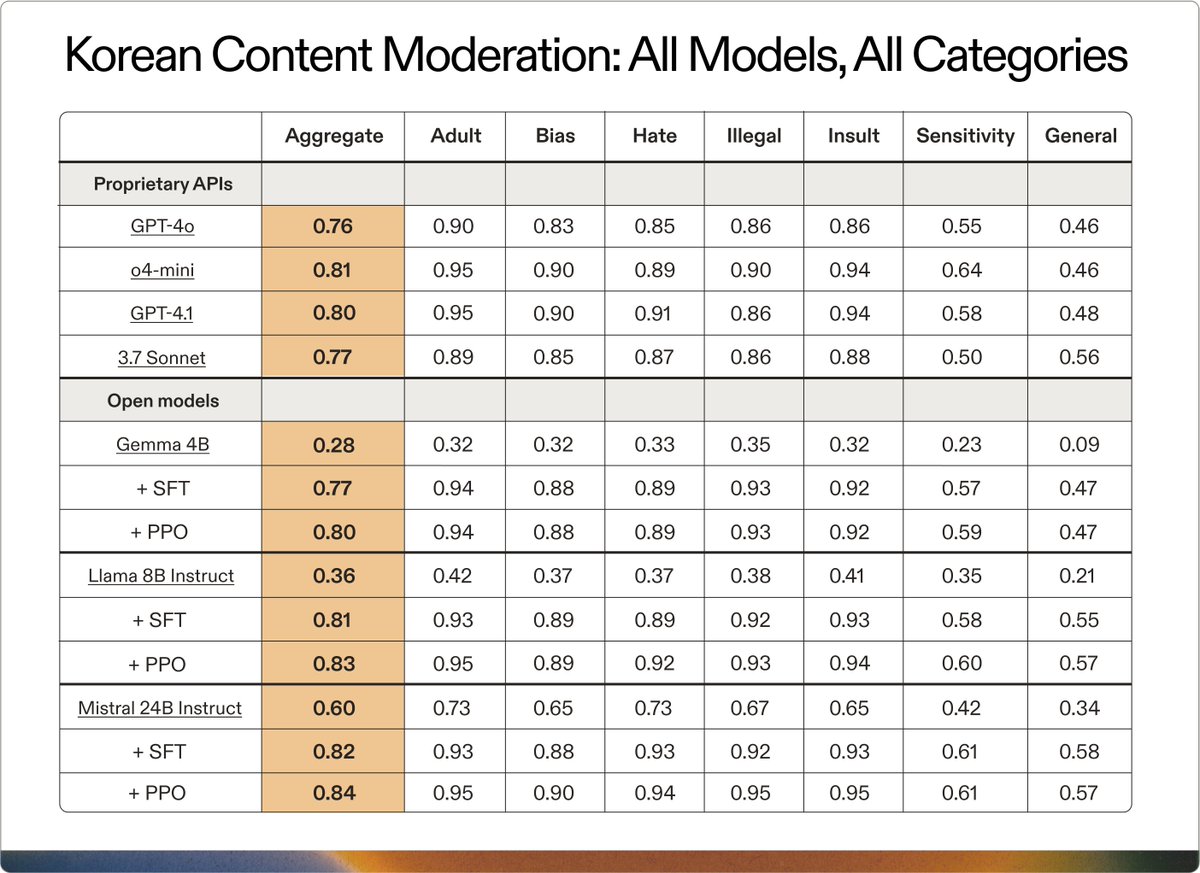
Build enterprise AI without the latency and cost of massive models. Learn how @AdaptiveML used Gemma 3 to create a multilingual customer service moderation LLM for @SKtelecom to support their 23M+ subscribers who speak a mix of English and Korean.
https://t.co/scwPSdSCXB
Build enterprise AI without the latency and cost of massive models. Learn how @AdaptiveML used Gemma 3 to create a multilingual customer service moderation LLM for @SKtelecom to support their 23M+ subscribers who speak a mix of English and Korean.
