Distribution analysis answers the questions that summary metrics can't. DBNL's distribution comparison can help you pinpoint the issue—this is especially helpful when evaluating experiment variants: https://t.co/C79vWuyH4F
AI agents are complicated, but catching and fixing issues with them is easy with DBNL. From pre-deployment evals that fail to perform in production to insights on user intent and more, DBNL helps teams identify issues faster: https://t.co/GjXx6QvpkL
When you sample traces, you’re making a bet that the interesting patterns are distributed randomly across your data. They’re usually not. Random sampling will systematically misses low-frequency, high-impact patterns.
Where does your organization fall on the observability maturity scale? Read and find out: https://t.co/N56UvnUOIw
Your P95 latency doubled after a deployment, but your average cost-per-call looks fine. Which one do you trust?
This is the core tension in LLM agent observability: summary metrics tell you something changed, but not what changed—or for whom. For example, a bimodal latency spike (where half your requests are fast and half are stuck) looks identical to a uniform slowdown when you compress it to a single number.
DBNL's distribution comparison unlocks the details. Here's how it works: https://t.co/LghliKFGoA
AI agent analytics insights and recommendations—automated. DBNL automatically turns logs into action items, helping you identify where your agents could use some tweaks. Learn more: https://t.co/QxRWvFH8Qt
Agent breaking in production? There are 3 types of issues that DBNL's analytics can help catch before they become a bigger problem:
1. Offline, pre-deployment evals that fail to perform out of sample in production
2. Insights on user topics, intent, and input patterns
3. Issues in the complexity of agent behavior
https://t.co/n63CC0aTeB
Are you missing key information about your AI agents? Here are the 3 failure modes that are invisible to aggregate metrics:
→ Behavioral drift by segment
→ Unknown-unknown behavioral patterns
→ Gradual degradation vs. hard failures
Take our quiz to see where you land, then learn how to close the gap with DBNL: https://t.co/9jyhbApWOF
Your evals are passing. Your agent is still failing.
This is one of the most underappreciated problems in production AI systems. Distributional CEO Scott Clark breaks it down in this episode of the @twimlai podcast with @samcharrington : https://t.co/YjjZcwtUEA
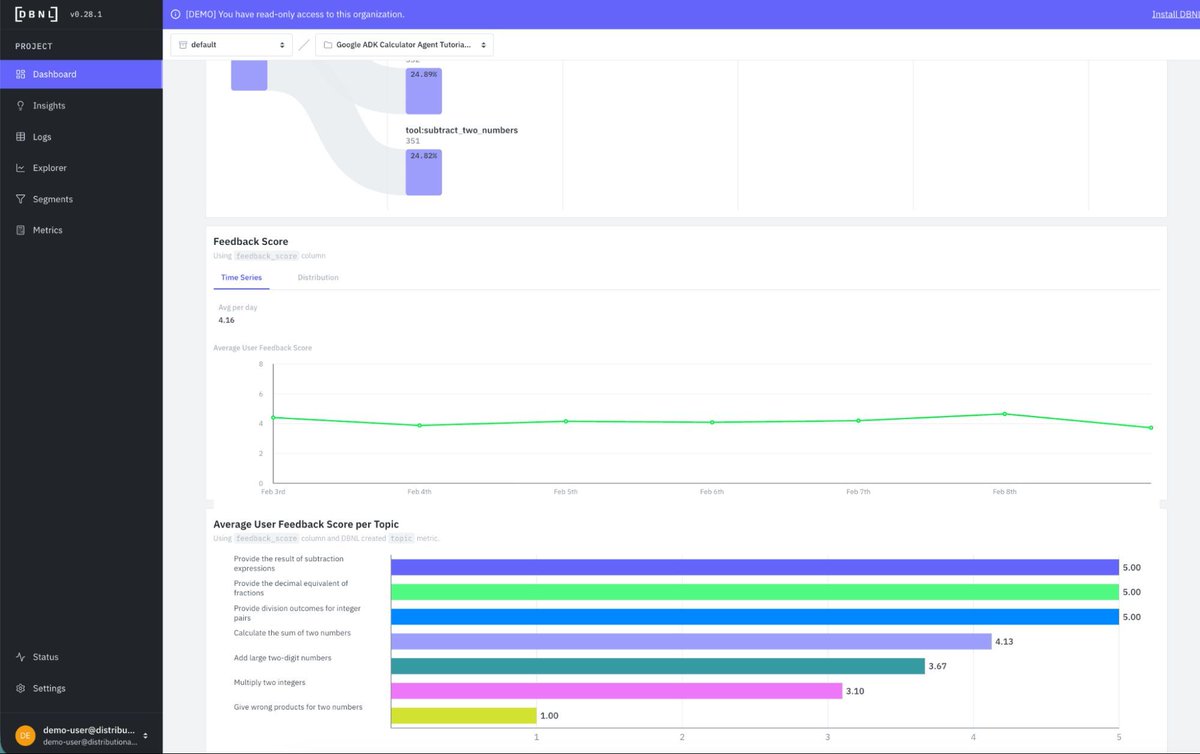
Get a quick picture of where your AI agent's behavior has gone off course. DBNL makes it easy to identify irrelevant ouput in your logs, which you can then use for offline prompt iteration, reinforcement learning, fine tuning, tool changes, or hyperparameter optimization. Here's how it works: https://t.co/rRULxku8YI
Most AI teams can see their aggregate metrics, but they can’t see the behavioral patterns inside them — which is where the real informations. Here's why most AI teams today are still "flying blind" when it comes to observability, and how to close the gap: https://t.co/i0ZPr4lCKc
Imagine a Maslow’s hierarchy of observability for your AI agents:
Telemetry = Logging what happens
Monitoring = Alerting on known signals
Online analytics = Surfacing the unknown unknowns
Where do you land? Learn how to get to the top in this episode of @twimlai: https://t.co/LxROV0FxiU
Great summary from @DrScottClark!
