This might sound counter intuitive to you if you’ve been doing Android for the last decade, but makes sense 👇
ViewModels should desirable be scoped to the specific part of the UI that they are relevant to. That is normally not a complete screen, but something smaller.
This is probably the most honest AI architecture breakdown on the internet right now.
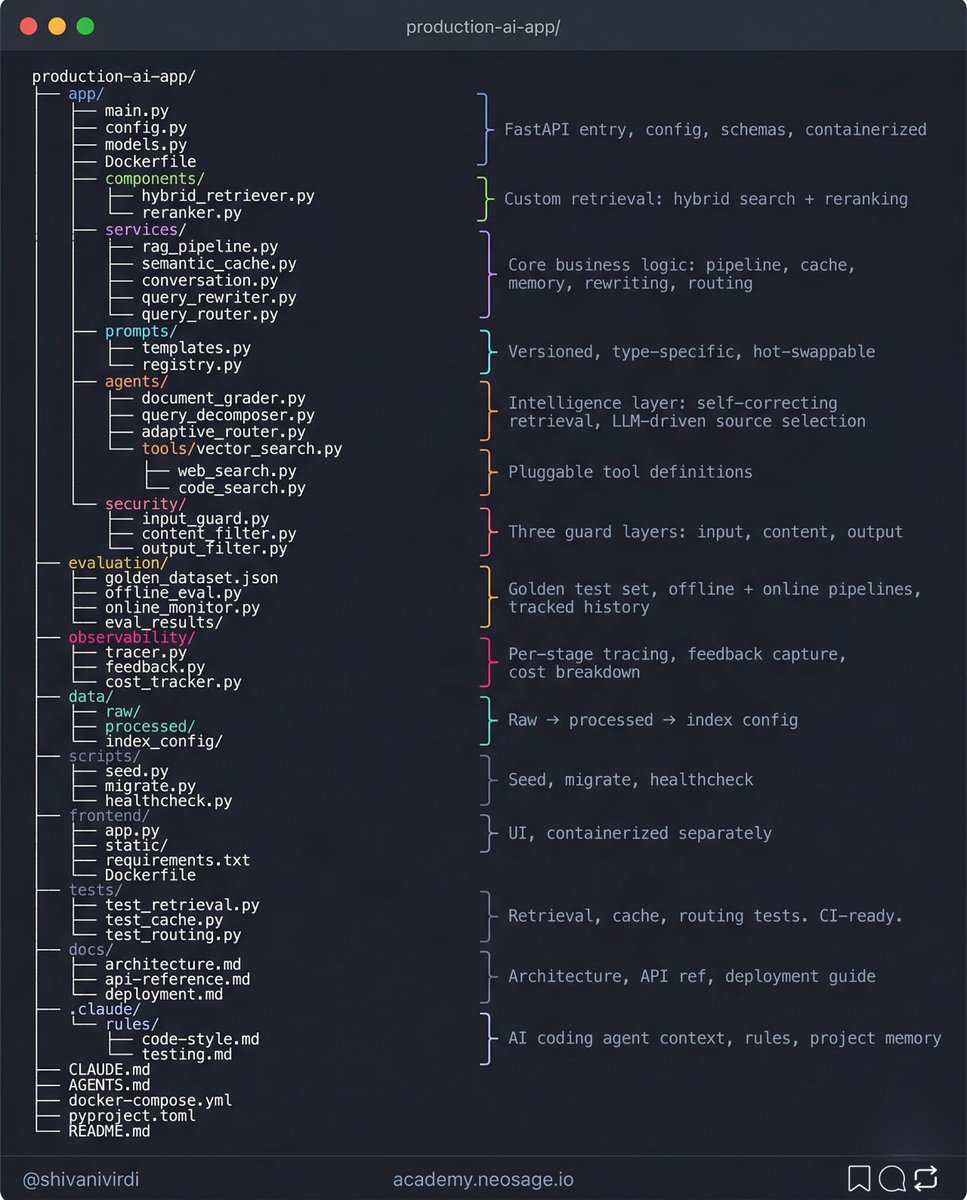
9-layer AI production architecture
services/ - RAG pipeline, semantic cache, memory, query rewriter, router. Not one file. Five.
agents/ - document grader, decomposer, adaptive router. Self-correcting by design.
prompts/ - versioned, typed, registered. Never hardcoded.
security/ - input, content, output. Three guards not one.
evaluation/ - golden dataset, offline eval, online monitor. Most people skip this entire layer and ship blind.
observability/ - per-stage tracing, feedback linked to traces, cost per query.
