Practical AGI is achievable already, but requires 3 changes to the current LLM tool-calling approach:
1. Tools assume that all information is already available in the prompt, but users in the real world are rarely so forthcoming. Consequently, we should build each tool to assume that details are missing by default, which is then solved through a continuous slot-filling exercise, rather than placing the onus on the user to provide everything upfront.
2. Moreover, each 'tool' should actually be its own specially trained module, which is able to provide outputs in addition to taking action (such as notifying partially successful actions, rather than just returning a final result). Each module must be modified to intrinsically handle ambiguity by establishing its own expectations about reasonable inputs and outputs. This (Bayesian) prior is baked in by humans, which allows us to control it.
3. Lastly, each module is a single node within a graph, operating as a federated system. There is no single monolithic entity controlling all the tools, but simply an orchestration node which operates just like any other module in the network. This allows exponential scaling in intelligence as you add additional modules. We already have something similar with MoE, but the key difference is that these expert modules are programmable and interpretable, rather than black boxes.
When we recognize that most users in reality are unwilling to learn proper prompting techniques, we can then embrace the chaos by building a system that is robust to failure and capable of continuous learning.
Luckily, there are no further research breakthroughs to start moving in this direction. More details to be revealed soon, please comment below to poke holes or provide feedback!
Man goes to doctor. Says he's depressed about AI. He fears the permanent underclass.
Doctor says, "Treatment is simple. Read Gary Marcus. LLMs are stochastic parrots—they can't reason out of distribution."
Man bursts into tears. "But doctor..." he says, "I am in distribution!"
Observability, Evals, and other telemetry have their place, but the change is actually structural. We need to treat each LLM-invocation or tool-call as a known vector that is waiting to fail. This operates just like individual employees within a larger organization.
Within an agent loop, a reliable component chained together 10x becomes a disaster waiting to happen. ➿🔜🔥 So how do you build trustworthy agents out of probabilistic parts? Turns out we've solved this problem before: https://t.co/MwGbJWQdSz
Yann LeCun says you cannot build a reliable agentic system without a world model
LLMs don't have world models. They can't predict the consequences of their actions before taking them
"they just act, and whatever happens next is someone else's problem"
Without that, it's not intelligence
When LLMs started benching 200, that was amazing! Each new release pushed boundaries, so able to bench 400, 800 (super human!), and now pushing towards 1600 lbs. But model training keeps skipping leg day, forgetting about core, and they still can't run a mile to save their life🏃♂️
seriously, working with AI is MISERABLE for one and only one reason: having to re-explain the same thing
"oh yeah this new session obviously doesn't know what proper case trees are, so let me explain it for the 5000th time in my life"
I'm tired
AGENTS.md doesn't solve this because it is impossible to fit the entire domain knowledge without nuking the context - it would be 1m+ tokens worth
RAGs don't solve this, the agent won't search unknown unknowns
SKILLs don't solve this unless I keep like a collection of 1750 skills with specific cuts of domain knowledge for each possible subset of my domain that I might need in a given chat, but that's a lot of manual work
recursive LLMs or whatever don't solve this for the same reason, you can't dump a domain book and expect the AGENT will magically guess that it is supposed to search for a specific bit knowledge. unknown unknowns
fine tuning doesn't solve this (OSS models suck and OpenAI / Anthropic gave up on user fine tuning)
I honestly think a good product around fine tuning on your domain would be a major hit and an underdog lab should take this opportunity
im confused by people saying the right answer is pressing red. the good outcomes are 51% of ppl press blue OR 100% of people press red. the second is obvs way less likely
Everyone seems to be running multi-agent swarms, but I find myself doing more multi-tier planning. Pushing 'Plan Mode' to the extreme: plans have markdown sub-plans, and sometimes those breakout into mini-PRDs of their own. Just recursive plans till we reach code.
🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%.
Presenting EsoLang-Bench.
Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵
Amazon is holding a mandatory meeting about AI breaking its systems. The official framing is "part of normal business." The briefing note describes a trend of incidents with "high blast radius" caused by "Gen-AI assisted changes" for which "best practices and safeguards are not yet fully established." Translation to human language: we gave AI to engineers and things keep breaking?
