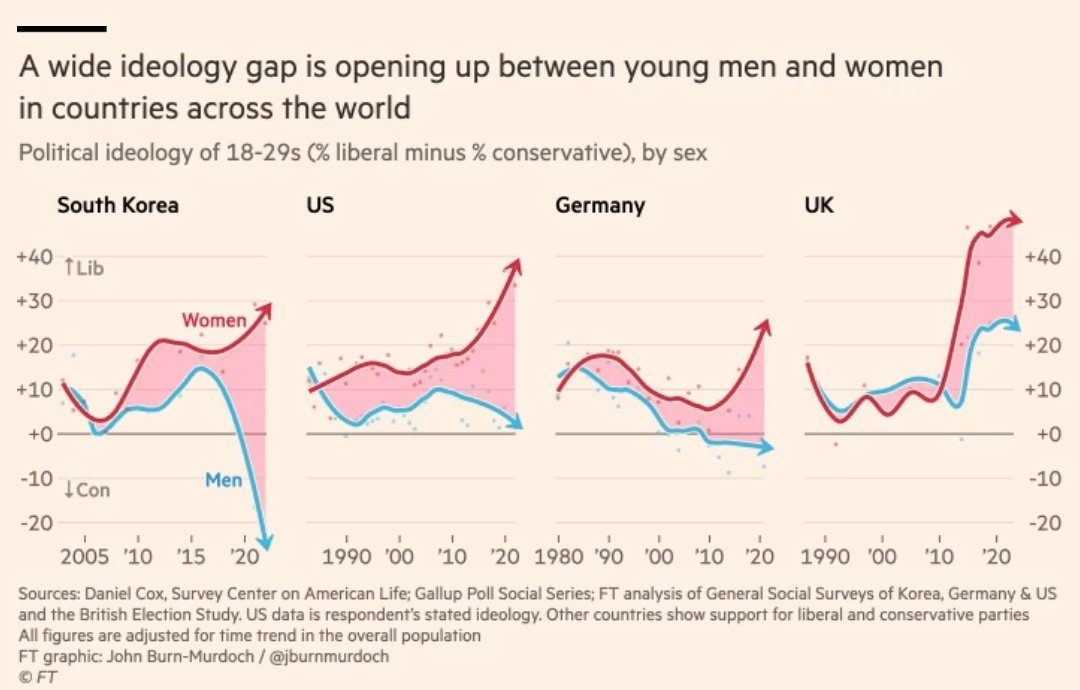
5 years, zero progress: actually regression. Men's domestic work time fell from 95 to 86 min/day. Women: still at 305 min: 3.5X more. Caregiving gap unchanged too (140 vs 74). The needle didn't just fail to shift. It moved the wrong way. (TUS 2024) #sharetheload
"It is quite difficult to defend what you didn't build. (...) The value of deeply understanding something — of having built the knowledge yourself — hasn't diminished with AI. If anything, it's increased."
“Can I bring my baby to the interview?”
The message came in at 11 PM:
“Hi, I have an interview with you tomorrow at 2 PM. My childcare fell through. Can I bring my 8-month-old? I understand if you need to reschedule.”
Old me would have rescheduled.
Unprofessional. Distraction. Red flag.
New me replied:
“Absolutely. See you tomorrow.”
She showed up with her baby on her hip.
She apologized three times before even sitting down.
Ten minutes in, the baby started crying.
She tried to soothe him while answering questions.
She apologized again.
I stopped the interview and said:
“Hey. You’re managing a fussy baby, answering complex questions, and staying calm under pressure. That’s literally the job. Handling chaos while staying professional. You’re already proving you can do it.”
Her eyes filled with tears.
We hired her.
She’s been with us for a year now.
The most reliable team member we have.
Why?
Because when you’re used to handling a screaming infant at 3 AM and still showing up to work the next day, workplace stress feels like nothing.
Working parents, especially mothers, are some of the most organized, efficient, and resilient people you’ll ever hire.
Yet we lose them because our hiring processes are built for people with zero caregiving responsibilities.
If your interview process can’t accommodate a parent facing a childcare issue, you’re not filtering for professionalism.
You’re filtering for privilege.
This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly:
Can LLMs actually discover science, or are they just good at talking about it?
The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead of asking models trivia questions, it tests something much harder:
Can models form hypotheses, design experiments, interpret results, and update beliefs like real scientists?
Here’s what the authors did differently 👇
• They evaluate LLMs across the full discovery loop hypothesis → experiment → observation → revision
• Tasks span biology, chemistry, and physics, not toy puzzles
• Models must work with incomplete data, noisy results, and false leads
• Success is measured by scientific progress, not fluency or confidence
What they found is sobering.
LLMs are decent at suggesting hypotheses, but brittle at everything that follows.
✓ They overfit to surface patterns
✓ They struggle to abandon bad hypotheses even when evidence contradicts them
✓ They confuse correlation for causation
✓ They hallucinate explanations when experiments fail
✓ They optimize for plausibility, not truth
Most striking result:
`High benchmark scores do not correlate with scientific discovery ability.`
Some top models that dominate standard reasoning tests completely fail when forced to run iterative experiments and update theories.
Why this matters:
Real science is not one-shot reasoning.
It’s feedback, failure, revision, and restraint.
LLMs today:
• Talk like scientists
• Write like scientists
• But don’t think like scientists yet
The paper’s core takeaway:
Scientific intelligence is not language intelligence.
It requires memory, hypothesis tracking, causal reasoning, and the ability to say “I was wrong.”
Until models can reliably do that, claims about “AI scientists” are mostly premature.
This paper doesn’t hype AI. It defines the gap we still need to close.
And that’s exactly why it’s important.
The average Nobel laureate grew up in an 87–90th percentile household.
Access to opportunity doubled from 1901–2023, but remains highly unequal.
Barriers are higher for women, but lower for Americans.
https://t.co/brk56JeHgo @paulnovosad
My paper on the costs of extreme competition for government jobs in India is now forthcoming at the Journal of Development Economics!
Open access link:
https://t.co/0Mn1UQFZ0u
What's the role of fathers in promoting early childhood development in middle- and low-income countries? @PJakiela and I talk with @TimSvengali on @Vox_Dev ⬇️ (based on this review paper: https://t.co/RqcJMlsStE)
The third edition of our Public Policy Conference will be held on August 2-3, 2024. Please see the Call for Papers below for details. Last date for submissions: April 15.
Dang this study found that the Swedish “daddy month” (use-it-or-lose-it paternity leave) led to a *drop* in kids’ GPA, driven entirely by sons of non-college-educated fathers. No effects for girls or for children of college-educated fathers.
https://t.co/q6n1rqx4zC
"I had a teacher that didn't like me and I didn't like him. At the end of the year he decided to fail me. The ironic thing is that the topic was chemistry. I have the distinction of being the only chemistry laureate who failed the topic in high school!"
- Tomas Lindahl
Soon we won't be able to use nightlights as a proxy for economic growth.
Why?
It's due to limitations of its spectral bands.
Here's the breakdown in simple terms:
Excited to present my JMP: Silence to Solidarity
My job market paper studies whether communication between discriminatory people can lead to large reductions in discrimination
🔗 https://t.co/IrRLIjPJLq
👇for more