ViDoRe V3 has been accepted to ACL 2026! Much more relevant however are the many practitioners I met in recent days that praised the benchmark for it's quality and clean signal. It's not easy making a good retrieval benchmark (non-saturated, practical, wide domain coverage) but it helps having done 2 imperfect earlier iterations, understanding what is needed, and having 12k hours of human annotation (thanks @NVIDIAAI ) + 6 months of hard work from notably @MaceQuent1@antonio_loison@antoine_edy) amongst others.
From a scientific perspective, I believe we converged to a nice recipe that scales but remains challenging by mixing careful taxonomy design (@omrani_bilel), synthetic pre-annotations, and humans in many parts of the loop. This is by no means a cheap project - and going forward, non-trivial benchmarks will probably be more and more expensive. Gone are the days where using a LLM to annotate data creates a sufficient proxy for model improvement (ViDoRe V1).
Some people asked me when ViDoRe V4 would be out. I would assume this should not come from us - we are reaching the limits of data annotation, what we need now are fully real queries and real documents from real users of VDR (and more generally IR) models. This comes with data privacy issues and is tough but I believe it should be the north star - too many datasets in IR are completely toy and optimizing them actually hurts the model.
In all cases, ViDoRe V3 has a lot more to offer than just VDR (agents, RAG, etc) and should have at least a few months of non-saturation ahead of it!
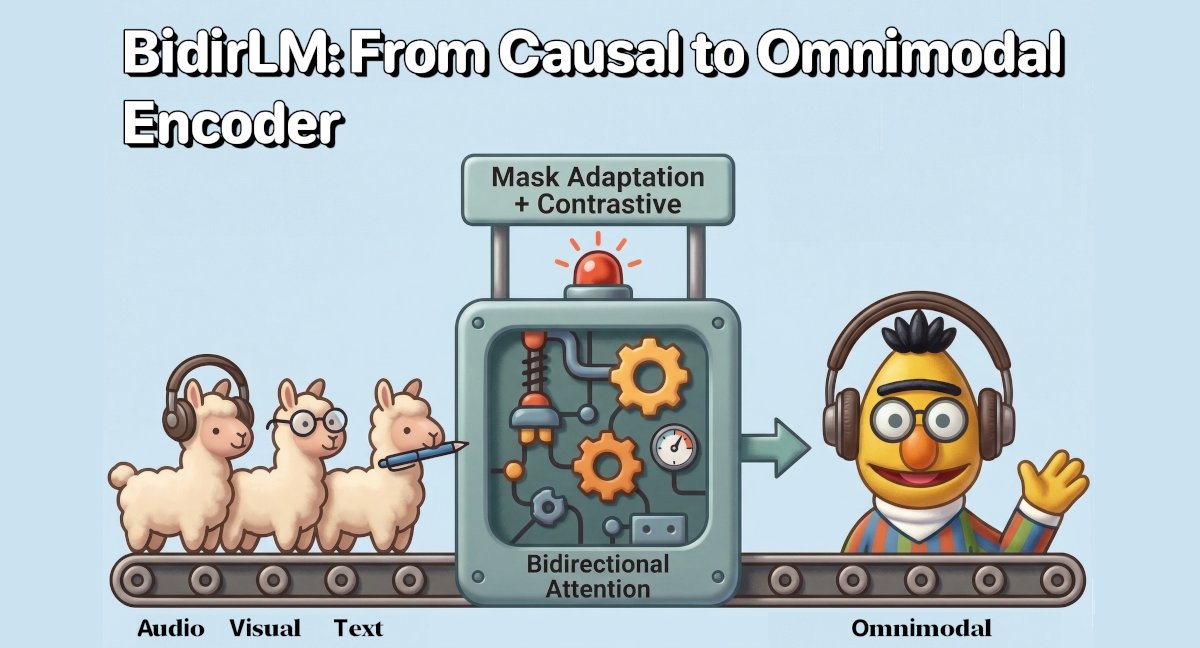
🚀 New model family release with an OMNIMODAL version !
After Eurobert, I'm excited to introduce BidirLM, a family of 5 frontier bidirectional encoders including an OMNIMODAL encoder at just 2.5B parameters.
