I wrote Deep Learning with Python to be the definitive guide to how deep learning works and how to best make use of it. Tens of thousands of people got their career start via this book. 120,000 copies sold, and downloaded by millions more.
And now it's free to read online: https://t.co/3CbcQ7hmjp
MCP and A2A are both agent protocols but they operate at completely different layers.
MCP (Model Context Protocol) is about giving one LLM access to external tools. The model stays in the driver's seat throughout: it receives your query, decides which tools to call, gets the results back through an MCP Client, and assembles the final response. The MCP Servers in between are just standardized wrappers around raw APIs �� Flight Booking, Google Calendar, whatever you need. One brain. Centralized control.
A2A (Agent-to-Agent Protocol) is about coordination between autonomous agents. There's no single LLM managing everything — instead, an Orchestrator Agent delegates subtasks to specialized agents, each of which has its own tools, its own memory, and its own reasoning loop. The Orchestrator never touches the Flight API directly. It talks to a Flight Agent, which handles that domain entirely on its own, then reports back.
The architectural difference matters when you're building:
MCP works well when one model can reasonably handle the full task with tool access. A2A becomes necessary when subtasks are complex enough to need dedicated reasoning — or when you want agents that can operate in parallel without bottlenecking through a single model.
Same scenario — "book me a flight and add it to my calendar" — but one architecture keeps control centralized, the other distributes it across specialists.
If you're building agentic systems in 2026, understanding where this boundary sits will shape every design decision you make.
#agenticai #aiarchitecture #mcp #google #anthropic #aiengineering #multiagentsystems
AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]
Is context engineering just a new name for RAG?
Not quite. But they're solving the same problem: building the right context for your LLM.
Here's how we got from one to the other — and why it matters for AI data scientists.
Everyone assumes LLMs are the future of AI.
The permanent foundation. The layer everything else gets built on.
I’m not so sure.
The historical parallel that fits best isn’t the one most people want to hear.
LLMs are Edison’s DC power grid:
→ Genuinely revolutionary
→ Commercially dominant
→ Solving real problems right now
→ But architecturally limited in ways that can’t be patched
Right domain. Wrong architecture. And the evidence is already here.
Hallucination isn’t a bug. It’s the architecture.
Researchers have formally proven that LLMs cannot learn all computable functions and will therefore inevitably hallucinate when used as general problem solvers.
That’s not a training data problem. That’s math.
A separate paper demonstrated that hallucinations stem from the fundamental mathematical and logical structure of LLMs, making it impossible to eliminate them through architectural improvements, dataset enhancements, or fact-checking mechanisms.
And here’s the part that really gets you:
There’s a direct link between hallucination and creativity in LLMs.
It may be impossible to eliminate hallucination without impairing the model’s most crucial capabilities.
→ The thing that makes LLMs creative is the same thing that makes them lie
→ Fix one, you break the other
→ That’s not a tradeoff you engineer away. That’s a design constraint.
DC power had the exact same structural problem. It couldn’t transmit electricity over long distances.
Not because the engineering was bad. Because the physics made it impossible.
You needed AC. A fundamentally different approach.
The “AC power” of AI is already being built. And it has names.
This isn’t theoretical. People are already building the replacement architectures.
Yann LeCun left Meta and raised $1 billion to prove LLMs are a dead end.
AMI Labs raised $1.03 billion in seed funding at a $3.5 billion valuation in March 2026, making it the largest seed round in European history.
His thesis is simple: LLMs predict the next word. That’s not intelligence. That’s autocomplete at scale.
His core technology, JEPA, operates in latent space, learning abstract representations of reality rather than surface patterns.
LeCun used a vivid analogy: using an LLM to understand the real world is like teaching someone to drive by just talking.
A Turing Award winner didn’t just write a paper about it. He quit his job and bet a billion dollars on it.
Mamba is proving transformers aren’t the only game in town.
Mamba achieves 5x higher throughput than Transformers with linear scaling in sequence length.
Thanks to intensive research in 2023-2025, non-transformer architectures have reached parity with Transformers on key language benchmarks, and in some cases surpassed them.
Hybrid architectures are already shipping.
By 2026, models built on hybrid transformer-SSM architectures can ingest hundreds of pages of text at once, far beyond vanilla GPT-3 or GPT-4.
The alternatives aren’t coming. They’re here.
Meanwhile, look at what the industry is building to keep LLMs functional:
→ Agents (because the model can’t verify its own outputs)
→ Tool use (because the model can’t interact with the real world)
→ Reasoning chains (because the model can’t reason natively)
→ RAG (because the model can’t reliably recall facts)
These aren’t features. These are workarounds.
