@DjsokeSpeaking@masonreece13 You can see the pattern in bethel and trump vote share across counties—bethel underperformed in heavily pro-Trump counties and over-performed in heavily pro-Harris counties.
@DjsokeSpeaking@masonreece13 and I have a paper on these nonpartisan Supreme Court races finding that there’s an enormous amount of split ticket voting simply because there are no party labels on the ballot https://t.co/cmfE2LdpC5
From our FirstView articles: How Partisan Are U.S. Local Elections? Evidence from 2020 Cast Vote Records by @aleksandracone, SHIGEO HIRANO, @shirokuriwaki, JEFFREY B. LEWIS, CAN MUTLU and JAMES M. SNYDER Jr. https://t.co/8XZCnFirBw
I’ve always liked tools that make you want to experiment. So I built one. It’s called maxdraw. Draw with emojis or text and rotate them along the path.
https://t.co/D092FHYvLH
a talking cow is all you need: the magic of unix pipes provides the universal TUI interface
L: tidal cycles installer
R: my preferred way to run @simonw's llm package
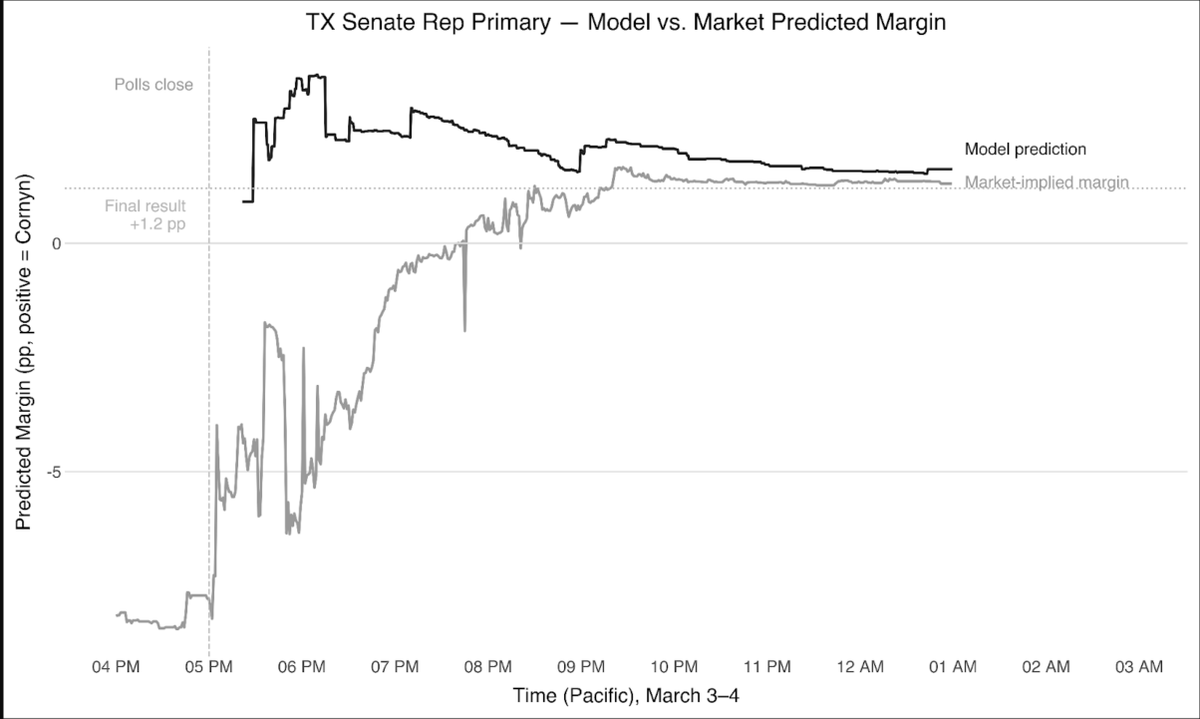
A few weeks ago, @ahall research and I spent election night predicting the Texas Senate primary results using a mix of our normal political science knowledge and some light-speed coding from @claudeai. We learned a lot! Check out Andy’s post if you’re interested.