https://t.co/scwPSdSCXB
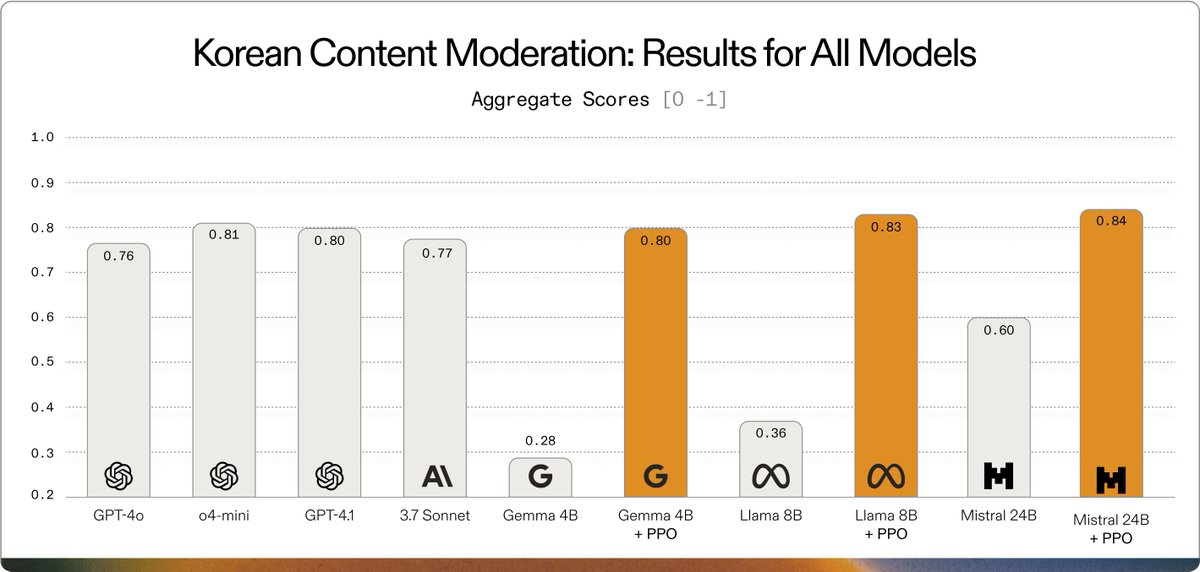
Using Adaptive Engine, @SKtelecom tuned open models as small as Gemma 3 4B to exceed frontier performance (GPT-4.1, 3.7 Sonnet, and o4-mini) at multilingual content moderation.
Our research 📃 and full results 👇
Looking forward to seeing everyone for ES-FoMo part three tomorrow! We'll be in East Exhibition Hall A (the big one), and we've got an exciting schedule of invited talks, orals, and posters planned for you tomorrow.
Let's meet some of our great speakers! 1/
ES-FoMo is back for round three at #ICML2025! Join us in Vancouver on Saturday July 19 for a day dedicated to Efficient Systems for Foundation Models: from 💬reasoning models to🖼️scalable multimodality, 🧱efficient architectures, and more!
Submissions due May 26! More below 👇
Pretrained LLMs are aliens of extraordinary intelligence, yet little understanding. 👽
How do post-training techniques like 𝐒𝐅𝐓, 𝐑𝐄𝐈𝐍𝐅𝐎𝐑𝐂𝐄, and 𝐏𝐏𝐎 work in-tandem to turn these aliens into helpful AI assistants? 🧵 👇
@giffmana tbh it's not amazing, but it is less terrible than most other options. cargo is great & static typing let's you refacto stuff much faster. otoh the borrow checker really can be a pain for quick prototyping of stuff, and proc macros are a terrible hack that needs to be used a lot
@Muennighoff@zach_nussbaum I was a bit unclear, information can leak in the forward pass from future tokens into the previous ones. Here's an illustration, you can completely predict the next token, through leakage in the routing.
Obviously very toy example, a single expert that choses a single token
@Muennighoff@zach_nussbaum (And assigning it to the last "hello" is just a matter of counting the number of previous hellos, and have the routing be a function of that).
I guess maybe you can't actually leak that much information through this. Might just be too costly to be worth exploiting it
@Muennighoff@zach_nussbaum Like you should be able to have one expert that says there's no more "hello" and assign it to the last "hello" in the sequence or smth. But y'know sometimes the optimization process is not strong enough to be able to exploit every loop hole. Cool finding tho!
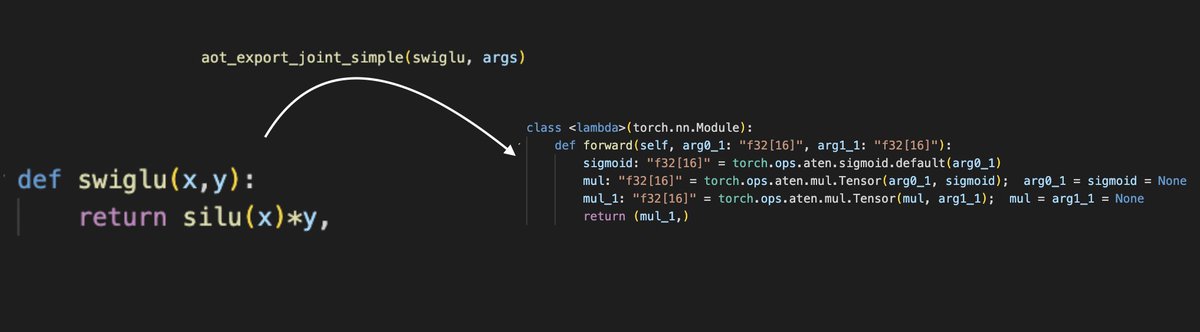
This is a very nice direction from @PyTorch! Even when we need the highest possible performance, we can still use Torch as a first step and export the IR to external codebases with production guarantees around memory etc!