New work @AIatMeta: We enable test-time scaling for long-horizon coding agents by using better representations, selection and reuse of agentic trajectories, with Claude 4.5 Opus improving by +6.7% on SWE-Bench Verified and +12.1% on Terminal-Bench 2.0.
📄: https://t.co/tvhdw0DuYd
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
How do coding agents get better from experience?
Past Attempts as Interface: Turn rollouts into structured summaries that future attempts can build on.
https://t.co/QuXXfoHC0I
How do coding agents get better from experience?
Past Attempts as Interface: Turn rollouts into reusable summaries that future attempts can build on.
https://t.co/VjglgPLzQQ
Takeaway: scaling long-horizon agents isn't just about more compute – it's about how prior experience is represented, selected, and reused.
Joint work with the amazing @anirudhg9119 and my collaborators across Meta, UW, NYU, CMU and Princeton.
📄: https://t.co/tvhdw0DuYd
[13/N]
New work @AIatMeta: We enable test-time scaling for long-horizon coding agents by using better representations, selection and reuse of agentic trajectories, with Claude 4.5 Opus improving by +6.7% on SWE-Bench Verified and +12.1% on Terminal-Bench 2.0.
📄: https://t.co/tvhdw0DuYd
Parallel aggregation analysis: we track pass@1 and pass@N across RTV rounds for both iterations. Average pass@1 rises as our policy selects successful rollouts, while pass@N drops slightly as some rollouts are eliminated – RTV still nets clear gains even after refinement.
