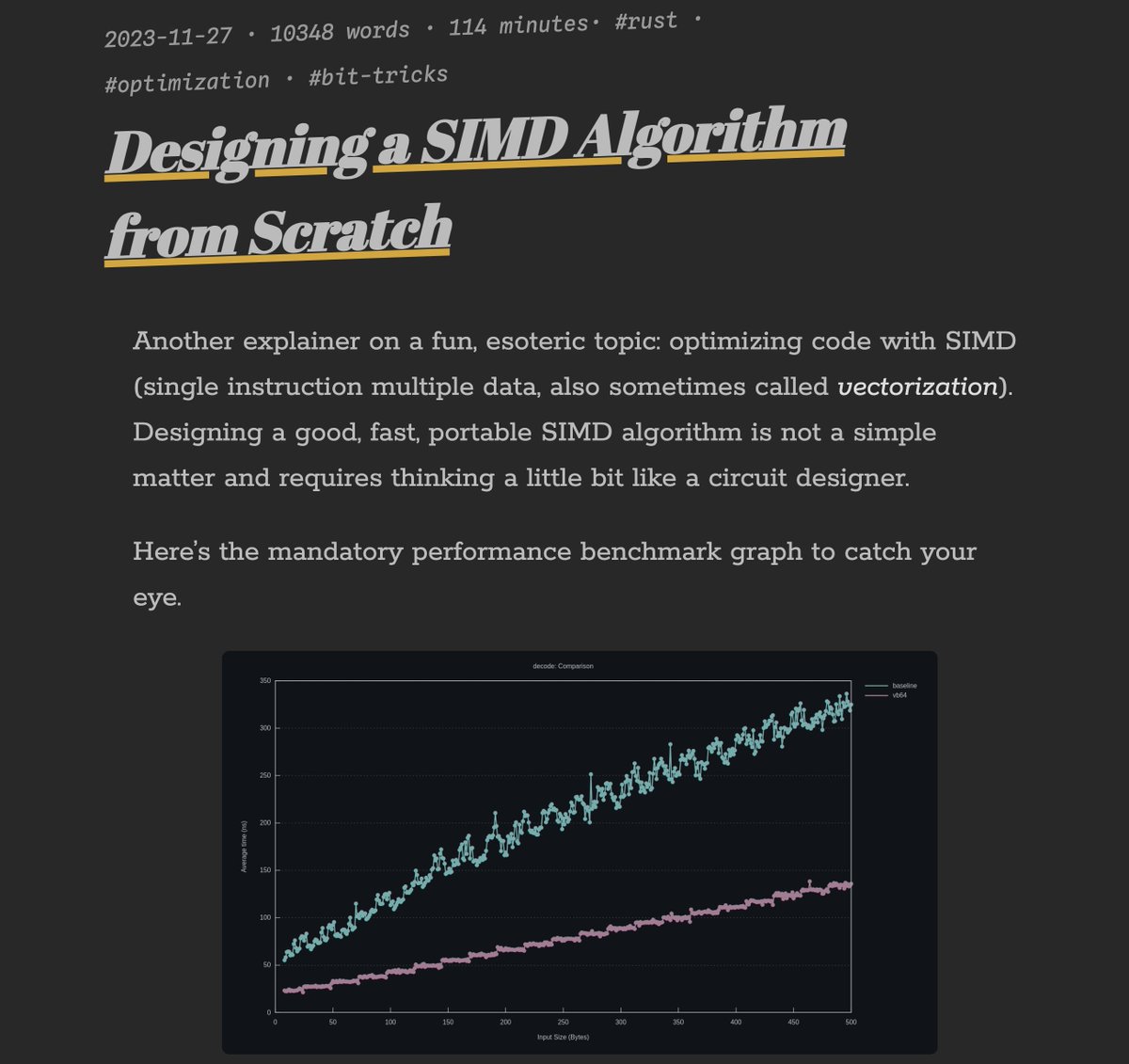
During one of the interactions with students at IISc today, we briefly talked about SIMD. And I can't recommend this article enough for understanding the details behind it - a must-read.
https://t.co/Xs5iTHRFjT
I will never,EVER again complain about petty problems in my life. #SheetalDevi you are a teacher to us all. Please pick any car from our range & we will award it to you & customise it for your use.
We’re THRILLED to introduce the companies in the Blackberry IVY L-SPARK Accelerator!
@Deepliteai
@RavenConnected
Sensor Cortek
Wedge Networks
Learn more about how these companies are creating solutions to improve driver + passenger experiences 🚘 https://t.co/ZmamK6InjE
fantastic blog post by @chipro
https://t.co/ydV7mutppk
"With so many new offerings for hardware to run ML models on, one question arises: how do we make a model built with an arbitrary framework run on arbitrary hardware?"
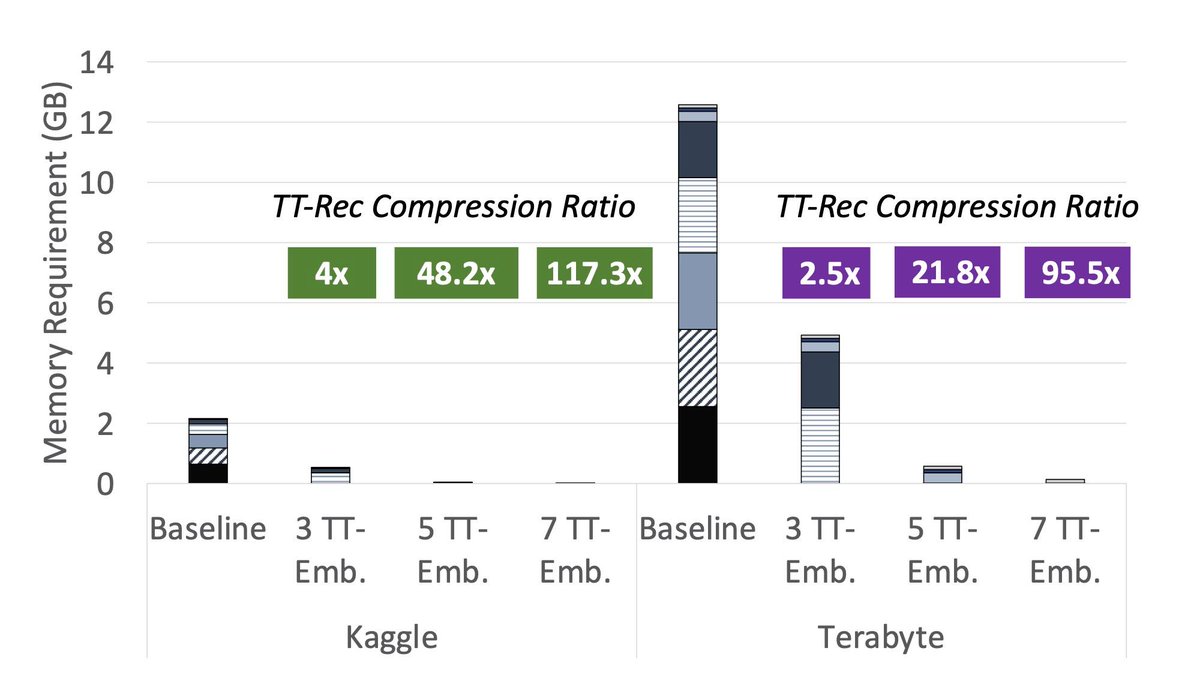
Introducing TT-Rec, a new method to dramatically shrink memory-intensive Deep Learning Recommendation Models and make them easier to deploy at scale. https://t.co/IiGmIakkZZ
I'm looking for interesting #FPGA blogs. What do you read?
Three I enjoy:
• https://t.co/9GJNyyWpUW
• https://t.co/q347Ec41yP
• https://t.co/t1E6zQ7eW6
#arXiv#machinelearning [cs.LG] Woodpecker-DL: Accelerating Deep Neural Networks via Hardware-Aware Multifaceted Optimizations. (arXiv:2008.04567v1 [cs.DC]) https://t.co/jL7MoxKUJj
Accelerating deep model training and inference is crucial in practice. Existing deep learning fr…
#ODSC_India@ODSC_India just accepted On-Demand Accelerating Deep Neural Network Inference via Edge Computing https://t.co/DzWfT4jb2D by @darshancg3 Deepesh Agrawal
#ODSC_India@ODSC_India just accepted On-Demand Accelerating Deep Neural Network Inference via Edge Computing https://t.co/apPuyfWkhh by @darshancg3 Deepesh Agrawal
Watch this video featuring the CEOs from @reniacinc and @meghcomputing explaining the cross-architecture development benefits they’ve experienced with #oneAPI. https://t.co/jeqmzug3oS #AI
#CellStratAILab#disrupt4.0 #WeCreateAISuperstars#WhereLearningNeverStops
Deep Neural Networks are becoming more and more complex day by day, hence there is a necessity of Algorithms and Efficient Hardware Architectures for Efficient Deep Neural Network…https://t.co/Vki9sXURep
#CellStratAILab#disrupt4.0
Last Friday, our AI Lab Researcher Darshan G presented a wonderful overview of GPU Architectures and General-Purpose GPU Computing.
Performance Improvements are often based on parallelism techniques such as Pipelining, Level…https://t.co/vEkZA5w3ez
Today we're making GitHub free for teams of unlimited size, for private and public work. 🎉
Every developer on earth should have access to GitHub, and price shouldn't be a barrier.
https://t.co/EOn37hItY6
#CellStratAILab#disrupt4.0
Minutes from Sunday 22nd March 2020 AI Workshop at BLR :-
Last Saturday our AI Lab Researcher Niraj Kale presented an amazing workshop on Object Detection with EfficientNet and EfficientDet.
EfficientNet is about developing…https://t.co/dr5nLLc4I8
I love High Level Synthesis! It really comes in useful for creating complex image / signal processing IP quickly. This week I am showing how to create a custom image processing block in Vivado HLS.
#fpga#electronics#imageprocess…https://t.co/sCkKfYDmwO https://t.co/O5wY86LuY8