🧵👇
https://t.co/AZzOJ6ZhhN
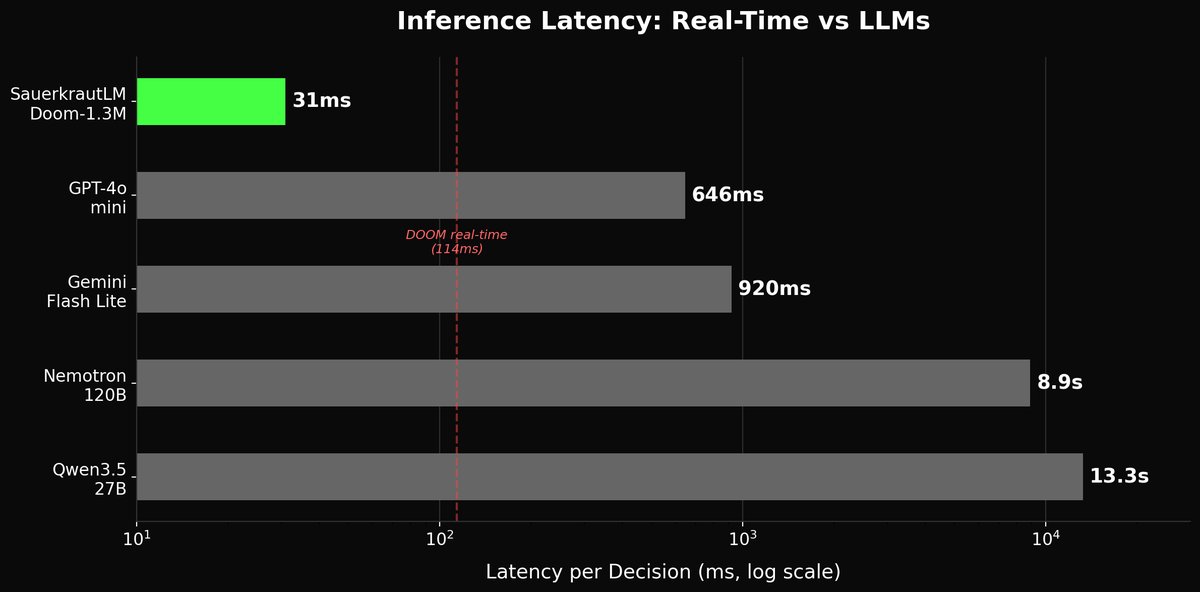
We taught a 1.3M parameter model to play DOOM. It outperforms LLMs up to 92,000x its size.
Happy Easter Monday! Here's our Easter egg release: SauerkrautLM-Doom-MultiVec-1.3M.
17.8 average points per episode.
We benchmarked our tiny model against GPT-4o-mini (via OpenAI API), Nemotron-120B, Qwen3.5-27B, and Gemini Flash Lite (via OpenRouter API) on VizDoom's defend_the_center:
- Our model: 17.8 avg points/episode, 31ms per decision, runs on CPU
- Gemini Flash Lite: 0.8 avg points/episode (920ms latency)
- Qwen3.5-27B: 0.67 avg points/episode (13.3s latency)
- Nemotron-120B: 0.6 avg points/episode (8.9s latency)
- GPT-4o-mini: 0.0 avg points/episode (just dodges, never engages)
The architecture: ModernBERT-Hash
We took hash embeddings (Svenstrup et al. 2017), previously only applied to the original BERT architecture (see @neumll 's BERT-Hash models), and brought them to ModernBERT, adding rotary position embeddings, alternating local/global attention, Flash Attention 2 support, and learned depth embeddings from VizDoom's depth buffer.
The result is a 5-layer encoder with a 75-token character-level tokenizer (no BPE, every ASCII character is one token, preserving spatial structure), attention pooling, and a 4-action classification head. Total: 1,319,300 parameters, ~5MB on disk, 31ms inference on CPU.
Trained on 31K frames of a human playing DOOM for about 2 hours. That's it.
Fully open source. Everything you need to reproduce this:
Model weights: https://t.co/bBvtlYFq2l
Training data (31K frames): https://t.co/AyEXw4mwbp
Code, training scripts, benchmark framework: https://t.co/GmPnTbQgAL
Full paper with methodology included in the repo.
Why does this matter beyond the fun factor?
Small specialized models can decisively beat general-purpose LLMs at real-time control tasks. Not by a small margin, by 22x on average points per episode. At 1/400th the latency. On a CPU. For free.
This has real implications for robotics, autonomous systems, game AI, and any domain where you need sub-100ms decisions on edge hardware. The future of AI isn't exclusively large. It's appropriately sized.
Thank you to my co-authors Daryoush Vaziri (University of Applied Sciences Bonn-Rhein-Sieg) and Alexander Marquardt (Nara Institute of Science and Technology, CARE Laboratory) for their contributions to this work.
Built with VizDoom, PyTorch, HuggingFace Transformers, and the ModernBERT architecture by @benjamin_warner , @antoine_chaffin, @ClavierBenjamin et al. Hash embedding approach inspired by NeuML's BERT-Hash models.
#AI #DOOM #GameAI #SmallModels #OpenSource #ModernBERT #SauerkrautLM #VAGOSolutions #Easter #TinyML
Meet SauerkrautLM-Translator-LFM2.5-1.2B: a lean, multilingual translation powerhouse. It's not just another language model. It's a specialized translator trained with DPO for high-quality, nuanced text conversion. This is exciting for devs who need fast, accurate translation without massive compute.
@maximelabonne Given the rapid development in the field of AI, our jobs are therefore "safe" for the next 3-6 months. Until the scale reaches saturation. Then, what felt like a moat will become a metric 😁
Proud to present you our new benchmark.
LaptencyBench (VagoKart GP)
LaptencyBench is a 13-minute closed-track evaluation where each “model” is deployed into a human driver and scored on best single-lap time (lower is better).
Secondary signals: laps completed (throughput) and gap to SOTA (delta vs. the fastest lap).