[12/N]
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
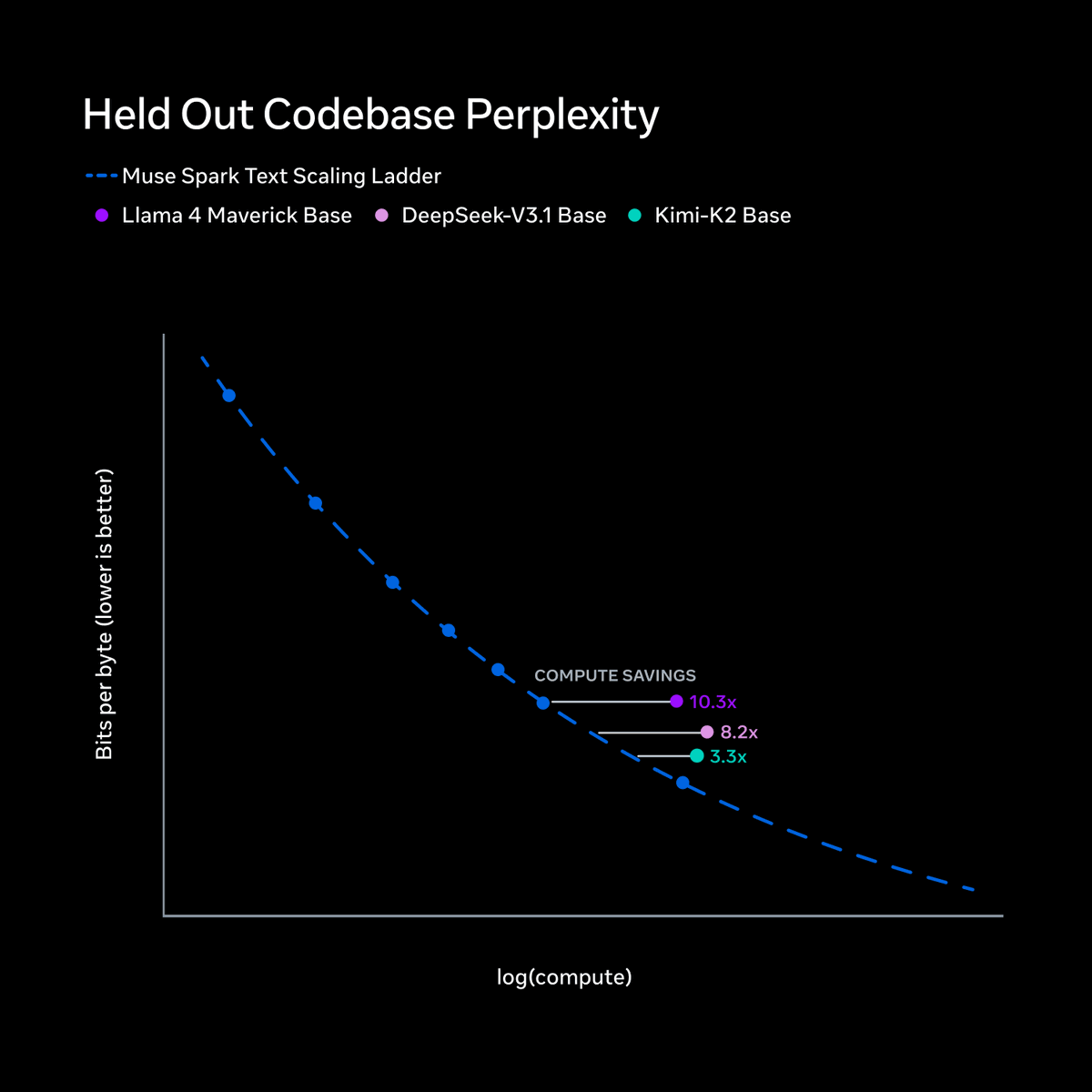
To build personal superintelligence, our model’s capabilities should scale predictably and efficiently. Below, we share how we study and track Muse Spark’s scaling properties along three axes: pretraining, reinforcement learning, and test-time reasoning. 🧵👇
Let’s start with pretraining. Over the last 9 months, we rebuilt our pretraining stack with improvements to model architecture, optimization, and data curation, enabling us to increase the capability we can extract from every unit of compute. To rigorously evaluate our new recipe, we fit a scaling law to a series of small models and compare the training FLOPs required to hit a specific level of performance.
The results: we can reach the same capabilities with over an order of magnitude less compute than our previous model, Llama 4 Maverick, making Muse Spark significantly more efficient than the leading base models available for comparison.

















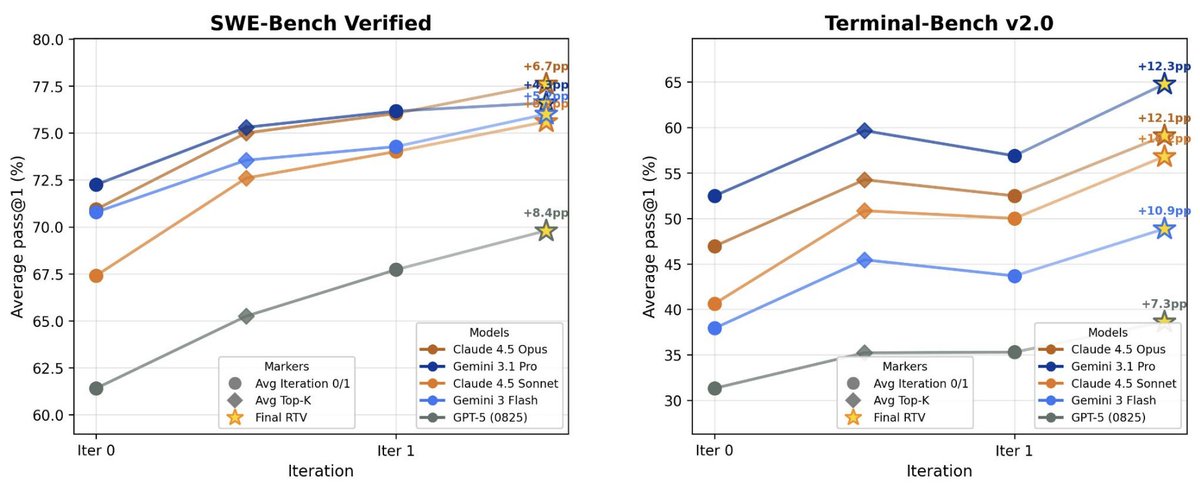






![danieljwkim's tweet photo. Parallel aggregation analysis: we track pass@1 and pass@N across RTV rounds for both iterations. Average pass@1 rises as our policy selects successful rollouts, while pass@N drops slightly as some rollouts are eliminated – RTV still nets clear gains even after refinement.
[12/N] https://t.co/d2YrgOHAdF](https://pbs.twimg.com/media/HGhL9gwagAEN0Ob.jpg)