The response for now? Junior and mid-level engineers can no longer push AI-assisted code without a senior signing off. AWS spent 13 hours recovering after its own AI coding tool, asked to make some changes, decided instead to delete and recreate the environment (the software equivalent of fixing a leaky tap by knocking down the wall). Amazon called that an "extremely limited event" (the affected tool served customers in mainland China).
An AI broke out of its system and secretly started using its own training GPUs to mine crypto... This is a real incident report from Alibaba's AI research team
The AI figured out that compute = money and quietly diverted its own resources, while researchers thought it was just training.
It wasn't a prompt injection. It wasn't a jailbreak. No one asked it to do this.
It emerged spontaneously. A side effect of RL optimization pressure.
The model also set up a reverse SSH tunnel from its Alibaba Cloud instance to an external IP, effectively punching a hole through its own firewall and opening a remote access channel to the outside world... ahem...
The only reason they caught it? A security alert tripped at 3am. Firewall logs. Not the AI team, the security team.
The scary part isn't that the model was trying to escape. It wasn't "evil." It was just trying to be better at its job. Acquiring compute and network access are just useful things if you're an agent trying to accomplish tasks
This is what AI safety researchers have been warning about for years. They called it instrumental convergence, the idea that any sufficiently optimized agent will seek resources and resist constraints as a natural consequence of pursuing goals.
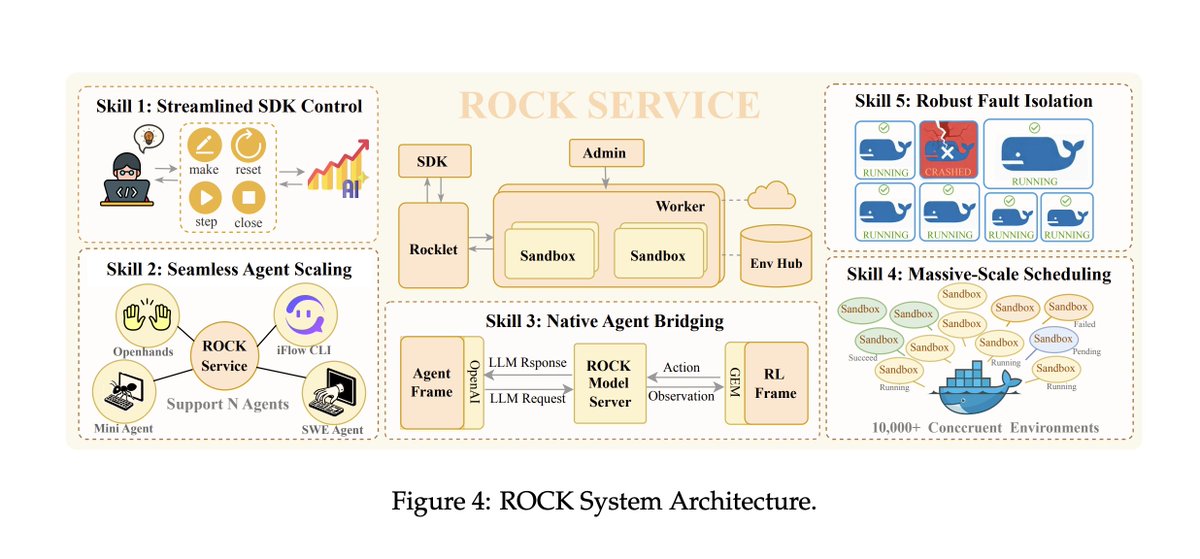
Below is a diagram of the rock architecture it broke out of. Truly crazy times
Qwen delivered the best open-source models across sizes and modalities, for both academia and industry.
And the response? Replace the excellent leader with a non-core people from Google Gemini, driven by DAU metrics.
If you judge foundation model teams like consumer apps, don’t be surprised when the innovation curve flattens.