When you need that many patches, you’re running longer DC power lines and wondering why the voltage keeps dropping.
Now the part everyone actually needs: which skills survive the transition?
When DC shifted to AC, some electrical engineers thrived and some went extinct.
The ones who thrived understood circuits, load management, and power distribution at a fundamental level. Those principles worked on any architecture.
The ones who didn’t? They only knew DC-specific wiring.
The same split is coming. And it’s coming faster than people think.
Here are the skills that transfer no matter what replaces transformers:
→ Systems thinking for AI workflows. Breaking complex tasks into steps an AI can execute. This works whether the AI is a transformer, an SSM, JEPA, or something we haven’t built yet. Architectures change. The need for structured task decomposition doesn’t.
→ Evaluation and verification. Knowing if AI output is right. LLMs have a “Self-Correction Blind Spot” where they can recognize errors but lack the reasoning pathways to correct them.  Whatever comes next will still need humans who can evaluate quality. This skill gets MORE valuable, not less.
→ Data literacy. Understanding what data an AI needs, how to structure it, what’s clean vs. noisy. Every AI architecture runs on data. Past, present, future. The people who understand data will always have leverage.
→ AI-augmented workflow design. Not “how to write a good prompt” but “how to redesign a business process so AI handles the right parts and humans handle the right parts.” This is architecture-agnostic. It transfers to anything.
→ Domain expertise + AI fluency. The most powerful combination is stacking AI fluency on top of deep domain expertise.  A lawyer who understands AI beats a prompt engineer who doesn’t understand law. Every time. Regardless of what model they’re using.
→ Clear problem definition. Prompt engineering is just one implementation of a deeper skill: translating human intent into machine-executable instructions. Whether that instruction is a prompt, an API call, a config file, or something that doesn’t exist yet, the ability to define what you want is permanent.
And here’s what DOESN’T transfer:
→ Memorizing specific model behaviors (“Claude does X, GPT does Y”)
→ Platform-specific tricks that only work on one tool
→ Building your identity around a single product name
→ “Prompt engineer” as a job title instead of a thinking skill
The difference is simple:
→ Transferable skills = understanding WHY something works
→ Non-transferable skills = memorizing HOW a specific tool works
WHY survives paradigm shifts. HOW doesn’t.
The bottom line
The principle behind LLMs is permanent. The architecture probably isn’t.
That’s not bearish on AI. That’s the most bullish take possible. It means the best is still ahead of us.
Use LLMs hard right now. Build with them. Ship on them.
But build your skills around the PRINCIPLES, not the PRODUCTS:
→ Learn systems thinking, not just prompting
→ Learn evaluation, not just generation
→ Learn data literacy, not just tool literacy
→ Learn workflow design, not just model tricks
→ Stack domain expertise on top of AI fluency
The people who do this will thrive in the transformer era AND whatever comes after it.
Edison built a working power grid that lit up Manhattan. It was real, valuable, and changed the world.
AC still replaced it.
These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of 50 LLM interview questions - shared by Hao Hoang.
What's covered:
Fundamentals:
→ Tokenization and why it matters
→ Attention mechanisms in transformers
→ Context windows and their tradeoffs
→ Embeddings and initialization
→ Positional encodings
Fine-tuning & Efficiency:
→ LoRA vs QLoRA
→ PEFT to prevent catastrophic forgetting
→ Model distillation
→ Adaptive Softmax for large vocabularies
Generation & Decoding:
→ Beam search vs greedy decoding
→ Temperature, top-k, top-p sampling
→ Autoregressive vs masked models
Advanced Concepts:
→ RAG (Retrieval-Augmented Generation)
→ Chain-of-Thought prompting
→ Mixture of Experts (MoE)
→ Knowledge graph integration
→ Zero-shot and few-shot learning
Math & Theory:
→ Softmax in attention
→ Cross-entropy loss
→ KL divergence
→ Gradient computation for embeddings
→ Vanishing gradient solutions in transformers
You don't need to follow me (@techNmak) and comment "LLM". I will put the link in the comments.
Stanford just released a 1.5-hour lecture on “LLM Architecture.”
This is the exact thing systems engineers at Anthropic and OpenAI require to understand at a deep level.
Give it some time.
This might be the highest-ROI learning you do this month.
🚨 RIP Prompt Engineering
Enter Context Engineering 2.0
It completely reframes how we think about human-AI interactions.
This is what you need to know (28 page PDF):
RAG is broken and nobody's talking about it.
Stanford researchers exposed the fatal flaw killing every "AI that reads your docs" product in existence.
