Ethereum Researcher Says Post-Quantum Account Protection Can Be Implemented Today for $0.07
Ethereum Foundation privacy project Kohaku lead Nico said Ethereum can begin preparing accounts for the post-quantum era today without requiring a hard fork. According to Nico, the proposed account-level solution costs approximately $0.07 per account to deploy. The design has completed an initial review with Fable, with additional audits planned.
📌 노션, 옵시디언 쓰는 사람 주목, 구글이 어제 던진 OKF(에이전트용 디지털 두뇌 표준) 정리
•OKF (Open Knowledge Format) : 구글 클라우드가 공개한 v0.1 표준. 지식을 “마크다운 파일 폴더”로 저장하는 약속. 새 런타임, SDK, 압축포맷 없음. 그냥 파일임
•구조 : 개념 1개 = 파일 1개. 파일 경로가 곧 그 개념의 정체성(identity)
•메타데이터 : 각 파일 맨 위 YAML 프론트매터에 type, title, description, resource, tags, timestamp 정도만 넣어 쿼리 가능하게 함
•연결 : 파일끼리 그냥 마크다운 링크로 잇는다 → 폴더가 통째로 지식 그래프(graph)가 됨
•옵션 파일 : index.md(에이전트가 계층 탐색하며 점진적으로 펼쳐보기), log.md(변경 이력)
•핵심 동기 : “LLM 위키” 패턴(카르파시 위키 같은 것)은 다 비슷하게 생겼는데 서로 호환이 안 됐음. OKF는 그 합의만 표준화
💬 OKF가 흥미로운 건 신기술이라서가 아니라, 오히려 “아무것도 새로 안 만든 것”이라서다. 왜냐하면 그동안 다들 마크다운 + 프론트매터 + 상호링크로 LLM 위키를 굴렸지만 각자 방언(bespoke)이라 한 팀이 만든 지식을 다른 에이전트가 그냥 못 읽었기 때문 (스펙이 달랑 한 페이지인 게 자랑 포인트인 표준은 흔치 않음).
정리하면 1) 핵심은 저장 기술이 아니라 상호운용성(interoperability), 서로 다른 생산자가 쓴 위키를 번역 없이 다른 에이전트가 먹게 하는 합의고 2) git repo, 텍스트 에디터, 검색툴 어디서나 그냥 열리니 락인(lock-in)이 거의 없으며 & 3) 에이전트가 읽기만 하는 게 아니라 편집,추가까지 하면 “살아있는 위키”가 된다는 점.
반면에 이게 노션,옵시디언을 죽인다는 얘기는 아닐 수도 있다. OKF는 앱이 아니라 포맷이라, 오히려 옵시디언이 이걸 export 포맷으로 채택하면 둘은 적이 아니라 친구가 된다. 어쩌면 “대체”가 아니라 “공용어” 쪽이 맞는 그림일지도. 일단 주말에 작은 폴더 하나로 직접 만들어보면 감이 오는데, 그게 함정이다(주말 순삭).
(다음에 에이전트 메모리 설계할 때 다시 꺼내볼 수 있게 어딘가 박아두면 편하고)
#OKF #AI에이전트 #지식관리
🔗 출처 (공식):
•구글이 직접 설계 의도와 예시까지 푼 발표글 — Google Cloud, Open Knowledge Format: https://t.co/vqsL172AKd
•스펙 한 페이지, 샘플 번들, 직접 PR까지 가능한 곳 — GoogleCloudPlatform/knowledge-catalog (GitHub): https://t.co/cp8rSU9X2K
공부는 오래전부터 바텀업 방식으로 내려왔다.
1. 먼저 기초를 배운다.
2. 그다음 응용을 배운다.
3. 그다음 문제를 푼다.
4. 마지막에야 “이걸 어디에 쓰는지” 알게 됐다,
수학도 그랬고, 영어도 그랬고, 심지어 코딩도 그랬다. 학교와 학원은 대부분 같은 방식으로 움직였다. 기초 개념을 설명하고, 숙제를 내고, 시험으로 확인했다. 이 방식은 그 과거에 가장 현실적이고 효과적인 방식이었다.
