Why repetition works so well is still an open question. There's a lot to uncover about training dynamics of SFT, and we hope this is a useful data point.
Joint work with co-authors @Sagar_Vaze@TiRune@y_m_asano
Paper: https://t.co/Jkk1jVPFj5
Code: https://t.co/PoaYWUZbsq
🎉[openings] I’m hiring postdoctoral researchers to join our @FunAILab at UTN through the Alexander von Humboldt Research Fellowship (@AvHStiftung), via the Henriette Herz Scouting Programme.
As a Henriette Herz Scout, I can nominate outstanding international researchers for this fellowship route. I’m especially keen to hear from candidates working on multimodal learning, video and image pretraining, and post-training.
Fellows would be hosted in our lab at UTN and work closely with us on these topics.
Key requirements:
* finished your doctoral studies less than 4 years ago or will finish in the next 6 months
* did not live/work in Germany in the last 10 years
* applications from female, trans* and/or non-binary candidates are highly encouraged!
Interested? Please send a short note with your CV, PhD year, current affiliation, 2–3 key publications, and a few lines on how your work connects.
Please share! 🔀
@ChinmayKak actually something similar was observed by @AlexGDimakis when working on OpenThoughts dataset;
sampling multiple trajectories for the same prompt, instead of drawing more unique prompts led to better results
https://t.co/q85EmybXSI
The multiple answers mystery is the most surprising thing we stumbled on from OpenThoughts:
Sampling multiple answers for the same question is better than having more questions, each answered once.
To explain: Say you are creating a dataset of questions and answers to SFT a reasoning llm.
You can take 1000 questions (eg from stackexchange) and answer them with deepseekR1.
Or you can take 500 questions (from the same distribution) and answer each question *twice* independently with deepseekR1.
Which one is a better dataset? Surprisingly, if you re-answer the same questions , it’s a better dataset for distillation (at the same size) and this was a robust finding from OpenThoughts across models and data sources.
We have no theoretical understanding why, and no way to predict how many times to repeat. Clearly it must stop at some point (take one question and answer it 1000 times won’t be a good SFT dataset) but we don’t know how to predict this, beyond empirically trying.
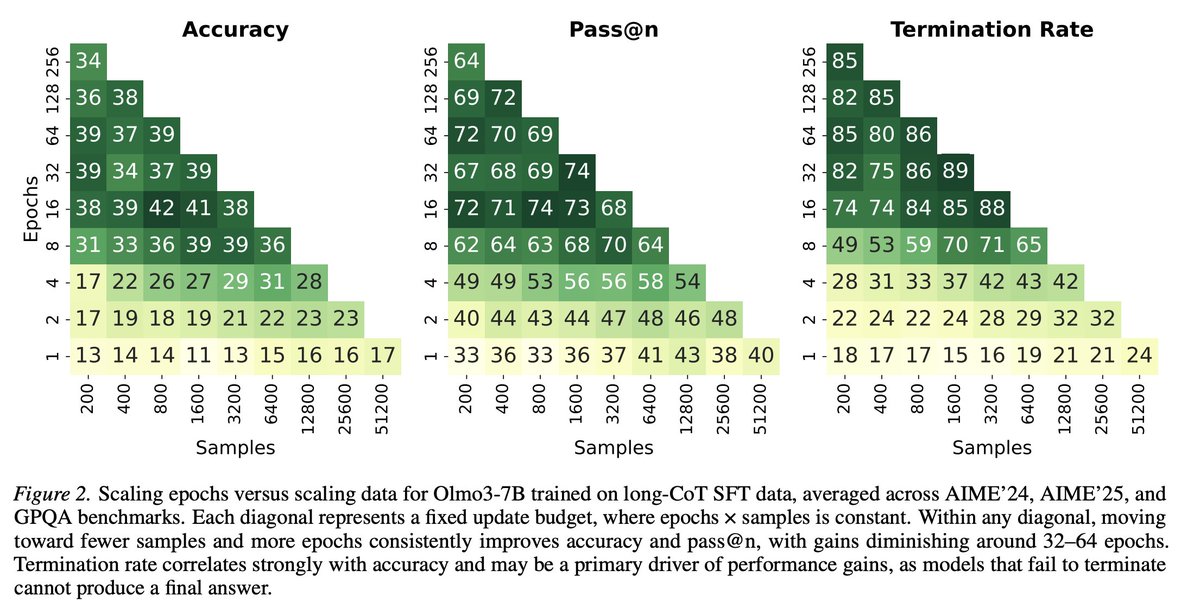
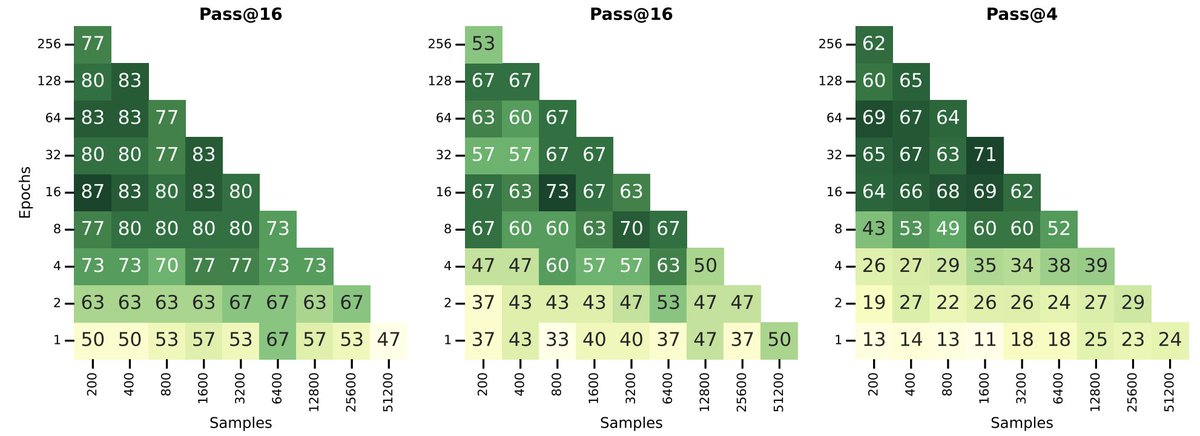