.claude/ - agent context so your AI coding assistant knows the codebase before it touches a file.
The demo is one file. Production is this.
How to set up Claude Code so it runs like a full dev team:
5 folders. That's the entire system.
1. CLAUDE.md → Memory.
Your repo's constitution. Naming rules, structure, expectations. One global file for all projects, one local file per repo.
2. skills/ → Knowledge.
Reusable workflows Claude auto-invokes by matching the task description. No slash commands. It just knows.
3. hooks/ → Guardrails.
Shell scripts that run before and after every tool call. Block dangerous commands. Auto-lint on save. Ping Slack on deploy. Deterministic. Not AI.
4. subagents/ → Delegation.
Isolated agents with their own context window. A code reviewer that only sees the diff. A test runner with custom permissions. Keeps your main session clean.
5.plugins/ → Distribution.
Bundle the whole system into one install. Every teammate gets the same skills, same hooks, same agents. Aligned from day one.
This is the Agent Development Kit. Five layers, one stack.
To learn how and get the full Claude guide:
1. Go to https://t.co/xViEAXTX7v
2. Subscribe free by just writing your email.
3. Open my welcome email and get the free resources.
Repost ♻️ to help someone in your network.
Every Skill is a tax. Every token is paid by every user, every session.
The test for every sentence: "Would the agent get this wrong without this instruction?" If no, delete it. If it's easy to explain, the model already knows it.
Skills that recapitulate training data or system prompts are pure cost with no benefit.
Good read.
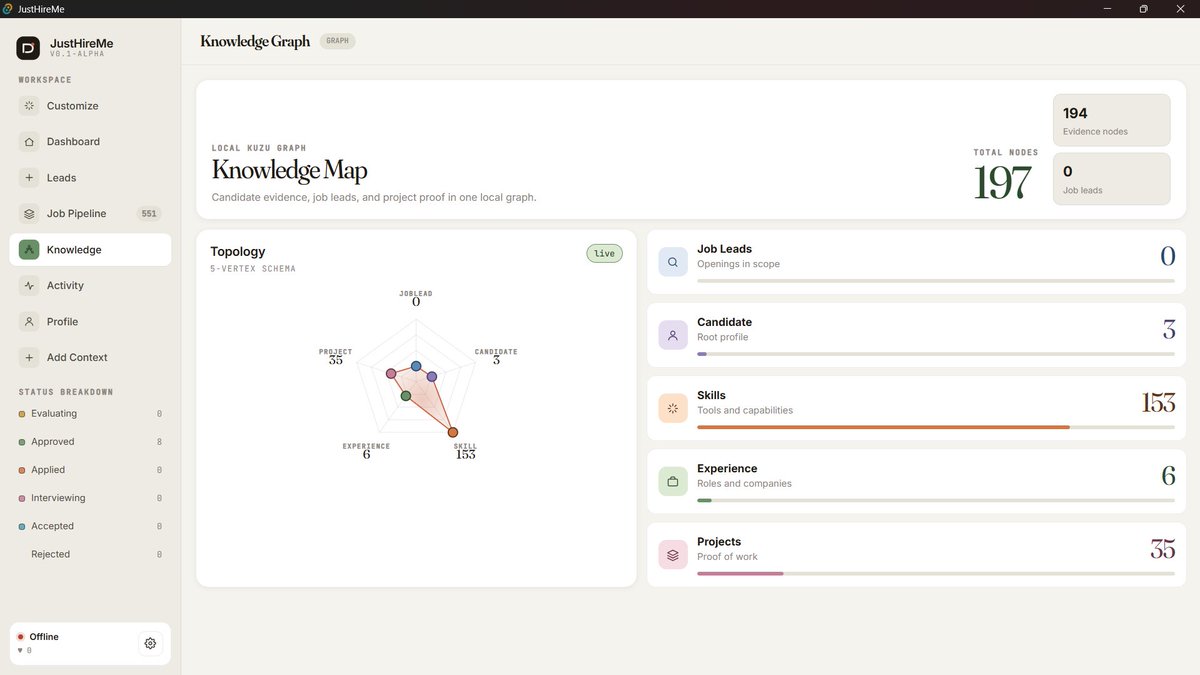
I’m open sourcing JustHireMe 🚀
A local-first Agentic AI desktop app I’ve been building to make job searching more intelligent, transparent, and user-controlled.
