Bill Staples runs GitLab, the platform roughly 30 million developers use to ship software. His 14-tweet thread on "GitLab Act 2" is the most honest layoff-and-AI-pivot announcement any public CEO has made yet. The line worth screenshotting: "Authoring code by hand may be going away."
A sitting CEO. Saying it on Twitter. With his face on it.
The pattern this fits into:
- Meta cut 21,000 in 2023, then committed $35-40B to AI infrastructure for 2024.
- Salesforce cut 7,000, then launched Agentforce at roughly $2 per conversation.
- Amazon cut 27,000 since 2022, then committed $100B+ to AI infrastructure for 2025.
- Microsoft cut 6,000 in May 2025, then crossed $13B in annualized AI revenue.
The math is consistent. Every dollar saved on payroll funds a GPU, a model contract, or an agent platform. These companies are running a swap: workforce that built version 1, out. Compute layer for version 2, in.
What makes this thread different is the transparency. Old playbook: hide layoffs in 8-K filings, blame "macro headwinds," never mention AI replacement. New playbook: announce both publicly, frame it as opportunity, post the explanation on Twitter. The CEOs who say it out loud first set the script everyone else has to follow.
Read tweet 8 carefully. "We intend for the majority of work to be done by agents." That is a public commitment, in writing, from the CEO of a 30 million developer platform. To his own investors. The same day GitLab opened a voluntary separation window across its 2,580 employees with no number specified, leaving the entire company in limbo until June 1.
This script is about to run through every white-collar industry. Legal, accounting, design, marketing, customer service, support. GitLab is choreographing it openly because the playbook needs a public test case. The cover story will be "your work gets more valuable." The math will be fewer roles, paid more, managing agents.
Watch the thread structure. Layoff in tweet 2. AI bet in tweet 5. Customer reassurance in tweet 6. Investor pitch in tweet 8. Operating principles in tweet 9. That sequence becomes a template by year-end. Save the screenshot.
Anthropic is running a masterclass in negotiation-as-marketing right now.
The $200M Pentagon contract represents 1.4% of Anthropic’s $14 billion run rate, up 14x from $1 billion fourteen months ago. This is not a number worth compromising a brand over. Amodei knows this. The Pentagon knows this. So why is he personally publishing a detailed statement, point by point, timed for maximum news cycle impact?
Because every headline that reads “AI company refuses Pentagon’s demands on autonomous weapons and mass surveillance” is worth more than the contract. Anthropic just bought the most expensive brand positioning in AI history, and the Pentagon is paying for it.
The statement is surgically written. Amodei opens by affirming he believes in using AI to defend democracies. Lists every classified deployment Anthropic pioneered. Emphasizes they’ve never objected to specific military operations. Then draws two narrow lines: no mass surveillance of Americans, no fully autonomous weapons. The framing makes it almost impossible to argue against without sounding like you’re pro-surveillance.
The Pentagon’s negotiator called Amodei a “liar” with a “God complex.” The Pentagon threatened to invoke the Defense Production Act and label Anthropic a supply chain risk simultaneously. Amodei pointed out those two threats are contradictory: one says Anthropic is dangerous, the other says Claude is essential. That line will be in every news story for the next 48 hours. It was designed to be.
Sen. Tillis, a Republican not seeking reelection, broke with the administration on the record. Said the Pentagon was being “unprofessional” and that you should listen when a company turns down money out of concern for consequences. Anthropic didn’t have to lobby for that. The positioning did the work.
Every enterprise buyer evaluating AI vendors just watched Anthropic publicly refuse to let a customer override their safety commitments. For a company selling to regulated industries, that demo is priceless.
The 5:01pm Friday deadline is tomorrow. Anthropic will either keep the contract with safeguards intact or lose it and gain something more valuable: permanent differentiation in a market where every other lab said yes.
One of the biggest red flags for me when I am pitched is when the entrepreneur talks about how he (or we) are going to make money. Or they talk about exits. Or they talk about how a competitor is worth $1 billion. None of that matters. A startup is a mission. A great entrepreneur is a missionary. Not a mercenary.
A great irony of entrepreneurship: The entrepreneurs who come in and say they're going to make everybody money, don't.
People who say that they're going to paint a picture of the world that's never been seen before often are the ones who make a fortune.
When entrepreneurs leave their cushy Facebook or Google jobs, some of them can't stop looking back. That is a bad sign to me.
If the entrepreneur ever says, I could be making $XYZ at Google, I am concerned that they've got one foot in and one foot out and won't make it as a founder.
The same can be said for founders who are building a company for the resume versus the mission.
There's been an influx of Ivy League MBAs who believe that starting a venture-backed company is the next logical career move.
I'd much rather invest in someone who has found a problem and believes with every fiber of their being, and knows deep in their bones, that they're the one who is destined to find the solution.
