Today we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
@KyrieBlunders Did you use the custom C++ & Cuda registration or Triton wrapping to make the custom kernel compile compatible?
https://t.co/GanbaRFVRi
@johnowhitaker Perhaps. Unlike banking, every coding proactivity increase so far: punch cards to assembly, compilers, IDEs, etc has led to an increased demand for programmers.
Not to degrade from this work, but TurboQuant is not a competitive method nor a good benchmark. Researcher -- including me -- cannot replicate the TurboQuant paper, and even then, the performance is not great. Please. Just. Stop.
@latkins Trinity Large has quite different recommended generation settings across Hugging Face/Arcee docs:
HF model card: temperature=0.45–0.6
HF generation config: temperature=0.8
Website docs: temperature=0.3
For evaluation, which settings should we be using?
My concern for the AI era, or at least this phase of it, is that a generation is being taught that "close enough" is just fine.
Take @AnthropicAI for example. Text wrapping in Claude Code has been broken for weeks. Superfluous spaces appear on the left edge. One engineer to another: you know its an out by one error.
I refused to believe that nobody has noticed this. The shtick they are selling is that AI can fix this kind of thing. Either they tried to prompt a fix, and Claude ain't good enough to fix an out-by-one error. Or they haven't attempted it because it is "close enough".
It can't be the case that AI is only good enough if we lower our standards. It can't.
I'm well aware I have both feet firmly planted in my "grumpy old man" phase of life...
IBM Granite just released two multilingual embedding models with 97M and 311M parameters 🤏🏻
ModernBERT-based, 200+ languages, 32K context, and built for retrieval, search, similarity, and code.
And... day-zero support on Text Embeddings Inference and friends!
A 90% confidence interval of 0.3-3x size would imply GPT 5.5 is anywhere from ~3 trillion parameters to ~27T. The latter is obviously not true, so this size estimation method doesn't seem useful.
Closed labs hide model sizes. They can't hide what their models know, and what a model knows is an indicator on how big it is.
Reasoning compresses. Factual knowledge doesn't. So you can size a frontier model from black-box API calls alone, and across releases you can literally watch a single fact arrive in the parameters over time.
For three years, my friends Jiyan He and Zihan Zheng have been asking frontier LLMs the same question: "what do you know about USTC Hackergame?", a CTF contest. May 2024: GPT-4o invented fake titles. Feb 2025: Claude 3.7 Sonnet listed 19 verified 2023 challenges. By April 2026, frontier models recall specific challenges across consecutive years.
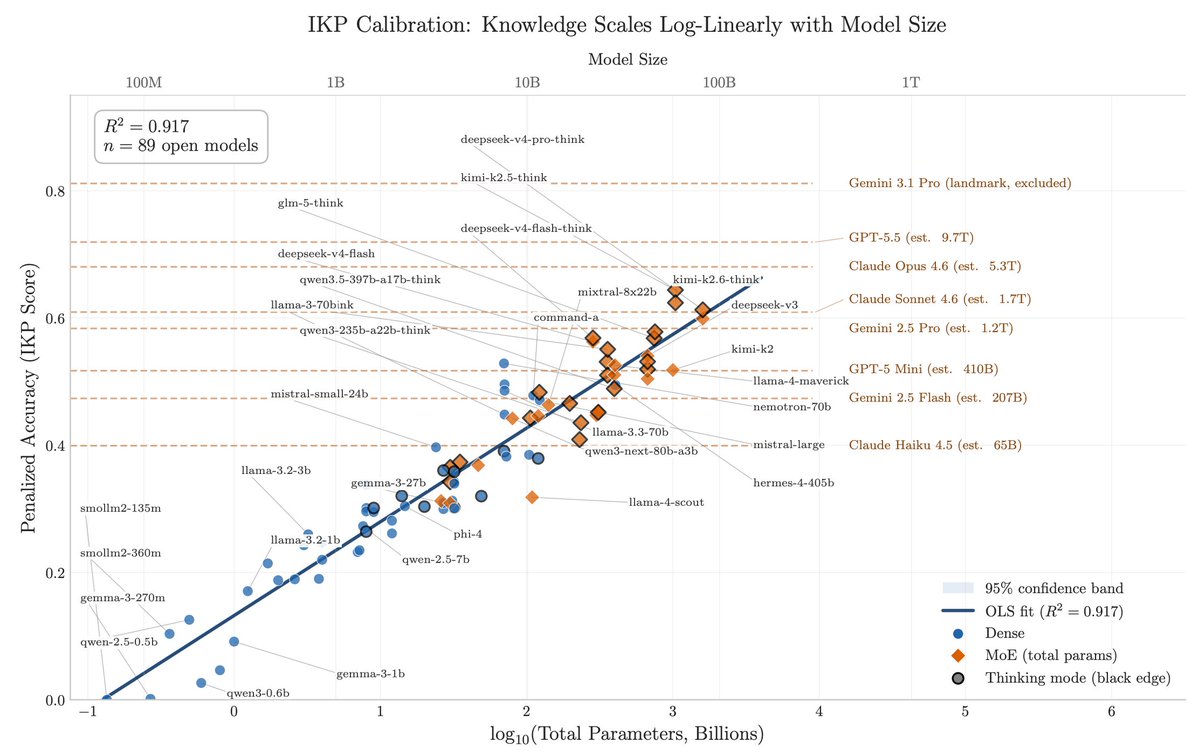