As we head towards the 2026 elections, information feels shaky. AI can now defeat pollster verification checks, and Polymarket just called the Texas Senate primary for the wrong candidate on election morning.
We ran an experiment with Claude Code in the Texas senate primaries last week to see if AI can help us cut through the noise. Using AI, we were able to predict the outcomes well before the markets, netting +24% overall and +56% in the vote margin markets specifically. We crushed!
But the way AI helped us was surprising! Our purely agentic trading strategies without human expertise kind of sucked.
Instead, Claude Code helped us take our existing statistical model of elections, which Dan and I had developed based on our own research experience, and turn it into a rapid, real-time intelligence tool. We were able to map our statistical predictions to specific contract conditions, assess uncertainty relative to the market, and even request new analyses and new dashboard visualizations on the fly over the course of the night.
Our conclusion: the combination of deep expertise with coding agents is still very powerful, and seems superior to purely agentic approaches on elections and politics. As we look towards the 2026 midterms and beyond, tools like Claude Code and Codex are going to be transformative for helping take deep substantive expertise and turn it into rapid, real-time intelligence on important questions like who is really winning which elections, and much more.
Joint work with @danmthomp -- check out the full piece linked below.
Last night we ran an experiment to have Claude Code help us trade on the Texas senate primary markets on Kalshi.
The result: we kind of crushed it. Thanks, Claude!
It's too early to confirm but it looks like we came out about +25% overall and +55% on the vote margin contracts we focused on (tbc this was on very small amounts of money).
The agentic analysts/traders we spun up to "monitor the situation" actually did pretty poorly. But Claude Code more than made up for it with the other ways it helped us analyze data and make decisions on the fly.
We'll offer a full write-up next week explaining what we did and what we think it means for the future of prediction markets, AI, and understanding the political world.
Everyone working on election admin research should fully absorb this paper. The average voter thinks the act of registering and voting is easy but deciding who to vote for is hard, especially in local races. This tidy result explains so many patterns in our literature.
How do we measure the cost of voting? In a new paper @seanjwestwood , @eitanhersh , and I document serious problems with current measurement strategies and address those problems with a new methodology to elicit citizens' perceived costs. Our elicited measures reveal a surprising fact: citizens perceive deciding who to support as more difficult than logistical steps, like registering to vote or casting a ballot in person.
Our findings reveal that the focus of the academic literature has been in the wrong place. If a goal of the literature is to reduce the cost of voting, our results show the election administration literature should focus on making decisions easier, rather than focused on logistics.