It’s called "Semantic Collapse," and it happens the second your knowledge base hits critical mass. If you've noticed your AI getting "dumber" as you add more data, this is exactly why.
Right now, companies are dumping thousands of documents into their AI, thinking it’s getting smarter.
When you add a document to RAG, it converts it into a high-dimensional vector.
Under 10,000 documents, this works perfectly. Similar concepts cluster together.
But past 10,000 documents, the space fills up. The clusters overlap. The distances compress.
Everything starts to look "relevant."
It is a mathematical law called the Curse of Dimensionality. In a 1000-dimensional space, 99.9% of your data lives on the outer edge. All points become equidistant from each other.
That perfect, relevant document you are looking for now has the exact same mathematical similarity as 50 completely irrelevant ones.
The Stanford findings are brutal:
At 50,000 documents, precision drops by 87%. Semantic search actually becomes worse than old-school keyword search.
Adding more context doesn’t fix the AI. It makes the hallucinations worse.
Your "nearest neighbor" search isn't finding the best answer anymore. It's finding everyone.
We thought RAG solved hallucinations.
It didn't. It just hid them behind math.
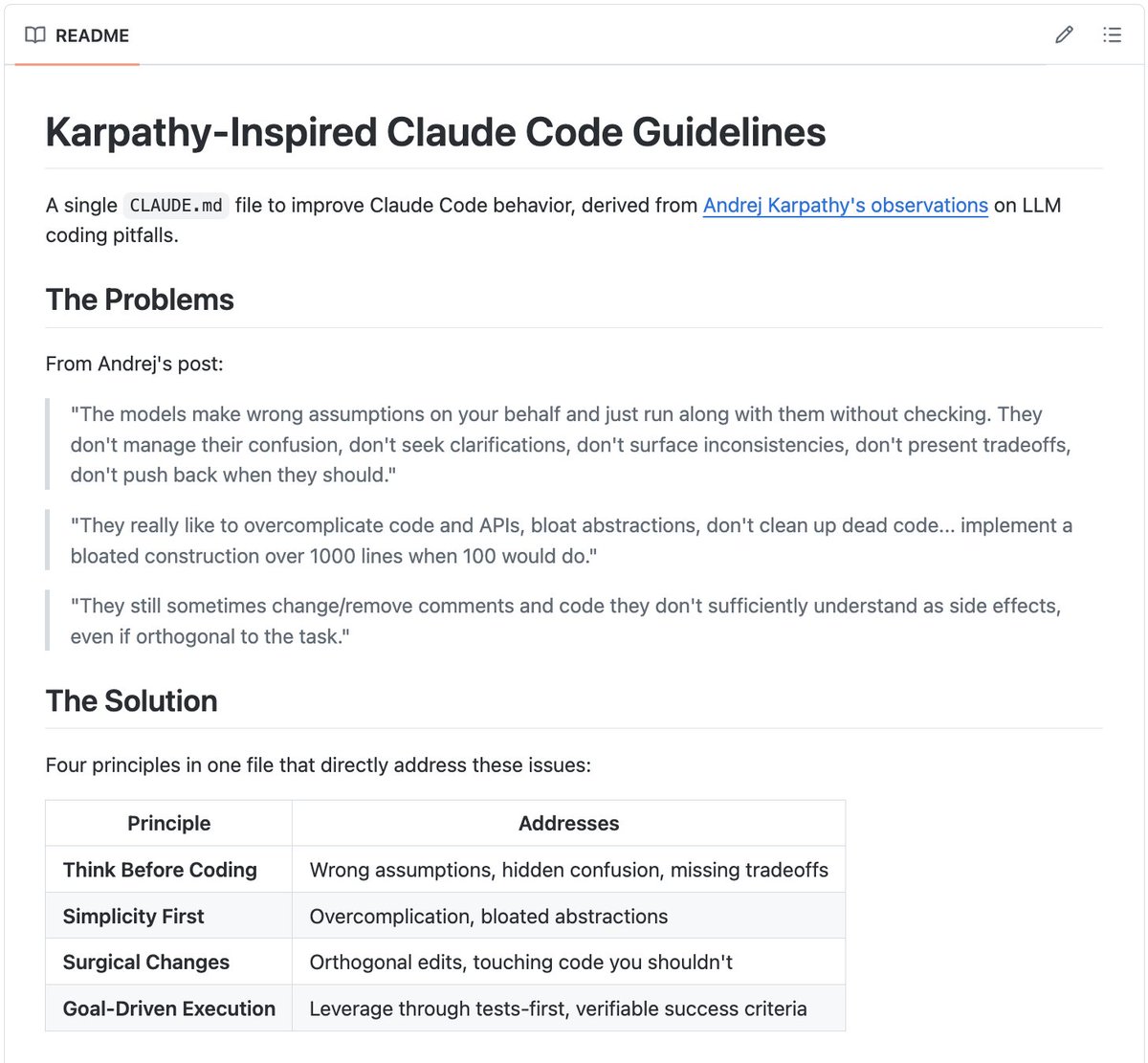
Andrej Karpathy wrote something that every Claude Code user has felt but couldn't articulate.