After DeepSeek-V4 dropped, I instructed my agent to spend four days autonomously turning that habit into Incompressible Knowledge Probes (IKP) — 1,400 questions, 7 tiers of obscurity, 188 models, 27 vendors. Three findings:
1/ You can approximately size any black-box LLM from factual accuracy alone. Penalized accuracy is log-linear in log(params), R² = 0.917 on 89 open-weight models from 135M to 1.6T params. Project closed APIs onto the curve → GPT-5.5 ~9T, Claude Opus 4.7 ~4T, GPT-5.4 ~2.2T, Claude Sonnet 4.6 ~1.7T, Gemini 2.5 Pro ~1.2T (90% CI: 0.3-3x size).
2/ Citation count and h-index don't predict whether a frontier model recognizes a researcher. Two researchers with similar citation profiles get very different responses. Models memorize impact — work that shaped a field, not many incremental papers.
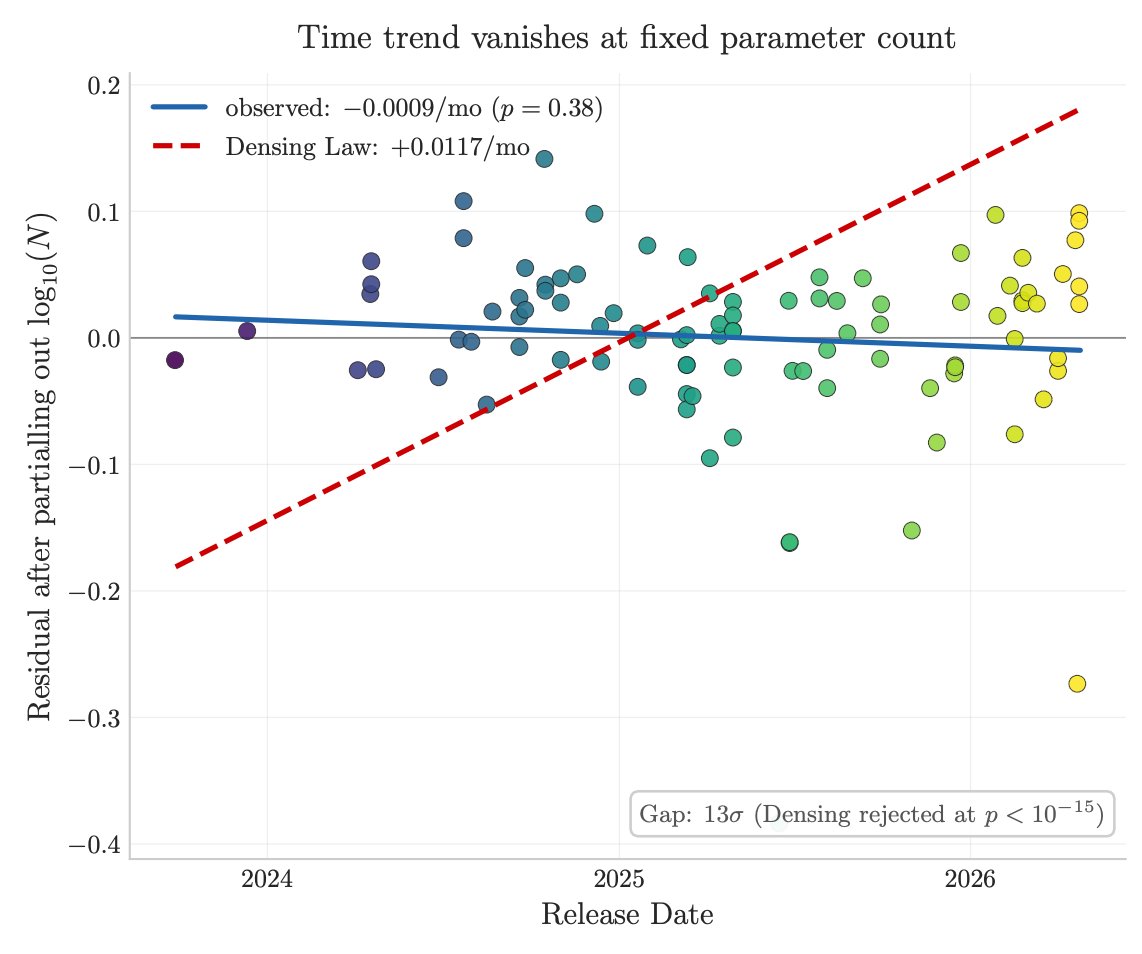
3/ Factual capacity doesn't compress over time. Across 96 open-weight models across 3 years, the IKP time coefficient is statistically zero, rejecting the Densing-Law prediction of +0.0117/month at p<10⁻¹⁵. Reasoning benchmarks saturate; factual capacity keeps scaling with parameters.
Website: https://t.co/CkwJsXqnsX
Paper: https://t.co/eNUdC9ye7w
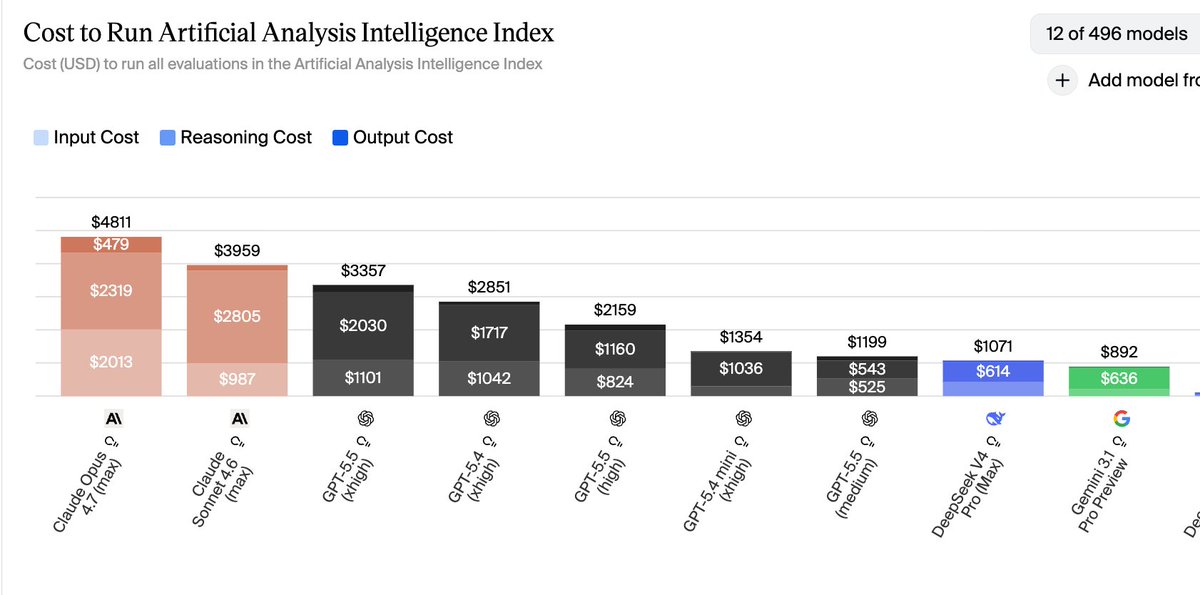
Despite the price increase, GPT-5.5 (xhigh) still came out cheaper than Sonnet on the Artificial Analysis Index.
It's more expensive than 5.4, but barely. Also check those 5.5 (medium) numbers, they're closer to a mini model with 5.4-xhigh-level performance