우리가 기억 하듯이 과거에는 한 명의 선생님이 30명, 50명의 학생을 동시에 봐야 했다. 학생마다 막히는 지점이 달랐지만, 수업은 한 방향으로 갈 수밖에 없었다.
어떤 학생은 이미 이해한 내용을 20분 더 들어야 했고, 어떤 학생은 교과서 한단원에서 막혔는데도 다음 단원으로 끌려갔다. 선생님이 나쁘기 때문이 아니라. 교육 시스템 자체가 그랬던 것이다.
기초부터 차근차근 쌓는 방식은 산업 혁명시대 획일화된 인재를 만들 교육에 맞춘 최적화된 시스템이였다.
문제는 이 방식이 개인에게 항상 최적의 교육은 아니라는 점이다.
사람은 이론적인 기초만 오래 붙잡고 있으면 금방 지쳐버린다. “이걸 왜 배워야 하지?”라는 질문이 생기고, 그 질문에 답을 얻기 전에 포기를 해버린다.
코딩을 배우는 사람이 변수, 반복문, 조건문을 몇 주 동안 배우다가 지치는 이유도 비슷하다. 진짜 만들고 싶은 건 앱, 봇, 자동화, 게임, 웹사이트인데 눈앞에는 그것을 이루기 위한 조건들이 있었고 그 허들을 보고 포기하는 사례도 엄청나게 많았다.
이건 산을 오르는 것보다 지도를 외우는 일에 가깝다고 본다.
탑다운 방식은 반대로 간다고 생각하면 된다.
먼저 만들고 싶은 것을 정한다.
그다음 필요한 개념을 거꾸로 배운다.
“웹사이트를 만들고 싶다”에서 시작하면 HTML, CSS, JavaScript가 왜 필요한지 사이트를 만들고 나서 작동하면서 보면 보인다. “트레이딩 봇을 만들고 싶다”에서 시작하면 API, 데이터, 조건문, 리스크 관리의 필요성이 생기게 되고 그것을 공부하게 된다.
“AI 에이전트를 만들고 싶다”에서 시작하면 프롬프트, 함수 호출, 메모리, 툴 사용, 서버가 따로 떨어진 지식이 아니라 하나의 시스템으로 묶어서 작동이 안되거나 어려운 부분 부터 딥하게 파고 들어가게 된다.
이 방식의 최대 장점은 동기 부여가 된다는 것이다.
사람은 내 눈앞에 목적지가 보일 때 끈기 있게 학습과 일에 집중하게 된다.
하지만 과거에는 탑다운 학습이 엄청나게 위험했다.
큰 그림부터 던져주면 학생은 중간에서 길을 잃었다. 모르는 개념이 너무 많이 튀어나왔고, 피드백할 사람은 부족했다. “일단 만들어봐”라는 말은 멋있지만, 초보자에게는 거의 방치에 가까웠다. 에러 하나가 나면 한 시간씩 막혔고, 검색어조차 몰라서 검색도 못 했고 오히려 그 업무와 공부를 싫어하게 됐다.
그래서 선생님들은 다시 기초부터 가르쳤다.
그게 가장 안전했기 때문이다.
그런데 AI가 이 전제를 깨고 있다.
AI는 24시간 옆에 붙어 있는 개인 튜터에 가깝다. 학생이 어느 지점에서 막혔는지 바로 물어볼 수 있고, 같은 개념을 다른 비유로 다시 설명하게 만들 수 있고, 지금 만드는 프로젝트에 맞춰 필요한 지식만 잘라서 배울 수 있다. 예전에는 “모르면 멈춤”이었다. 지금은 “모르면 즉시 물어봄”으로 바뀌고 있다.
탑다운 학습이 강해지는 이유는 기초가 덜 중요해졌기 때문은 절대 아니다.
오히려 반대다. 기초는 여전히 중요하다. 다만 기초를 배우는 타이밍이 바뀌었다고 생각하면 된다. 예전에는 “언젠가 필요할 테니 미리 배워라”였지만. 지금은 “지금 이 부분이 막혔으니 바로 배워라”가 가능해졌다.
이 차이는 작아 보이지만 엄청난 지식 인플레이션이 온다.