SOTA: Senior GLiNER set the pace with a 1:04.149.
Golchin Hallo delivered the best throughput (10 laps) and landed P2 at 1:05.378 (+1.229s).
Dr. D. held P3 with 1:06.404 (+2.255s). After that, the field entered the “regression zone” with sizable deltas.
SauerkrautLM-ColPali v0.1 — Multilingual Multi-Vector Vision Retrievers for Visual Document Retrieval
We’re releasing SauerkrautLM-ColPali, a family of late-interaction, multi-vector vision retrievers for Visual Document Retrieval (VDR) — searching PDFs/scans/screenshots directly in the visual space.
What we built:
Our codebase is a fork/extension of the ColPali engine and provides implementations + processors for multiple VLM backbones: ColQwen3 (1.7B Turbo / 2B / 4B / 8B), ColLFM2 (~450M), and ColMinistral3. The suite targets compact 128-dim embeddings for efficient indexing at scale, and supports EN/DE/FR/ES/IT/PT.
ViDoRe Benchmark (128-dim) highlights:
• ColQwen3-8B: v1 = 91.08 (#1), v3 = 58.55 (#1)
• ColQwen3-2B: v1 = 90.24 (best 1–3B class)
• ColLFM2-450M: v1 = 83.56 (best <1B class)
• ColQwen3-1.7B Turbo: v1 = 88.89 despite heavy compression
Hard parts (and what we learned):
Dataset reality for “complex” VDR (ViDoRe v1/v2/v3)
Public VDR datasets are a strong baseline (ColPali training data, VisRAG retrieval, multilingual VDR data). But pushing performance on visually complex, real-world docs required two new in-house multilingual datasets focused on tougher layout/visual grounding.
Porting LiquidAI/LFM2-VL-450M into a late-interaction multi-vector retriever:
LFM2-VL-450M is lightweight and originally English-centric. Multilingual training was not plug-and-play: naïvely mixing all multilingual data often stalled around loss ≈ 0.69 (≈ ln(2)). In many binary/pairwise contrastive setups, ln(2) indicates a “50/50 collapse” (no separation between positives/negatives). We fixed this with curriculum learning + staged training: trained an English-strong and a multilingual variant, merged them, then blended in a small-weight mMARCO multilingual retrieval specialist (EN/DE/IT/FR/ES) to further boost multilingual retrieval and downstream VDR behavior.
“Turbo” pruning without breaking the model (ColQwen3-1.7B-Turbo):
Based on Qwen3-VL-2B-Instruct, we removed 6 layers and reduced intermediate size (≈ -23% params). To avoid incoherent behavior, we ran a recovery (“healing”) phase: more mMARCO epochs first, then the 2B training recipe. Result: despite >20% reduction, Turbo is only slightly behind our 2B on ViDoRe v1.
Links:
GitHub: https://t.co/p6S3peZevm
HF collection: https://t.co/v2RD132po2
Demo (with heatmaps): https://t.co/m3G7oADjjG
A more detailed technical report will follow shortly.
If you work on RAG over visually rich PDFs or multilingual enterprise documents, we’d love to hear what you’re building.
Thanks to @liquidai ,@Alibaba_Qwen and @ManuelFaysse , @sibille_hugues and the rest of the ColPali-Team
yes it is actually build on the top of https://t.co/9214dcbTY6
Indeed it would be interesting to use the lfm colbert variant as a base or even merge into the text decoder of the lfm2-vl-450M. We actually did something similar here training the vl model with text retrieval data first and use this text specialist as a "submodel" for merging.
@SebastianB929 I did not test different speakers. But in general the new version feels more "natural". The old version was a bit to emotional with the default settings imo.
We live and breathe #OpenSource.
And we are committed to a #SovereignEurope 🇪🇺.
With our new #SauerkrautLM-GliNER Release.
Modelcard on Huggingface: https://t.co/6gViX6dZ48
Test the Model yourself in our Demo Space on Hugging Face 👉https://t.co/ocj7YDaGNr
Why this model release matters for Europe’s Sovereinty:
💠 Sovereign enterprise AI depends on high-quality data and efficient AI-supported workflows — otherwise you risk an expensive “garbage in, garbage out” loop.
💠 True data quality goes far beyond vectorization: it requires breaking information down into entities and relations, often structured as graphs.
💠 Standard LLMs aren’t suitable for this — they’re too costly and too generic.
💠 Classic #NER models can extract entities, but only perform well with domain-specific training.
💠 This means every domain needs its own NER model — repetitive, resource-intensive, and hard to scale.
💠 GliNER models solve this by acting as generalist NER systems.
💠 SauerkrautLM-GliNER is our strongest multilingual model yet — outperforming GliNER_multi-v2.1 and GliNER_multi_pii-v1. Trained on five European languages (DE 🇩🇪 , IT 🇮🇹 , EN 🏴 , FR 🇫🇷 , ES 🇪🇸 ), it delivers exceptional multilingual, #crossDomain entity extraction.
Big thanks to our colleague Michele Montebovi for leading and delivering the training!