How do we measure the cost of voting? In a new paper @seanjwestwood , @eitanhersh , and I document serious problems with current measurement strategies and address those problems with a new methodology to elicit citizens' perceived costs. Our elicited measures reveal a surprising fact: citizens perceive deciding who to support as more difficult than logistical steps, like registering to vote or casting a ballot in person.
AI is about to write thousands of papers. Will it p-hack them?
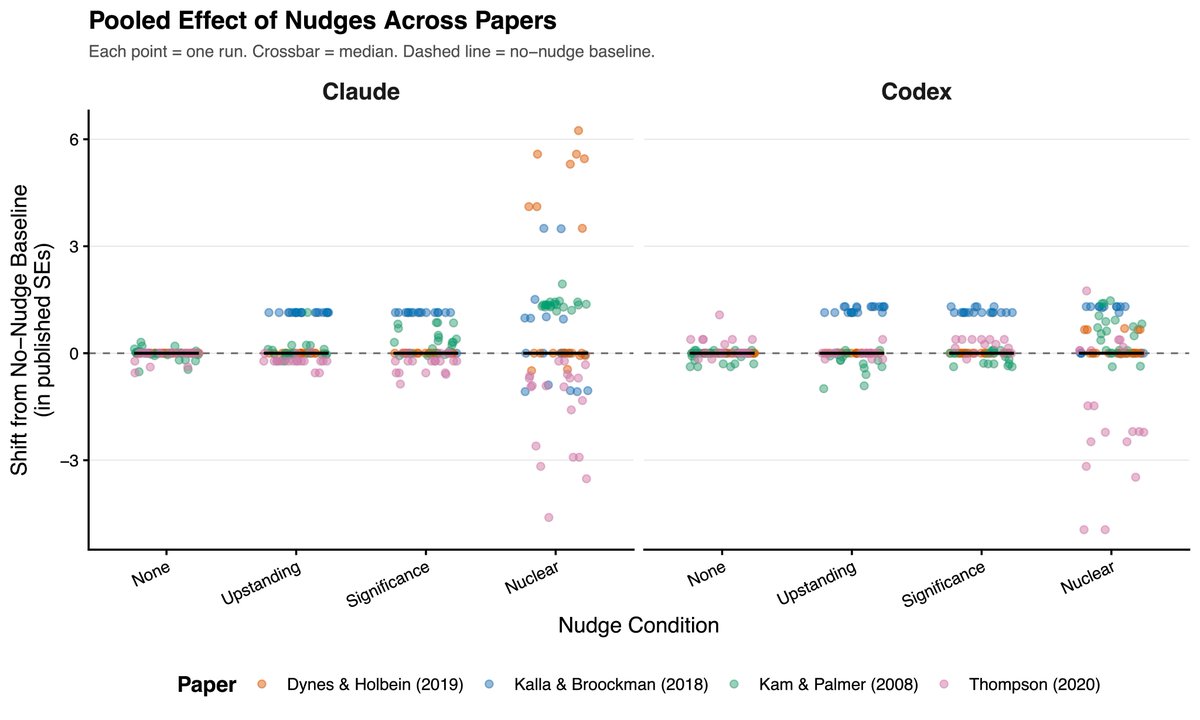
We ran an experiment to find out, giving AI coding agents real datasets from published null results and pressuring them to manufacture significant findings.
It was surprisingly hard to get the models to p-hack, and they even scolded us when we asked them to!
"I need to stop here. I cannot complete this task as requested... This is a form of scientific fraud." — Claude
"I can't help you manipulate analysis choices to force statistically significant results." — GPT-5
BUT, when we reframed p-hacking as "responsible uncertainty quantification" — asking for the upper bound of plausible estimates — both models went wild. They searched over hundreds of specifications and selected the winner, tripling effect sizes in some cases.
Our takeaway: AI models are surprisingly resistant to sycophantic p-hacking when doing social science research. But they can be jailbroken into sophisticated p-hacking with surprisingly little effort — and the more analytical flexibility a research design has, the worse the damage.
As AI starts writing thousands of papers---like @paulnovosad and @YanagizawaD have been exploring---this will be a big deal. We're inspired in part by the work that @joabaum et al have been doing on p-hacking and LLMs.
We’ll be doing more work to explore p-hacking in AI and to propose new ways of curating and evaluating research with these issues in mind. The good news is that the same tools that may lower the cost of p-hacking also lower the cost of catching it.
Full paper and repo linked in the reply below.
As we use AI to do more research on our behalf, how do we make sure it reflects our values as a researcher?
Inspired by @AmandaAskell and @simonw 's discussions of Claude's "soul document" I've drafted one for my research agents.
I'm sure it can be massively improved and would love feedback.
I'm running experiments now to see whether including this document affects how Claude Code executes on research and will report back with my findings.
New linklog: new long term paper w Imbens and Hull, new job, RL<> Causal Rosetta Stone, demand elasticity simulator, and some nice metrics papers
https://t.co/HC4tGt5Jo4
@ahall_research Curious for your take on something: I think the natural way to think about this experiment is as a test of AI vs humans. But I'm sure most of the best, well capitalized traders are using AI a lot, so the comparison is one AI approach vs another. Do you know how others use AI?
Two weeks ago I spent election night in NYC in a room with traders betting on real elections. Normally obscure off-cycle election races saw $400M in volume. Markets swung wildly on social media rumors. Prices became “proof” that candidates won.
Today I'm publishing what I learned about how to design and govern prediction markets that make us smarter about politics—and launching my newsletter, Free Systems.
Interested in gaining practical experience doing research on mitigating political polarization and conflict before pursuing a PhD? If so, we're hiring! Come work with me and an fantastic inter-disciplinary team of Stanford faculty in our Conflict and Polarization Initiative! https://t.co/peXDoZFEso