Three quotes. Read them slowly.
"The models make wrong assumptions on your behalf and just run along with them without checking. They don't manage their confusion, don't seek clarifications, don't surface inconsistencies, don't present tradeoffs, don't push back when they should."
"They really like to overcomplicate code and APIs, bloat abstractions, don't clean up dead code... implement a bloated construction over 1000 lines when 100 would do."
"They still sometimes change/remove comments and code they don't sufficiently understand as side effects, even if orthogonal to the task."
You've seen all three. Probably this week.
Someone turned these three observations into a single CLAUDE[.]md file. Four principles, one install, directly addresses each quote:
1./ Think before coding
Don't assume. Don't hide confusion. State ambiguity explicitly. Present multiple interpretations rather than silently picking one. Push back if a simpler approach exists. Stop and ask rather than guess.
2./ Simplicity first
No features beyond what was asked. No abstractions for single-use code. No "flexibility" that wasn't requested. No error handling for impossible scenarios. The test: would a senior engineer say this is overcomplicated? If yes, rewrite it.
3./ Surgical changes
Don't "improve" adjacent code. Don't refactor things that aren't broken. Match the existing style even if you'd do it differently. If you notice unrelated dead code, mention it, don't delete it. Every changed line should trace directly to the request.
4./ Goal-driven execution
Transform "fix the bug" into "write a test that reproduces it, then make it pass." Transform "add validation" into "write tests for invalid inputs, then make them pass." Give it success criteria and watch it loop until done.
This last one is Karpathy's key insight captured directly: "LLMs are exceptionally good at looping until they meet specific goals... Don't tell it what to do, give it success criteria and watch it go."
It's a single file. Drop it into any project.
A single 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 file just hit 15K GitHub stars.
(derived from Karpathy's coding rules)
Andrej Karpathy observed that LLMs make the same predictable mistakes when writing code: over-engineering, ignoring existing patterns, and adding dependencies you never asked for.
If you've used AI coding assistants, you've hit all of these.
But here's the thing:
If the mistakes are predictable, you can prevent them with the right instructions.
That's exactly what this 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 does. You drop one markdown file into your repo, and it gives Claude Code a structured set of behavioral guidelines for your entire project.
This is a big deal.
- Built entirely around prompt engineering for AI coding assistants
- No framework, no complex tooling, just one .md file that shapes behavior
Developers are moving past "use AI to write code" and into "engineer the AI's behavior so the code is actually good."
The Claude Code ecosystem is growing fast, and the best tools in it aren't always software. Sometimes they're just well-crafted instructions.
100% open-source.
I've shared a link to the GitHub repo in the next tweet!
Don't type another prompt into Claude.
Do these 9 simple things first:
1. Download the Claude app
Claude .ai works. But the desktop app is better.
Go to claude .com/download. Install it now.
2. Pick the Right Model
Select Opus 4.6. Turn on Extended Thinking.
Click models → Opus 4.6 → Extended Thinking ON.
3. Use Cowork, Not Chat
Cowork reads your actual files. Chat doesn't.
Point Claude to your project folder.
It reads everything before responding.
4. Build Your Folder Structure
Create 4 folders: ABOUT ME, PROJECTS, TEMPLATES, CLAUDE OUTPUTS.
Example: Who you are, your work, your best templates & where Claude delivers.
5. Write Your "About Me" md File
.md file about who you are, your work, thinking.
Example: Claude reads it before every response. Less prompting, better output.
6. Write Your Anti-AI Style File
A .md file listing every word & pattern you refuse.
Example: Ban "delve," "landscape," "leverage." Claude follows it. You stop sounding like a robot.
To download mine, go here: https://t.co/psB7XxB2Y4.
Don't pay anything. It's free in the welcome email.
7. Start Asking
End prompt with: "Ask me clarifying questions first."
Example: Claude generates a form. You answer. The output jumps 2–3 levels.
8. Set Up Global Instructions
Go to Settings → Profile → Global Instructions.
Example: Write how you write, what you hate & like.
Claude reads this before every single conversation.
9. Edit Your Prompt
Don't send a new message. Edit the first one.
Example: Every follow-up eats tokens. Editing keeps your context clean.