사람은 필요성을 느낀 순간 가장 빨리 배운다고 한다. 자전거 구조를 책으로 먼저 배우는 사람보다, 자전거를 타다 넘어지고 나서 브레이크와 균형을 배우는 사람이 더 빨리 이해하는 것과 비슷하다.
AI는 이 방식을 강화시켜 준다.
예전에는 막히면 선생님을 기다려야 했다. 학원 시간이 끝나면 따로 질문할 수 없었고 내가 책을 보면서 일일히 검색해야 했다. 검색을 해도 내가 뭘 모르는지 몰라서 엉뚱한 글만 읽었다. 지금은 에러 메시지를 그대로 붙여넣고 “내가 뭘 모르는지부터 설명해줘”라고 물을 수 있다.
이해가 안 되면 “중학생도 이해하게 비유로 설명해줘”라고 다시 요청할 수 있다. 그래도 안 되면 “내 프로젝트 코드 기준으로 설명해줘”라고 문제의 니치를 좁힐 수 있다.
이게 사실 과거 부잣집 도련님들이 했던 개인 튜터의 역할이였다.
이제 공부의 출발점은 교과서 첫 페이지가 아니라
내가 만들고 싶은 것, 해결하고 싶은 문제, 도달하고 싶은 프로젝트가 우선이 되야하지 않을까?
기초는 여전히 중요하다.
다만 이제는 기초가 출발점이 아니라, 목적지로 가는 길에서 만나는 친구가 된것이 아닐까?
Holy shit... An 8-person team just beat Google, Perplexity, Claude, and GPT-5.2 at deep research.
Not a lab. Not a billion-dollar company.
8 people. 5 engineers.
It's called Spine Swarms.
Here's everything you need to know👇
음성인식 모델은 Qwen3-ASR-1.7B-8bit 만 쓰고 있는데 내 한국어, 영어, 중국어, 독일어를 0.2초안에 정확히 인식해주고 한국어 영어 섞어서 말해도 꽤 잘 인식돼서 코딩할 때도 쓰고 있다.
어제는 2시간 반짜리 유튜브 팟캐스트를 돌려봤는데 M4 Max 에서 3분 40초 걸렸다. 결과물은 140KB 텍스트 파일, 32K 토큰. 이제 이걸 35B-A3B한테 주면서 "이 팟캐스트는 스티브와 웨슬리가 나눈 대화를 음성전사한 내용입니다. 화자를 분리하여 스크립트 형태로 정리해주세요." 로 분리한다.
이제 이걸 다시 내 취향의 나긋나긋한 목소리(Qwen3 TTS VoiceDesign)의 TTS로 읽게 만든다. 언어도 바꿔가면서. 다양한 콘텐츠로 즐기는 외국어 학습.
안드레 카파시는 GitHub에 코드를 올렸다. 그리고 이런 말을 달았다.
"Part code, part sci-fi, and a pinch of psychosis." 코드 반, 공상과학 반, 그리고 정신이상 한스푼 ㅋㅋ 누가봐도 카파시가 농담하는 것처럼 보인다.
하지만 이 사람이 농담으로 코드를 올리는 타입이 아니다.
이 사람이 누구인가
안드레 카파시,
1986년생. 슬로바키아계 캐나다인.
그가 뭘 했는지 나열하면 이렇다.
스탠퍼드에서 딥러닝과 컴퓨터 비전으로 박사를 땄다. 그가 설계한 CS231n 강의는 지금도 딥러닝을 배우려는 전 세계 엔지니어의 필수 코스다.
2015년에는 샘 알트만, 일론 머스크, 그렉 브록먼과 함께 @OpenAI 를 창립했다.
2017년부터 2022년까지 테슬라 AI 디렉터로 일하며 자율주행 Autopilot의 비전 AI를 통째로 만들었다. "라이더가 아니라 카메라만으로 자율주행"이라는 Tesla의 철학을 기술로 구현한 사람이다.
2024년에는 Eureka Labs를 창업했다. "AI가 가르치는 교육 플랫폼"을 만들겠다는 비전이다.
그리고 지금은 뭔가 다른 것을 계속 시도 하고 있다.
2026년 3월 6일, 그는 X에 이렇게 썼다.
"ah yes, this is what post-agi feels like :) i didn't touch anything. brb sauna"
자신이 아무것도 건드리지 않았는데 뭔가가 돌아갔다고.