Common knowledge in ML: more unique training data → better generalization. Turns out this doesn't hold for long-CoT SFT.
Under a fixed update budget, repeating a small dataset multiple times beats training on more unique samples. And it's not even close.
@ChinmayKak@Sagar_Vaze@TiRune@y_m_asano there's this work on data-constrained pretraining (https://t.co/roNjmBIgpo), where they show that multiple epochs can substitute unique data *up to a few epochs*; while more epochs slows down convergence, at least measured by val loss
@ysu_ChatData total tokens seen during training is more or less the same within each update budget;
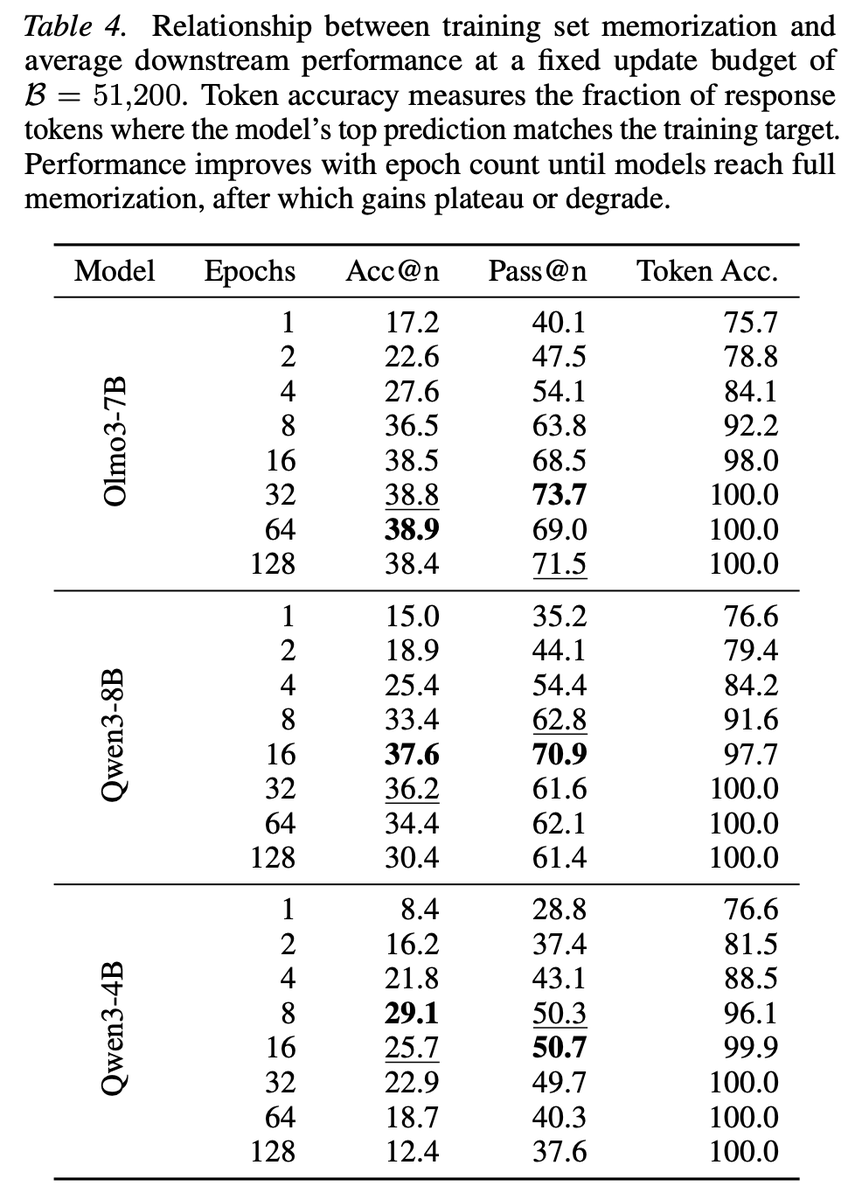
as we report in the paper -- there are "standard" overfitting signs like train set memorization and rising val loss, but the model generalizes well nevertheless
Common knowledge in ML: more unique training data → better generalization. Turns out this doesn't hold for long-CoT SFT.
Under a fixed update budget, repeating a small dataset multiple times beats training on more unique samples. And it's not even close.
(too late to edit, config matching mentioned results is: "16 epochs on a random subset of 3.2K* samples")
16 epochs on 400 samples yields:
83% -- AIME'24,
63% -- AIME'25,
66% -- GPQA.