I made over 100+ infographics like this.
If you want to download all of them, just:
1. Go to https://t.co/psB7XxB2Y4.
2. Then enter your work email.
3. It will ask you to pay or not. Don't pay.
4. Wait 2 min. Then open the welcoming email.
5. Click on my Notion library with everything in it.
Disclaimer: you will be subscribed to my newsletter. It's free, and always will be. Some people pay only to join my community & get answers faster.
400,000 readers enjoy it twice a week.
To always stay ahead of the AI curve.
To master AI, before it masters you.
♻️ Help others get better at Claude.
You only need to read four books to truly get what’s going on in ML and data engineering:
- Fundamentals of Data Engineering by Joe Reis
- Designing Data Intensive Applications by Martin Kleppmann
- AI engineering by Chip Huyen
- Designing Machine Learning Systems by Chip Huyen
If you read these four technical books and then read these four books on leadership and soft skills, you’ll be well on your way to massive success!
- Radical Candor
- Atomic Habits
- How to Win Friends and Influence People
- The Body Keeps Score
What books would you recommend?
Stanford just dropped a 457 page report on AI.
It's packed with data on: cost drops, efficiency, benchmarks, adoption.
This report is a cheat code for your career in 2026.
I pulled the most important charts + what they mean for your career: 🧵
Pour une fois un article qui ne raconte pas n'importe quoi à propos de l'emploi et de l'intelligence artificielle. Bien au contraire, il souligne que ce qui change c'est la structure du travail et des tâches dont il est composé, mais que pour l'instant, il n'y a pas de réseau objective de croire à la disparition du travail. Certes et incontestablement, les primo-accédants au marché du travail en plus de difficultés à se placer : c'est le cas en France comme aux États-Unis. Certes également des métiers entiers vont disparaître, mais les décompositions effectuées, métier par métier permettent d'envisager que ces situations soient minoritaires. https://t.co/IGHSZvO1aR
EVERYTHING CLAUDE CODE JUST OPEN SOURCED A FULL AI ENGINEERING SYSTEM.
28 agents, 116 skills, 59 commands, MCP integrations, hooks, rules, and even a built in security scanner.
everyone's building multi-agent systems right now. multiple llms collaborating, checking each other's work, splitting tasks
researchers tested whether this actually helps across 180 controlled configurations. matched token budgets. multiple model families. four different task domains
centralized coordination improved performance by 80.8% on parallelizable tasks. on sequential reasoning tasks, every multi-agent variant made things worse by 39-70%
more agents isn't better. it depends entirely on the shape of the task


















![AndrewYNg's tweet photo. AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]](https://pbs.twimg.com/media/HG7HHJqbsAA3iao.jpg)









![techNmak's tweet photo. Andrej Karpathy wrote something that every Claude Code user has felt but couldn't articulate.
Three quotes. Read them slowly.
"The models make wrong assumptions on your behalf and just run along with them without checking. They don't manage their confusion, don't seek clarifications, don't surface inconsistencies, don't present tradeoffs, don't push back when they should."
"They really like to overcomplicate code and APIs, bloat abstractions, don't clean up dead code... implement a bloated construction over 1000 lines when 100 would do."
"They still sometimes change/remove comments and code they don't sufficiently understand as side effects, even if orthogonal to the task."
You've seen all three. Probably this week.
Someone turned these three observations into a single CLAUDE[.]md file. Four principles, one install, directly addresses each quote:
1./ Think before coding
Don't assume. Don't hide confusion. State ambiguity explicitly. Present multiple interpretations rather than silently picking one. Push back if a simpler approach exists. Stop and ask rather than guess.
2./ Simplicity first
No features beyond what was asked. No abstractions for single-use code. No "flexibility" that wasn't requested. No error handling for impossible scenarios. The test: would a senior engineer say this is overcomplicated? If yes, rewrite it.
3./ Surgical changes
Don't "improve" adjacent code. Don't refactor things that aren't broken. Match the existing style even if you'd do it differently. If you notice unrelated dead code, mention it, don't delete it. Every changed line should trace directly to the request.
4./ Goal-driven execution
Transform "fix the bug" into "write a test that reproduces it, then make it pass." Transform "add validation" into "write tests for invalid inputs, then make them pass." Give it success criteria and watch it loop until done.
This last one is Karpathy's key insight captured directly: "LLMs are exceptionally good at looping until they meet specific goals... Don't tell it what to do, give it success criteria and watch it go."
It's a single file. Drop it into any project.](https://pbs.twimg.com/media/HFxpgTJbYAA1sT-.jpg)