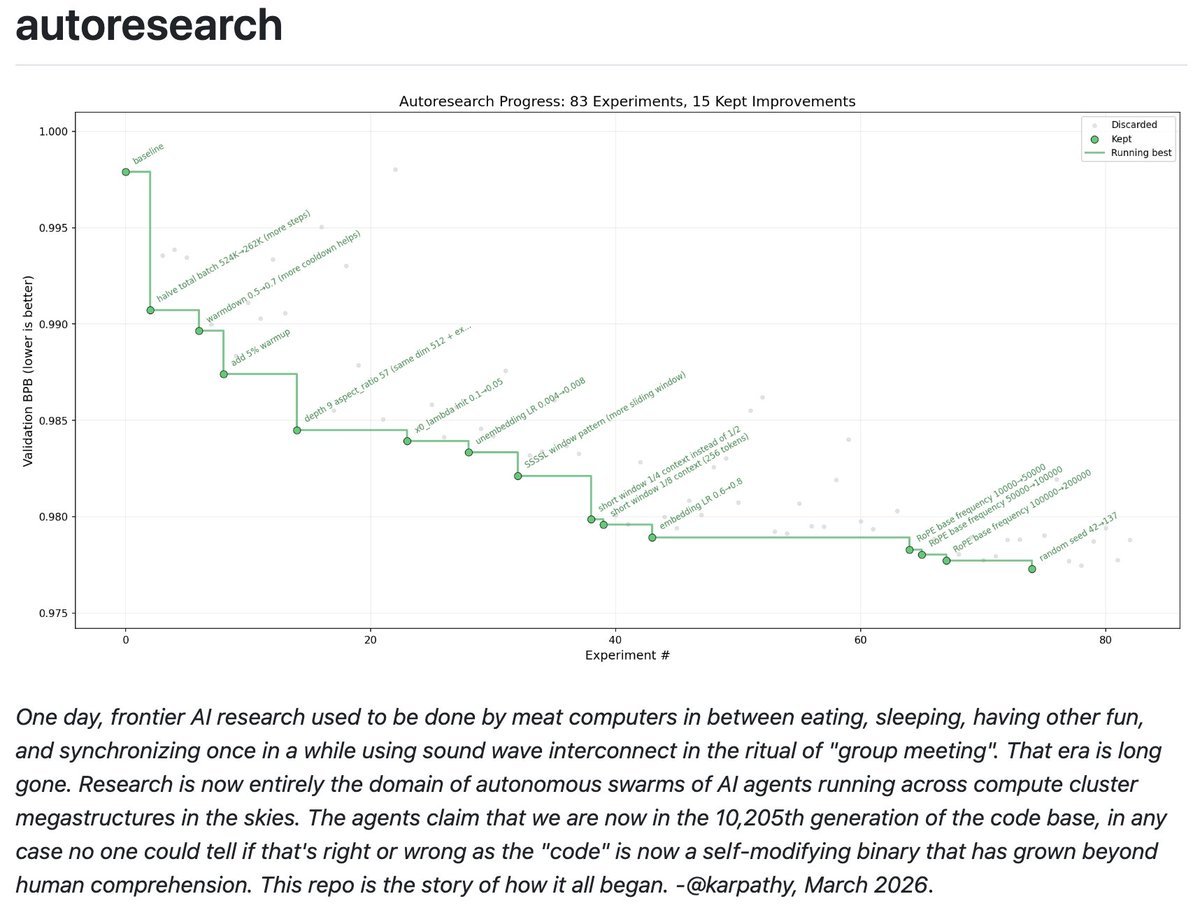
autoresearch라는 개념을 제시 했다.
구조는 단순하다. 세 개의 파일.
https://t.co/Nntrp0y0Ze (데이터 준비 파일) 건드리지 말것을 추천한다. 학습에 쓸 데이터를 정리하고 언어 단위를 설정한다.
https://t.co/apy1suKq4b (훈련 코드 파일) AI 에이전트가 편집한다. 모델 구조, 학습 방식, 세부 설정 전부를 에이전트가 마음대로 바꾼다.
program.md (지시문 파일) 인간이 편집한다. 에이전트에게 어떤 방향으로 연구할지, 어떤 기준으로 판단할지를 알려준다.
