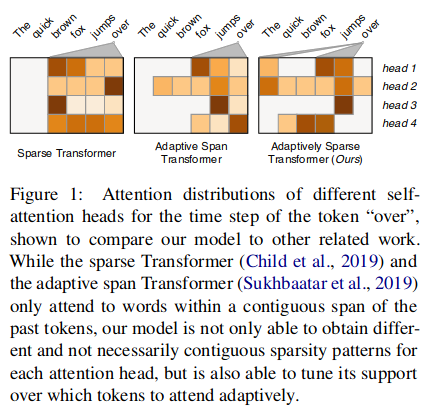
Adaptively Sparse Transformers
@emnlp2019 +Gonçalo Correia, André Martins
α-entmax attention
α=1: softmax, α=2: sparsemax, continuous in between.
twist: we learn α for each head, w gradients! Some heads become dense, some sparse.
https://t.co/j5fnYbzytz
https://t.co/HRvUnIZP9S
Joint Learning of Named Entity Recognition and Entity Linking
Pedro Henrique Martins, Zita Marinho, André Martins
https://t.co/Y4frVMIWzM
Tue 30, SRW, Posters 2 10:30–12:10 [5/11]
Unbabel's Participation in the WMT'19 Translation Quality Estimation Shared Task
WMT QE s. t. winner!
Fábio Kepler, Jonay Trénous, Marcos Treviso, Miguel Vera, António Góis, Amin Farajian, António Lopes, André Martins
https://t.co/u6ehU1rlEi
Fri 2, WMT APE 11:00–12:30 [11/11]
A nice write-up of the challenges of lemmatization by DeepSPINner Erick! Multilingual examples reveal different complexities hard to imagine if focusing on English.
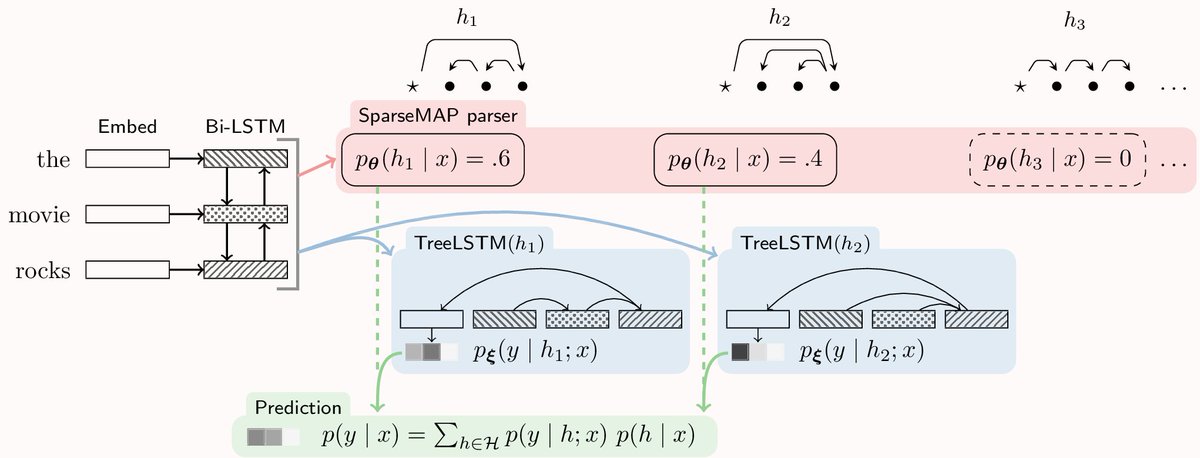
Towards Dynamic Computation Graphs via Sparse Latent Structure: #emnlp2018 + André @clairecardie
- marginalize over structured latent vars w/ SparseMAP
- CG a function of discrete structure
- eg latent dependency TreeLSTM
pdf https://t.co/fKQ64doAey
code https://t.co/nodZwOi4Jh
"Structure Back in Play, Translation Wants More Context"
DeepSPINner André Martins writes on the @Unbabel R&D blog his notes from this year's #icml2018 and #ACL2018:
https://t.co/QPpZ6uGWaV
2) #BlackboxNLP Interpretable structure induction via sparse attention:
@bpopuw, @vnfrombucharest, André Martins
We discuss the interpretability angle of recent & ongoing work on sparse, structured and constrained attention: sparsemax, fusedmax, constrained sparsemax, SparseMAP
DeepSPIN will be at #emnlp2018!
1) SparseMAP for latent dynamic computation graphs; @vnfrombucharest, André Martins and @clairecardie;
2) Discussing the interpretability of sparse/structured attention; @bpopuw, @vnfrombucharest, Martins at #BlackboxNLP.
(preprints soon)
-->




![deep_spin's tweet photo. Our group is headed to #acl2019nlp! Come chat at our posters and presentations listed in the attached image. More info in thread 👇👇 [1/11] https://t.co/7ZcpyDUfy5](https://pbs.twimg.com/media/EAZyz6fW4AADU0Q.png)