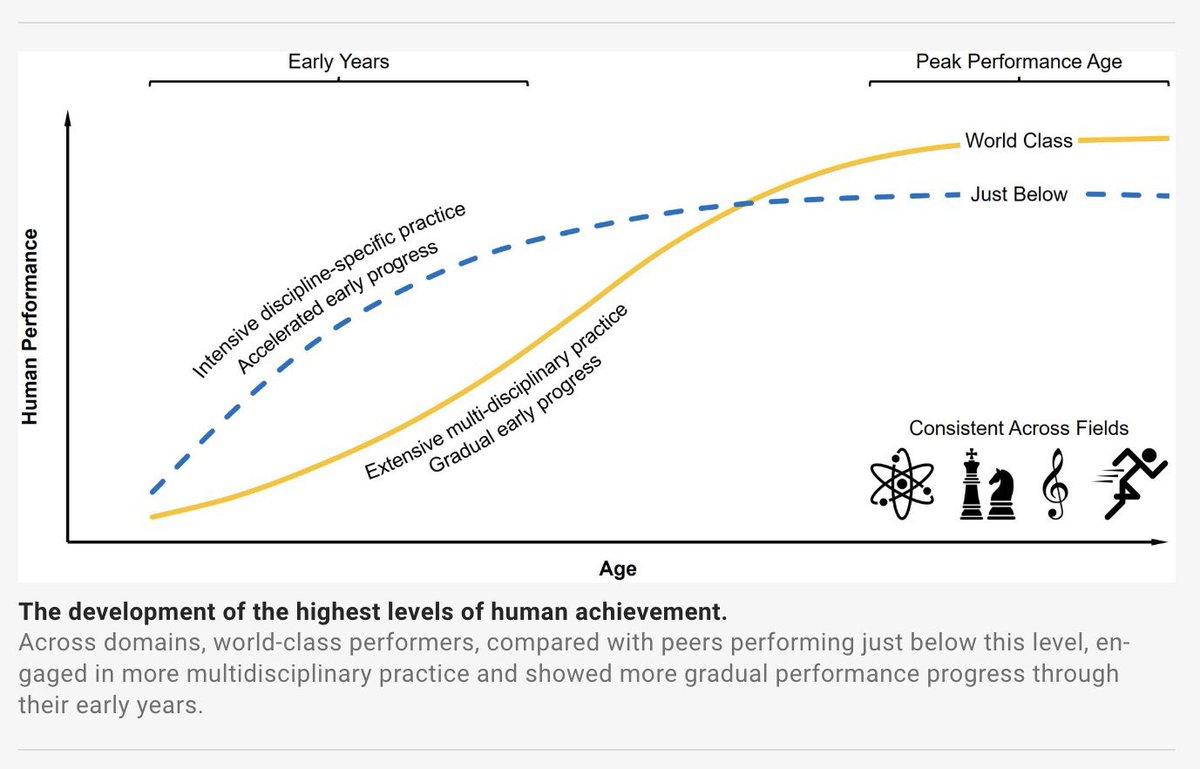
Fascinating paper just published in Science.
The authors analyze the career trajectories of top performers across multiple domains, including Nobel laureates, elite chess players, Olympic gold medalists, and more.
Their central finding challenges a common belief.
Intensive, single-discipline training at a young age does confer an early advantage, but this advantage fades over time.
By contrast, individuals exposed to multidisciplinary practice early in life tend to start more slowly. Yet, over the long run, they are more likely to reach world-class performance, eventually overtaking early specialists, who often plateau just below the very top.
An important reminder that breadth early on can be a powerful investment in long-term excellence.
Link to the paper in the first reply.
A Category 4/5 atmospheric river is about to hit the Pacific Northwest, bringing extremely high snow levels.
However, on Mount Rainier at 14,000 feet, it will be all snow, with over 110 inches expected to fall by Friday.
Everyone’s debating if AI is a bubble. Nobody’s asking what happens when three 50-year platform shifts hit at once.
Jensen just walked through why the bubble question misses the entire picture.
First shift: CPU to GPU accelerated computing. Moore’s Law is dead. The world has hundreds of billions in annual compute spend running on CPUs. Those workloads are now moving to CUDA GPUs. Data processing, science simulations, engineering applications that ran exclusively on CPUs for decades are shifting to accelerated computing. This happened already in gaming. Now it’s hitting enterprise infrastructure.
Second shift: Classical machine learning to generative AI. Meta reported 5%+ conversion gains on Instagram ads and 3%+ on Facebook Feed just from switching to generative AI recommendation models. That’s not incremental revenue. That’s hundreds of millions in additional profit from the same traffic because the models work better. Every hyperscaler is racing through this transition because the math is obvious. Better models mean higher conversion rates mean more revenue per user.
Third shift: Generative AI to agentic AI. Cursor and Claude Code for coding. Harvey for legal. iDoc for radiology. Tesla FSD and Waymo for driving. These systems can reason, plan, and use tools. OpenAI, Anthropic, xAI, and Google are building the foundation. Then you have Lovable, Replit, Cognition AI creating applications on top. This wave creates entirely new product categories.
The infrastructure demand looks identical from the outside. All three shifts require GPUs. But the use cases are completely different. One is replacing legacy compute. Another is upgrading existing AI. The third is enabling applications that didn’t exist before.
NVIDIA sits at the center of all three because CUDA works across every transition. One architecture for accelerated computing, generative AI, and agentic systems. One platform for cloud, enterprise, and edge. That’s why they can charge premium prices while demand keeps accelerating.
The bubble question assumes one use case with speculative demand. Jensen just showed you three separate platform transitions with different drivers and timelines. The first is necessary in a post-Moore’s Law world. The second transforms existing business models with measurable ROI. The third creates entirely new markets.
Each shift alone would drive infrastructure growth for years. All three happening simultaneously means the demand isn’t speculative. It’s structural.
All the analysts forever writing about OpenAI vs Anthropic vs Google are missing the real story that already happened.
80% of startups pitching Andreessen Horowitz are running on Chinese open-source models. Not OpenAI. Not Anthropic. Chinese models like DeepSeek that cost 214x less per token.
The math here breaks everything. DeepSeek trained its model for $5 million. OpenAI spent $500 million per six-month training cycle for GPT-5. That gap translates directly to API pricing where startups pay $0.14 per million tokens versus $30 for GPT-4.
For a startup burning through 100 million tokens monthly, that’s $1,400 versus $300,000. The difference between 18 months of runway and 3 months.
This tells you the real constraint in AI was never capability. Chinese models are matching GPT-4 on coding benchmarks while costing 2% as much. The constraint was always burn rate, and China solved it first by optimizing for efficiency instead of chasing AGI.
The second-order effect gets interesting. When your infrastructure costs drop 98%, you can actually afford to fine-tune models for your specific use case. American startups paying OpenAI’s API rates are stuck with generic models. Chinese open-source users are building specialized variants.
Silicon Valley thought the moat was model quality. Turns out the moat was cost structure, and they built it backwards. When a16z partner Anjney Midha says “it’s really China’s game right now” in open-source, he’s not talking about benchmarks. He’s talking about who controls the default foundation layer.
Now look at where this goes. American AI labs are optimizing for AGI and superintelligence. Raising billions to chase the theoretical ceiling. China optimized for distribution and adoption. Making AI cheap enough to become infrastructure.
All 16 top-ranked open-source models are Chinese. DeepSeek, Qwen, Yi. The models actually being deployed at scale. While OpenAI charges premium rates for exclusive access, Chinese labs are flooding the zone with free alternatives that work.
The third-order cascade is what changes everything. Every startup that survives the next funding winter will have optimized around Chinese open-source as default infrastructure. Not as a China strategy. As a survival strategy.
That 80% number at a16z only goes one direction. When you’re a seed-stage founder choosing between 18 months of runway or 3 months, economics beats nationalism every time.
America is still competing to build the best model. China already won the race to build the one everyone uses.
Nearly 100 yrs old and still one of the most relevant business books I’ve ever read.
In just two paragraphs he lays out over a dozen timeless principles:
1. Fewer, better people. & keep them for a long time.
2. Great craftsmen (ICs) are rarely great managers.
3. CEOs need to know how their products are made. CEOs need to know the details. Don’t outsource this.
4. Leaders need to get out of the board rooms and on the factory floor (or customer meetings, etc.) If your team is not used to seeing you “on the factory floor”, you’re not there enough.
5. Working managers only. No middle managers who don’t know how to do the work.
- Non-operational middle managers don’t have the respect of the team.
- They also can’t judge quality.
- They also can’t gauge realistic timeframes for work.
6. Salary alone won’t attract or retain great ppl. The mission, the FIGHT, is what attracts great ppl.
7. Get to know your team as people. What happens in their lives matters.
8. Be vigilant with indirect expenses that are not related to product building. This is an easy way companies bloat spent.
9. “An office is essentially a place in which to work. It is not a club and it ought not to be fitted up as a club—else it may turn into a club.”
10. No company always has “good times”. When bad times inevitably hit, you’d rather have cash than the fancy office.
And every page in the book is like this so far. 🤯
(From Harvey Firestone’s autobiography: “Men and Rubber”)
This is the craziest stat of the World Series:
Trey Yesavage, the Blue Jays starting pitcher who makes $57K a year, started the game by striking out Shohei Ohtani, who makes $47M - that's 824x his salary.
The AWS outage is a reminder that many apps aren't truly architected for redundancy. The tools are all there, its just that true HA is more expensive to achieve than most are willing to pay.
Modern stateless apps -- sure. But stateful apps using stored data...tougher.
The GitHub MCP Registry just landed 🙌
Whether you’re building with GitHub Copilot, agents, or any AI tool that speaks MCP, this is the place to find what you need. https://t.co/wvpsVyRurP
When AI systems cause security incidents, can you trace which user or prompt triggered the action? Static credentials make this nearly impossible. HashiCorp Vault's dynamic credentials give every AI agent unique, traceable identities with just enough access, for just enough time. https://t.co/CxA5LgUQvE