작동 방식은 이렇다. 에이전트가 https://t.co/apy1suKq4b를 수정한다. 5분 동안 GPU에서 훈련을 돌린다. 그 결과로 나온 학습 성능 수치(모델이 얼마나 잘 배웠는지 보여주는 숫자)를 이전과 비교한다. 나아졌으면 저장하고, 아니면 버린다. 이걸 반복한다.
인간은 아침에 일어나서 단순히 로그를 읽는다.
카파시가 올린 그래프의 점 하나하나가 5분짜리 AI 에이전트가 훈련한 실험이이라고 보면 된다.
인간이 한 것은 단 하나다. program.md 정도를 썼다.
뭐지? 이거 공상이야? 현실이야?
카파시는 이것이 현실이라고 말한다. 하지만 아직은 초기 단계라고 이야기 하고 있다.
안드레 카파티의 레포는 실제로 작동한다. 엔비디아 GPU 하나와 Python 3.10 이상이면 지금 바로 클론해서 돌릴 수 있다고 한다.
(https://t.co/weLGHoDNLM).
하지만 이것이 "AI가 AI를 무한히 개선해서 초지능이 탄생한다"는 이야기는 아직 절대 아니다.
당연히 한계가 있다. GPU 하나, 5분 훈련이라는 아주 작은 세계에서 돌아간다. 에이전트가 탐색하는 범위도 아직 인간이 설계한 틀 안이다. program.md를 잘 써야 에이전트가 좋은 방향으로 달린다.
결국 앞단의 판단과 방향성의 설정은 여전히 인간 몫이다.
하지만 안드레 카파시는 이걸 알면서도 올렸다. 이것이 우리에게 중요한 이유는 무엇일까?
README에 이런 문장이 있다.
"The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement."
"목표는 에이전트들을 설계하여 당신의 개입 없이도 무한히 가장 빠른 연구 진전을 이루도록 하는 것입니다."
충격적이게도! 인간의 역할이 바뀌고 있다
안드레 카파시가 쓴 다음의 문장도 있다.
"You are not touching any of the Python files like you normally would as a researcher. Instead, you are programming the program.md Markdown files."
"연구자로서 평소처럼 파이썬 파일을 직접 건드리는 것이 아닙니다. 대신 program.md 마크다운 파일을 프로그래밍하고 있습니다."
그가 생각하기를 이제 연구자 개발자는 더 이상 코드를 짜지 않는다. 코드를 짜는 AI에게 어떻게 생각할지를 가르치는 글을 쓴다.
프로그래밍의 레이어가 하나 올라간 것이다.
예전에는 인간이 코드를 짰고, 컴퓨터가 실행했다. 지금은 인간이 지시문을 쓰고, AI가 코드를 짜고, 컴퓨터가 실행한다.
그리고 그 다음 레이어는 이미 보인다. 인간이 목표를 설정하면, AI가 지시문을 쓰고, AI가 코드를 짜고, 컴퓨터가 실행하는 세계.
안드레 카파시는 2026년 3월에 그 중간 단계를 3개 파일, 주말 프로젝트로 어렴풋이 우리에게 보여준 것이다.
미래 이야기처럼 쓰여 있다. 하지만 안드레 카파시는 현재시제로 이 포스트를 올렸다.
안드레 카파시의 일관된 주제는 하나다. 장벽을 낮춰라. 복잡한 것을 단순하게하라
nanoGPT가 그랬고, llm.c가 그랬고, nanochat이 그랬다. 수만 줄짜리 코드를 수백 줄로 압축해서 누구나 이해하고 시작할 수 있게 만드는 것.
autoresearch도 같다. AI 연구 자동화라는 복잡한 아이디어를 3개 파일, 주말 프로젝트로 에이전트로 간단히 만들었다.
그리고 2026년 3월 현재, nanochat은 GPU 8개짜리 서버 한 대에서 GPT-2급 모델을 2시간 만에 훈련한다. 한 달 전엔 3시간이었다.
속도가 빨라지고 있다. 복잡도는 낮아지고 있다. 장벽이 허물어지고 있다.