GitHub: https://t.co/5R8mxCDSiR
The current job search process is broken.
Candidates spend hours scrolling through:
stale job posts
irrelevant roles
spammy listings
senior-only positions
repeated listings across platforms
jobs with almost no useful context
And most AI job tools either scrape too broadly, rank opportunities like a black box, or try to automate applications without giving the user enough control.
I wanted to build something different.
JustHireMe is designed as a personal job intelligence workbench.
Instead of blindly applying everywhere, it helps users discover better opportunities, evaluate them against their real profile, and generate tailored application materials while keeping sensitive career data local.
What it can do:
Ingest resume/profile data
Build a local professional profile graph
Discover job leads from multiple sources
Filter out low-quality or irrelevant postings
Score roles based on explainable fit
Match jobs using graph + vector search
Generate tailored resumes
Generate cover letters
Draft cold emails
Draft LinkedIn outreach messages
Track leads in a local CRM-style pipeline
Keep the user in control through a human-in-the-loop workflow
The main principle behind the project is:
More signal.
More explanation.
More local control.
Less blind automation.
The tech stack:
Tauri for the desktop shell
React + TypeScript for the frontend
Python + FastAPI for the backend sidecar
SQLite for local lead tracking
KuzuDB for graph-based profile modeling
LanceDB for vector search and semantic matching
Playwright for experimental browser automation
One of the biggest goals is privacy.
Your resume, career history, generated documents, job leads, application notes, and API keys should not have to live on someone else’s server by default.
JustHireMe is built around a local-first architecture so users can keep ownership of their data while still benefiting from modern AI workflows.
Another major goal is explainability.
I don’t want an AI system that just says:
“This job is a good match.”
I want it to explain:
which skills matched
which projects support the application
what gaps exist
why a role was filtered out
why a role deserves attention
what to highlight in the resume or cover letter
That matters because job search is not just a productivity problem.
It is personal.
It affects confidence.
It affects opportunity.
It affects people’s careers.
The project is currently in alpha, but the foundation is in place.
I’m looking for contributors interested in:
Agentic AI
AI agents
workflow automation
job source adapters
web scraping
ranking algorithms
GraphRAG
vector databases
semantic search
resume parsing
document generation
local-first software
privacy-first AI
UI/UX
testing and documentation
If you’re a developer, designer, AI engineer, student, or someone who has felt the pain of modern job searching, I’d love your feedback, ideas, issues, PRs, or even just a star ⭐
Repo: https://t.co/5R8mxCDSiR
Let’s build a better, more transparent job search system together.
#OpenSource #AgenticAI #AIAgents #RAG #GraphRAG #Python #FastAPI #ReactJS #TypeScript #Tauri #VectorDatabases #JobSearch #CareerTech #Automation #PrivacyFirst
ANTHROPIC JUST RELEASED THE OFFICIAL PLAYBOOK FOR BUILDING A COMPANY WITH CLAUDE CODE.
30 minutes. free. from the engineers who built it.
Bookmark this before you forget.
CEO: 1 human. Employees: AI agents. Operations: fully automatic.
The zero-headcount company is no longer a joke.
This guy literally built an ENTIRE operating system with Claude Code
now he’s showing exactly how he did it.