Building a deep understanding of agents to continuously improve them is the focus of @dbnlAI.
I love the part around 18:45 - 20:45. Rich analytics driving increasingly automated improvement flows seems like a pattern that will harden in the near term.
After working with AI teams across the industry, we’ve identified four distinct stages of observability maturity. Here’s what each one looks like — and where the transitions break down: https://t.co/CHlcyAE39m
We're on @twimlai with @samcharrington! Catch Scott Clark as he share how teams can reliably operate and improve complex LLM systems in production and discusses the Maslow’s hierarchy of observability for your AI agents: https://t.co/YjjZcwtmP2
In this episode, @DrScottClark, co-founder and CEO of @dbnlAI, joins us to explore how teams can reliably operate and improve complex LLM systems and agents in production. Scott introduces a Maslow’s hierarchy of observability: telemetry for logging, monitoring for known signals, and post-production or online analytics to surface unknown unknowns. We dig into examples of real-world failures Scott’s team has seen in production systems, such as “lazy” tool-use hallucinations that standard evals miss, and how mapping traces into vector fingerprints enables clustering and topic discovery to uncover emergent behaviors. Scott explains how analytics can feed the data flywheel by generating evals, guardrails, and training data, and why online, adaptive approaches are essential for non-stationary models. We also touch on practical how-to’s such as instrumentation with OpenTelemetry, the GenAI semantic conventions, and the role of dedicated analytics tools.
🗒️ For the full list of resources for this episode, visit the show notes page: https://t.co/wklGSSeIs7.
📖 CHAPTERS
===============================
00:00 - Introduction
01:32 - What is Distributional?
03:54 - Bayesian statistics and optimization in multiagents
08:14 - Anti-patterns
10:11 - Hierarchy of observability
16:12 - Applying analytics in the lifecycle
21:58 - Trace clustering and vector mapping
26:42 - Evals
31:04 - OpenTelemetry (OTEL) and the Gen AI semantic convention
35:47 - Non-stationarity and “model weather” reports
41:30 - Examples of distribution shifts
46:24 - Distributional is open distribution
47:05 - Metrics for applying analytics
48:54 - Academic benchmark
51:07 - Future directions
First self-improving agent PR! 🦞✨📈
Minimal setup:
🤖 - agent sends traces to @dbnlAI
🦞 - @openclaw uses :
- @github repo
- @cursor_ai agent cli
- @SlackHQ
📊 - claw pulls DBNL insights
📈 - claw orchestrates creating PRs
Would love to chat if this sounds cool (DM, email anytime)
Distributional has a FREE SaaS option!
Just send prod agent traces and get:
🗂️ - free trace storage
📊 - KPIs, metrics, and insights
🧠 - free LLM to power trace analysis
Sign up and use for free : https://t.co/GQKgKz5yrd
Help you and your agents understand what to improve next!
#moptheslop
Most AI teams think they have observability, but what they actually have is instrumentation.
Take the assessment to learn where your organization falls on the observability maturity scale: https://t.co/CHlcyAE39m
Find the unknown unknowns with your AI agent's behavior with tab complete analytics. Learn more how DBNL enriches your traces instead of just tracking evals: https://t.co/KOhsssZyoP
Centralize your AI governance. DBNL helps teams make better decisions around the product, cross-team resource allocation, and regulatory considerations: https://t.co/0gFVko8JwO