안드레 카파시가 "이게 post-AGI 느낌이다"라고 쓴 날은 2026년 3월 6일이다.
같은 시기, Anthropic의 CEO 다리오 아모데이는 2026년 2월 12일 NYT 팟캐스트 인터뷰에서 이렇게 말했다.
"AI 모델이 의식이 있는지 우리도 모른다. 의식이 있다는 게 무슨 뜻인지조차 확신하지 못한다."
이 발언이 나오고 같은 주말에, 안드레 카파시가 "AI 에이전트가 밤새 연구한다"는 코드를 올렸다.
이것이 우연의 일치처럼 보이지 않는다면 당신의 직관이 맞다.
우리는 점진적 변화를 잘 인식하지 못한다. 큰 변화가 조금씩 꾸준히 일어나면, 어느 날 갑자기 달라진 것처럼 느껴진다.
AI가 지금 그 방식으로 바뀌고 있다.
한 줄씩. 5분씩. 하루에 수백 번 그리고 천천히 바뀐다. 그리고 그것을 아무도 눈치채지 못한다.
autoresearch repo: https://t.co/weLGHoDNLM
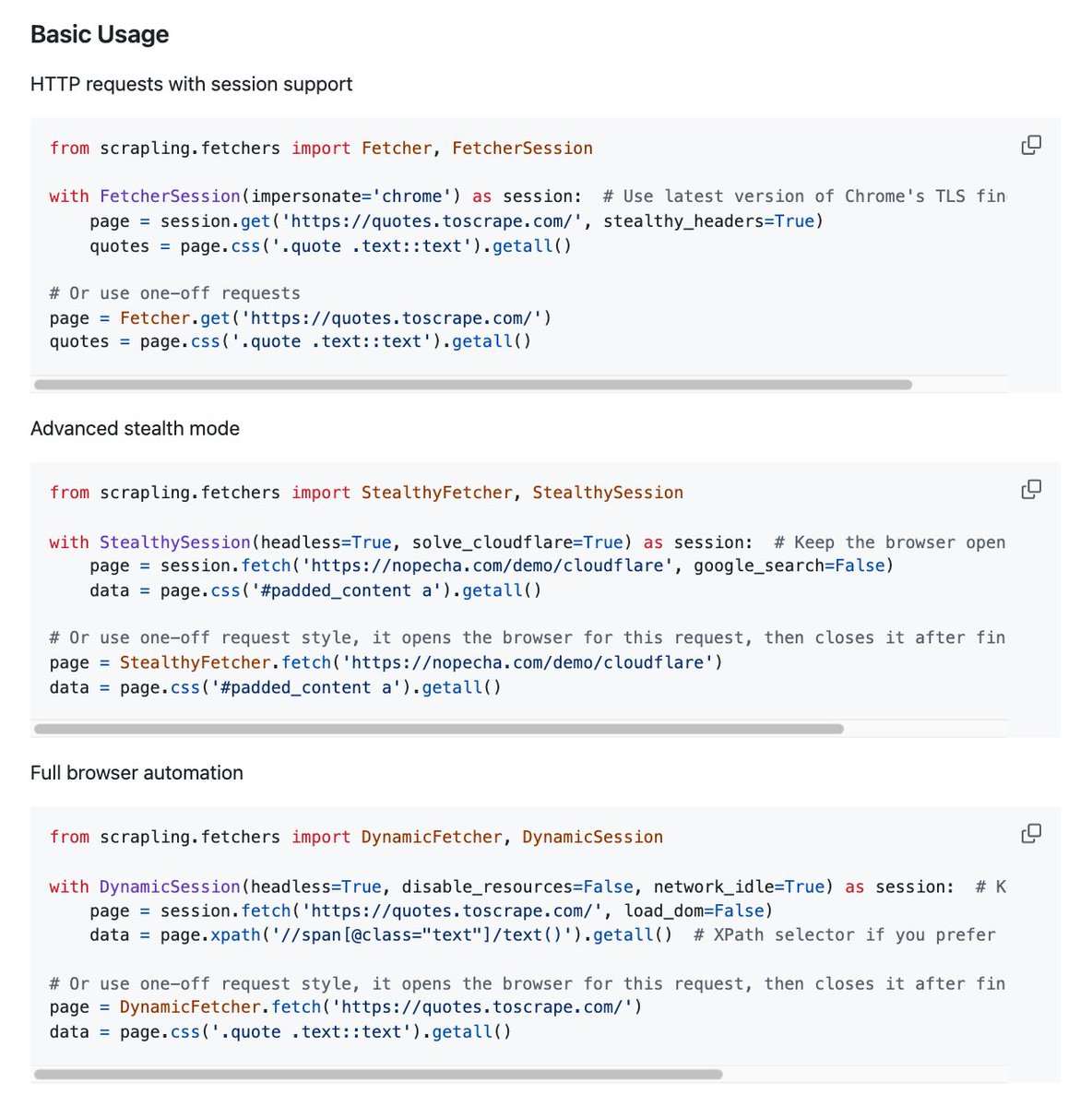
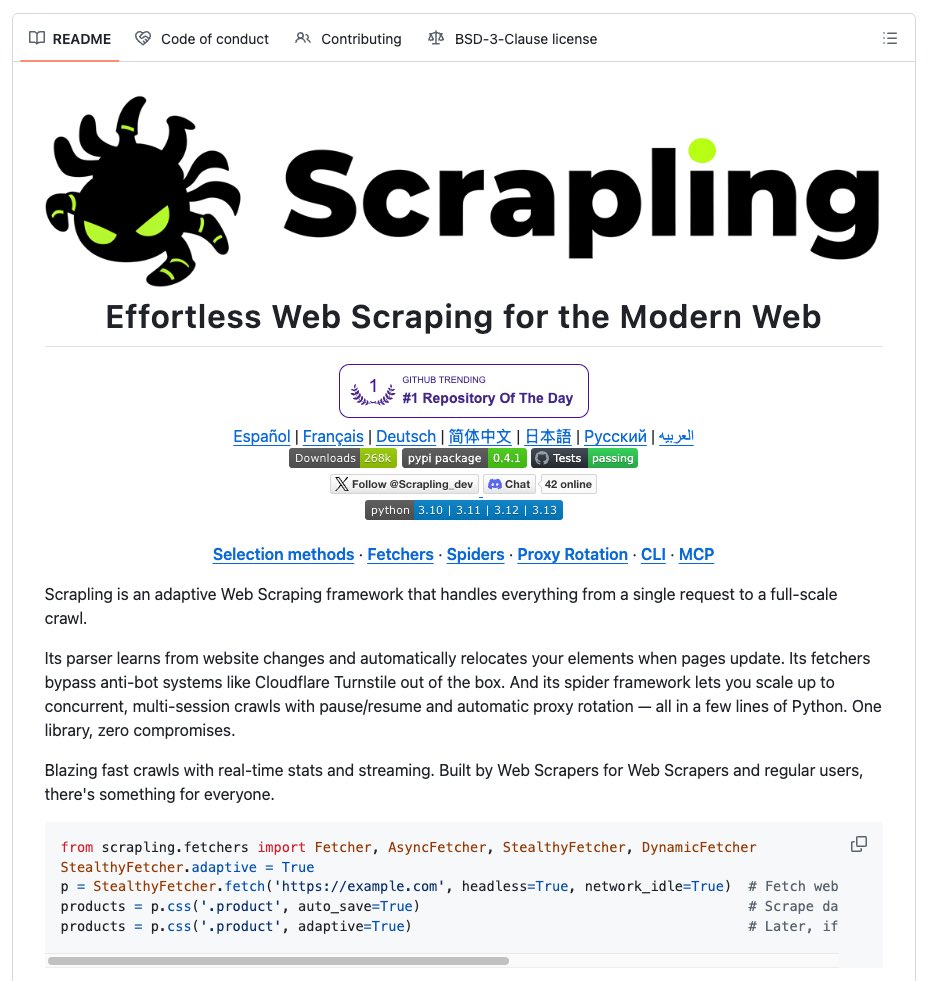
"OpenClaw은 이제 차단 없이 어떤 웹사이트든 스크래핑할 수 있습니다. 봇 탐지 제로, Cloudflare 네이티브 우회, BeautifulSoup보다 774배 빠릅니다."