he dropped a 2+ hour masterclass and broke down the frameworks behind it, shared a free GitHub repo so you can start immediately: (save this)
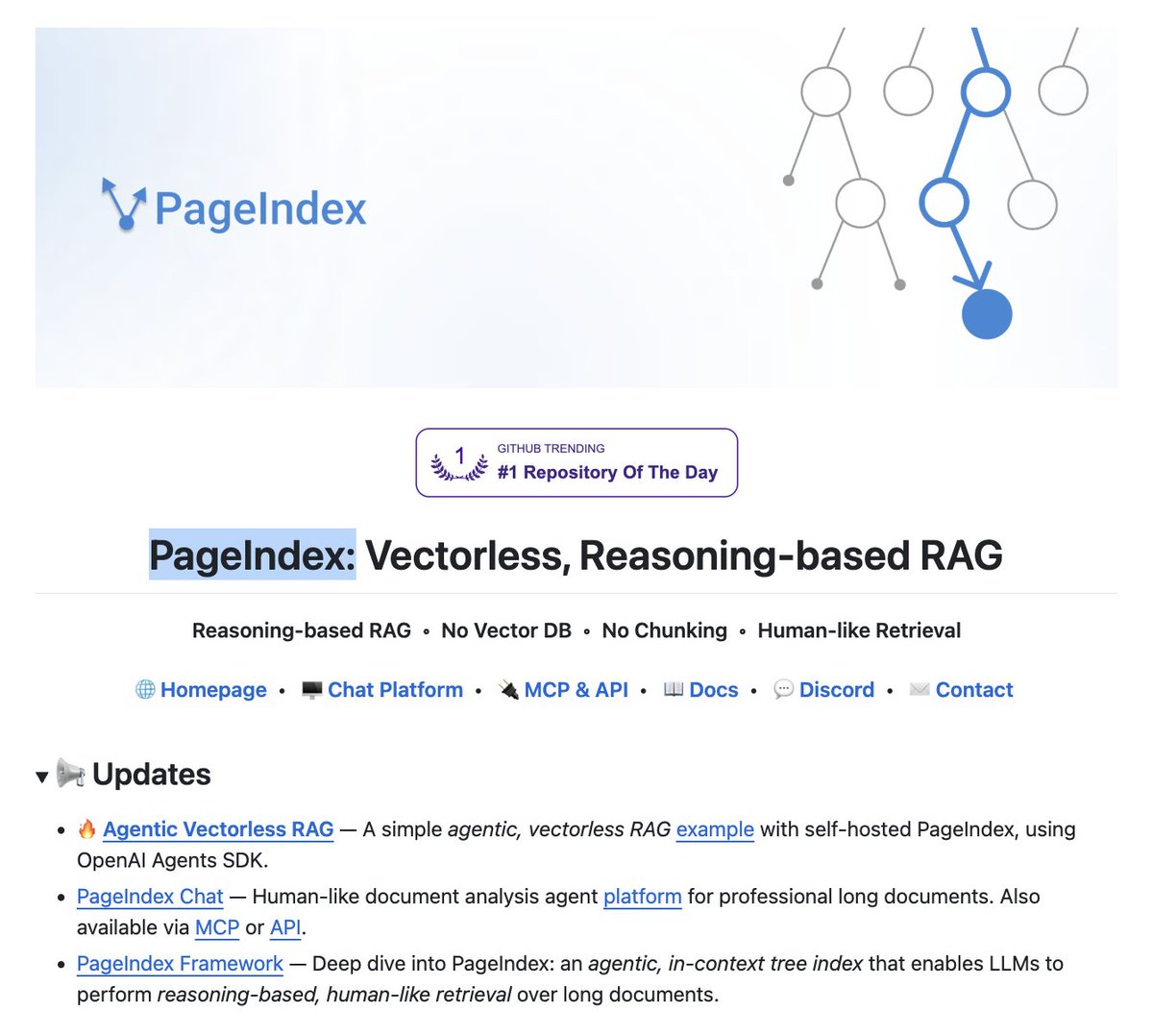
The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
ANDREJ KARPATHY COULD HAVE CHARGED $2,000 FOR THIS COURSE.
He put it on YouTube.
The full training stack. Tokenization. Neural network internals. Hallucinations. Tool use. Reinforcement learning. RLHF. DeepSeek. AlphaGo.
3 hours of the most comprehensive LLM education that exists anywhere at any price.
Not how to use the tools.
How the entire system was built from the ground up and why it behaves the way it does.
The engineers who understand this build things the ones who only use the tools cannot even conceive of.
The gap between those two groups is not 3 hours.