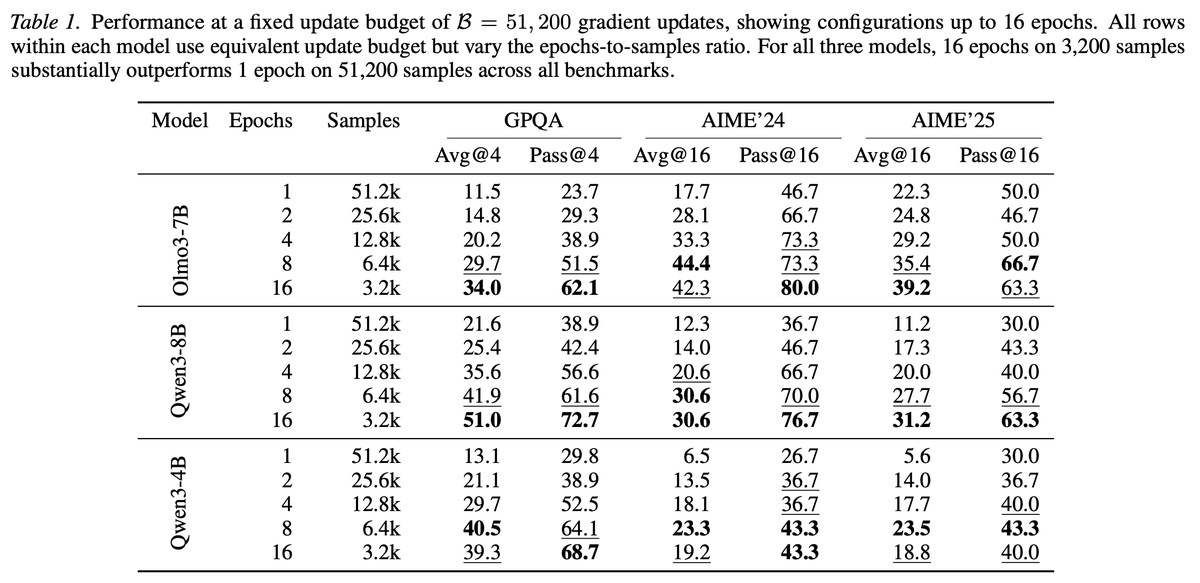
When training Olmo-3 7B on Dolci SFT dataset, 16 epochs on a random subset of 400 samples leads to:
80% (pass@16) on AIME'24,
63% on AIME'25,
62% on GPQA;
while one epoch on over 51K samples yields:
47% -- AIME'24,
50% -- AIME'25,
24% -- GPQA.
Why repetition works so well is still an open question. There's a lot to uncover about training dynamics of SFT, and we hope this is a useful data point.
Joint work with co-authors @Sagar_Vaze@TiRune@y_m_asano
Paper: https://t.co/Jkk1jVPFj5
Code: https://t.co/PoaYWUZbsq
So when does repetition stop helping?
Turns out token accuracy on training dataset is a pretty reliable signal for this. Once the model hits ~100% token accuracy on the training set, additional epochs don't bring further gains, which makes it a nice practical stopping criterion.
@DimitrisPapail there were *signs* that the phenomenon exists tho -- many tech reports mention multiple epochs in SFT stage, or eg. this paper (https://t.co/MhYwJ1kUkR) training for 15 epochs on 800 samples; but they focus on data quality, and do not ablate epochs
@DimitrisPapail yup, for 7-8B models and this dataset it seems optimal; but for example 4B model gets saturated around 4-8;
it's either implicitly due to smaller model, or explicitly due to larger optimal learning rate (3e-5 vs 2e-5 for 7-8B models)
@DimitrisPapail yeah, it looks like standard overfitting as val loss goes up, while train loss goes to 0 -- but the model generalizes well;
we can train on 200 generic conversation samples which demonstrate reasoning patterns, and the model starts solving ~40% of AIME'25 problems
















![y_m_asano's tweet photo. 🎉[openings] I’m hiring postdoctoral researchers to join our @FunAILab at UTN through the Alexander von Humboldt Research Fellowship (@AvHStiftung), via the Henriette Herz Scouting Programme.
As a Henriette Herz Scout, I can nominate outstanding international researchers for this fellowship route. I’m especially keen to hear from candidates working on multimodal learning, video and image pretraining, and post-training.
Fellows would be hosted in our lab at UTN and work closely with us on these topics.
Key requirements:
* finished your doctoral studies less than 4 years ago or will finish in the next 6 months
* did not live/work in Germany in the last 10 years
* applications from female, trans* and/or non-binary candidates are highly encouraged!
Interested? Please send a short note with your CV, PhD year, current affiliation, 2–3 key publications, and a few lines on how your work connects.
Please share! 🔀](https://pbs.twimg.com/media/HHKGfgWXoAA-4Ga.jpg)