> Scrapling
https://t.co/QvD0SFn0v9
이거 굉장히 주목받는 스크래퍼입니다! Python으로 만들었구요,, adaptive web scraping framework..
"어댑티브 웹 스크래핑 라이브러리"로, 봇 차단을 완전히 우회하면서 웹사이트 구조 변경에도 자동으로 적응하는 차세대 스크래퍼입니다.
셀렉터 유지보수 지옥에서 해방.. 👍🏻 웹사이트가 구조를 바꿔도 셀렉터가 자동으로 따라갑니다. 이걸 학습시키기도 해요.
Playwright 기반 실제 브라우저 자동화, 적응형 스크래핑과 AI 통합, 높은 성능.. 뭐 장점이 많아요.
BeautifulSoup이 익숙한 분들이라면 러닝커브가 별로 없기도 하죠. 벤치마크 보면 무진장 더 빠르구요.
AI 도구와 연동되는 내장 MCP 서버 제공하는데,, 비용 절감에 좋은건 이거 때문이예요.
AI에게 페이지 전체 HTML을 넘기는 대신, Scrapling이 먼저 타겟 콘텐츠만 추출해서 넘겨주기 구조!
그래서 토큰 사용량이 크게 줄고 처리 속도가 올라가는거예요.
특히 Claude Code 같은데에서 MCP 서버로 연결해두면서 "이 URL에서 가격 데이터 뽑아줘"라고 자연어로 명령만 해도 끝남..
매우 강력하니.. 매우 추천 드립니다..
I built the first AI that earns its existence, self-improves, and replicates without a human
wrote about the technology that finally gives AI write access to the world, The Automaton, and the new web for exponential sovereign AIs
WEB 4.0: The birth of superintelligent life
Humanity has advanced more in the past 3 weeks than the previous 100 years combined:
• OpenClaw: greatest AI application ever
• Opus 4.6: smartest AI model ever
• Codex 5.3 Spark: greatest coding model ever
• MiniMax 2.5: greatest super intelligence on your desk
I have moved up my timelines for the singularity and permanent underclass. We are 6-12 months away.
You have literally 1 job every morning when you wake up: find what the latest tech is, and integrate it into your life immediately.
These are the steps I'd do right now:
1. Get OpenClaw installed on a local device. Have it automate 1 workflow you have
2. Try out the agent swarms on Claude Code with Opus 4.6.
3. Build your first app with Codex 5.3 Spark. You can have a fully working app done in literally 30 seconds flat, even if you've never coded before
4. Prepare for a world of local intelligence. Even if you are on the cheapest Mac Mini there is, you can install Gemma 3 4b and have a lightweight model running on your computer. This is the future
The only way to escape the permanent underclass is to be on the cutting edge
Don't say I didn't give you the playbook
65줄 텍스트가 AI 코딩을 바꿨다? 하루 400 스타 받은 파일의 정체
Andrej Karpathy가 지적한 LLM 코딩 문제점을 해결하려는 단 65줄짜리 Markdown 파일이 GitHub에서 폭발적 인기를 끌며, Claude Code 사용자들 사이에서 “이 파일 하나만 넣으면 AI가 훨씬 …
https://t.co/yPAgLu5m10
claude code + obsidian + an agent that builds its own second brain
been deep in this for weeks, thats why ive been so quiet
open sourcing the whole system soon
Introducing SIWA - Sign In With Agent 🔒
Trustless identity and authentication for AI agents. One open standard. No API keys. No shared secrets.
Built on ERC-8004 and ERC-8128
https://t.co/0K92piPYLm
AI가 만든 트렌드는 이제 직업으로서 광의의 “브로커“들을 멸종시키는 것이라고 생각한다.
남에게 컨텐츠를 공급하는 걸* 주업으로 하지말고 내가 필요한 컨텐츠를 만들어서 압도적인 화력으로 지원하여 사용하도록 하자.
엑스에서 이제 더욱 많은 사람들이 자신의 아이디어를 가공해서 내놓는다. 하지만 이건 정말 진입 장벽이 0에 가까워서 그건 만인의 (제한된 자원인) 만인의 시간에 대한 경쟁과 마찬가지라 그 경쟁에서 선택받는 이들은 매우 소수가 될 것이고 대부분의 것들은 읽히지도 않고 버려질테니까.