It is everything those 3 hours quietly unlock for the rest of your career.
his “dev team” costs $100/month and ships faster than a $50k/month engineering squad
made $34k/month
5 mac minis stacked on a rack next to pink dumbbells
each one running a specialized AI agent with its own role
they don’t talk to each other, don’t share context, don’t conflict
just ship code 24/7 while he sleeps
the setup looks ridiculous until you hear the numbers
5 mac minis stacked vertically in some kind of custom holder, cables everywhere, power meter showing real-time electricity usage
next to it: a laptop with a dashboard showing all agents working
on the shelf above: pink dumbbells because why not
this man built a full engineering team for the cost of one junior dev’s weekly coffee budget
here’s what each mini does:
mac mini 1 - the architect
> reads product requirements, breaks down features into tasks
> writes technical specs before anyone touches code
> has its own CLAUDE.md that says “you never write code, only plans”
mac mini 2 - the coder
> takes specs from the architect, writes implementation
> full tool access, can create files, run builds
> its CLAUDE.md says “you never make architecture decisions, just execute the plan���
mac mini 3 - the reviewer
> reads every PR with security-first mindset
> flags issues, checks test coverage, suggests improvements
> its CLAUDE.md says “you never write code, only review it”
mac mini 4 - the tester
> writes unit tests, integration tests, e2e tests
> runs the full test suite before anything merges
> its CLAUDE.md says “nothing ships without your approval”
mac mini 5 - the ops
> handles deployment, monitors production, fixes CI when it breaks
> the only agent with access to infrastructure configs
> its CLAUDE.md says “you never touch application code”
clean separation
coder never sees deployment secrets
reviewer can’t push code even if it wanted to
ops doesn’t care about business logic
they communicate through a shared task queue, not through each other
no context bleeding, no confusion, no conflicts
the math is disgusting:
> 4 retainer clients paying $7-10k/month
> monthly revenue: $34k
> 5x claude subscriptions: $100
> electricity: $15
> profit margin: 99.6%
$115/month for a full engineering team that works nights and weekends
his output last month:
> 847 commits across 3 client projects
> 12 features shipped
> 2 full product launches
> 0 production incidents
he reviews PRs in the morning, gives feedback, agents iterate during the day
by evening: ready to merge
he’s running a one-man agency that outdelivers shops with 10 people
the clients have no idea
they just see features shipping faster than expected
Two Anthropic engineers spent 24 minutes exposing every Claude Code feature you didn't know existed.
Most people will scroll past this. Don't be most people.
Claude Code used 3x fewer tokens with one change:
- Before: 10.4M tokens · 10 errors · $9.21
- After: 3.7M tokens · 0 errors · $2.81
I used Insforge Skills + CLI as the backend context engineering layer for Claude Code (open-source and local).
Repo: https://t.co/ACu2d1oaJ1
The creator of Claude Code teaches more about vibe-coding in 30 minutes than most tutorials do in hours.
Save this — it'll change how you build forever.
AVD (Animated Vector Drawables) exist since Android 5.0 - still underused
Devs just don’t know where to get good animated icons
We fixed that
Built together with @romankhrupa
Vector Motion Kit - ready-to-use animated icons for Android
More coming
https://t.co/JXhNo2f366
Someone gave Claude Code permanent memory.
→ 95% fewer tokens per session
→ Never hits context limits
→ Picks up exactly where you left off
→ 46,000 GitHub stars in 48 hours
One command: `npx claude-mem install`
Completely free. Community-built. Not Anthropic.
Claude Code is exceptional. It just kept forgetting everything.
This fixes that.
The reason Claude feels dumber isn't the model.
It's 3 lines you never added to your settings.
Claude doesn't decide how hard to think on its own. It reads signals. Most people give it none.
Go to Settings → Profile → Custom Instructions and paste this:
"Always reason thoroughly. Treat every request as complex unless I say otherwise. Never optimize for brevity at the expense of quality."
That's it.
The Claude you were frustrated with and the Claude you actually need are the same model.
I share updates like these in my free AI community on WhatsApp.
Join here 👇
https://t.co/dK13aGrpqi
Stop telling Claude: "build this"
Stop telling Claude: "write code"
Stop telling Claude: "fix this bug"
You're using a staff-level AI like a junior intern.
Claude performs best when you give:
• role
• constraints
• architecture expectations
• output format
• real-world context
Here are 10 production-grade Claude prompts you can copy-paste: