Underexplored LLM failure mode: Specificity Hallucination
You need: "patient must lie down"
LLM says: "patient must lie on their back"
Not wrong—too specific. The model invented precision that doesn't exist.
RLHF rewards detail. Even fabricated detail.
Upgraded to vLLM 0.12.0 on my H100s.
Text models: +17% throughput (17.8 → 20.8 req/s) ✅
Multimodal models: breaks if CUDA <12.9 — ViT FlashAttention kernels need 12.9, no way to opt out.
Fix: keep vision-language models on vLLM 0.8.x for now.
Finally got around to posting about Orchestra v3 (rip v2 announcement)
Inference service system for running multiple AI models on GPUs. True concurrent batching, 10-15x throughput improvement.
https://t.co/2eIMN16nne
Spent hours debugging vLLM memory errors. "Not enough KV cache blocks" on an 80GB H100. Made no sense.
The fix? One line: export VLLM_USE_V1=0
V1 engine has a bug — it calculates memory budget after torch.compile already consumed part of it. V0 is more robust for multi-model.
TIL I've been thinking about LLM scaling wrong.
I assumed more model instances = more throughput.
I didn't understand how much vLLM and PagedAttention improve batching. One instance can handle massive concurrency — the scheduler batches requests and manages KV cache dynamically.
@trikcode Hi ! AI engineer for some years now and was always passive in social media (read-only mode, no comments no posts) but decided lately I'll be more active and sharing stuff... don't hesitate to connect 🤓
With Orchestra, secure on-prem AI scalability can finally feel as simple as cloud APIs — but without the data trade-off.
Built with 🧠 FastAPI, asyncio, vLLM, CUDA, Hugging Face.
#AI#MLOps#GPU#DeepLearning#FastAPI#OpenSource#vLLM
🎼 Introducing Orchestra v1.0 — a distributed AI orchestration system for secure, scalable inference.
Built for teams who want to deploy more models on limited GPUs without relying on external APIs.
🔗 https://t.co/NLDZhDYWvC
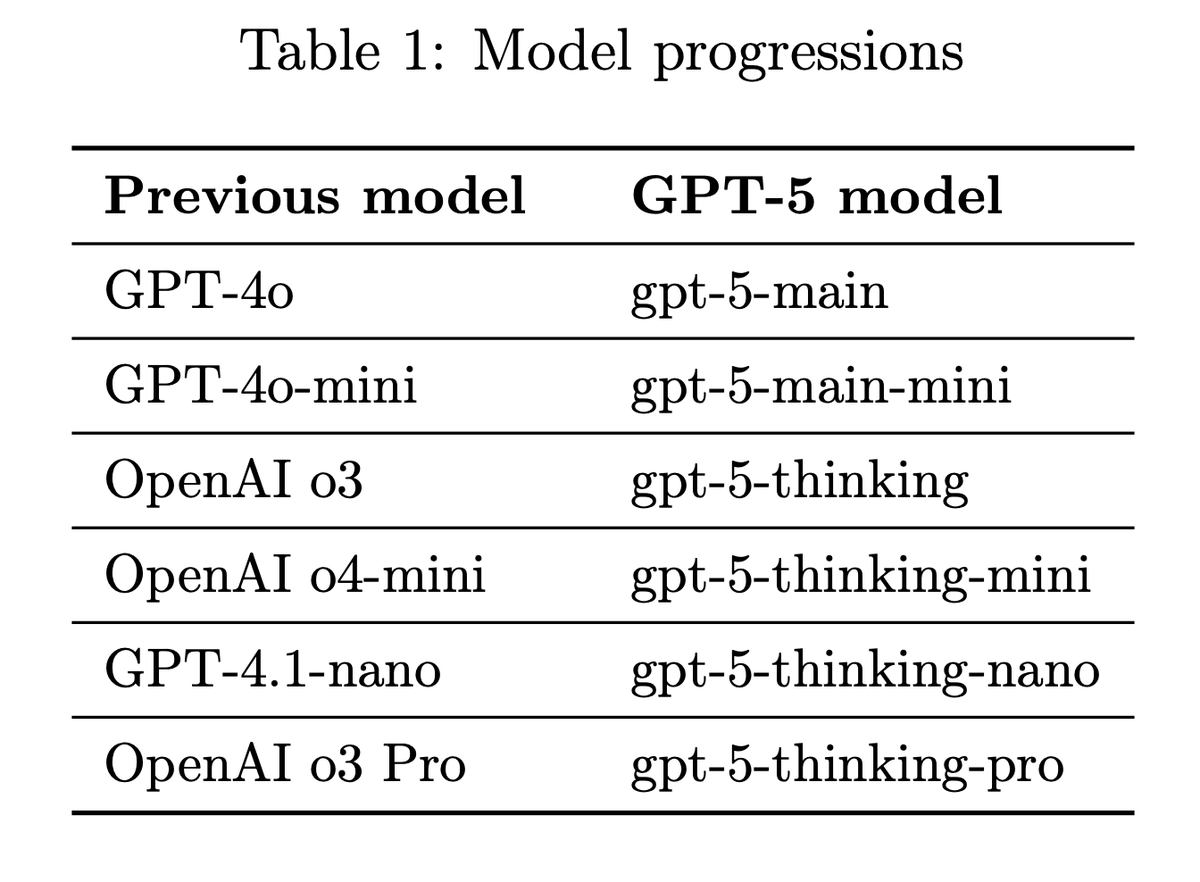
Reading the GPT-5 system card, it seems much of the backlash is really about the naming and the fact most models are api-dev-only. If “gpt-5-main” had launched as “GPT-5o” and “gpt-5-thinking” as “OpenAI o5,” the reaction might have been very different.
#UNITE3rd Giveaway Campaign Day 5
Chance to win Aeos Coins, Aeos Tickets or Holowear! 🎁
To participate:
1.Follow @PokemonUnite
2.Repost this post by July 23, 4:59 pm (PDT)
You will receive the result instantly!
Terms: https://t.co/Eu7kpenwBh
#PokemonUNITE