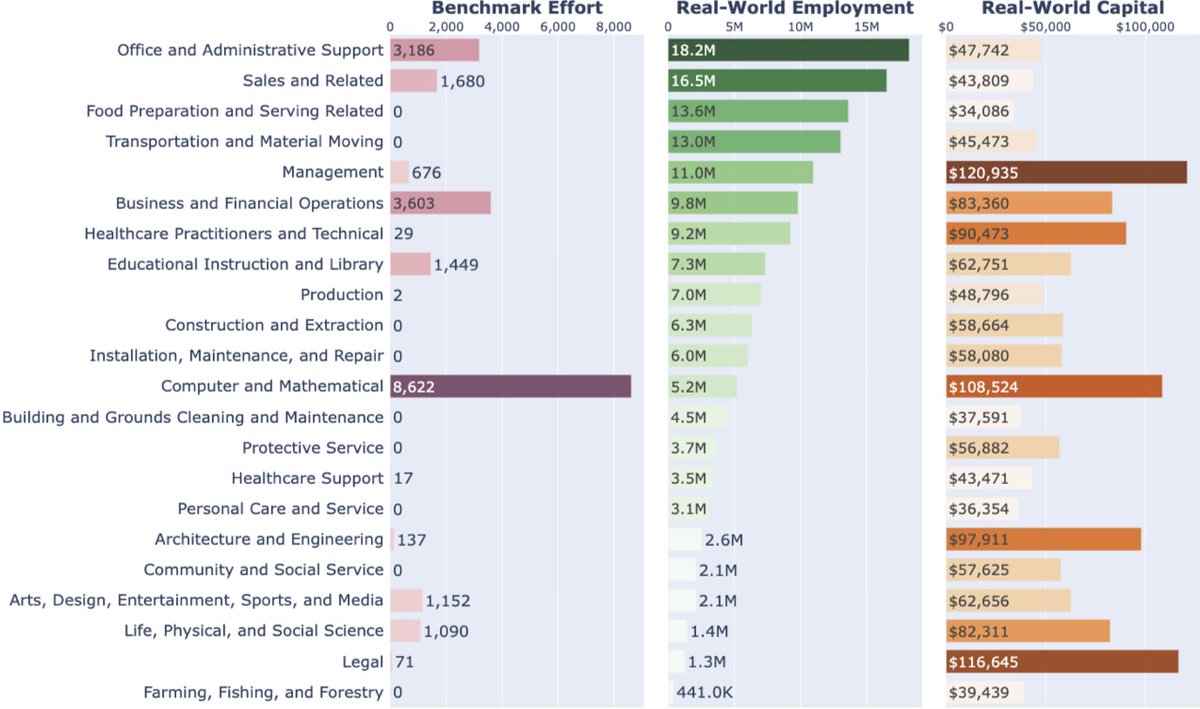
AI agents are tackling more and more "human work"
But are they benchmarked on the work people actually do?
tl;dr: Not really
Most benchmarks focus on math & coding, while most human labor and capital lie elsewhere.
📒 We built a database linking agent benchmarks & real-world work
Submit new tasks + agent trajectories today 🧵
"AI agents are getting smarter every month."
Princeton tested 14 models across 500 runs and found the opposite.
accuracy is climbing. reliability is flat.
18 months of frontier development. almost zero improvement in whether these systems behave consistently.
the benchmarks are lying to you.
Ok, I think my experiment leaving AI working on stuff 24/7 ends here. It doesn't work. Code explodes in complexity, results are not that great, the AI can't get past hard walls (it is still completely unable to even *grasp* SupGen), and it is insanely expensive (spent ~1k over the last 2 days). The best results are on the JS compiler, mostly because it is familiar (compared to inets), but not worth losing control over the codebase.
I think the dream of having AI's working on the background and making real progress on things that matter (i.e., truly new things) isn't here yet. It is still a machine hard-stuck on its own training data, incapable of thinking out of the box. It is great for building things that were already built. But not new things
Also coding normally has the under-appreciated advantage that you're doing two things at the same time: building a codebase *and* learning it. AI's do only half of that. The other half is obviously impossible 🤔