13/
14/
The hammer is sitting right there.
Most leaders will spend another year insisting it’s a deployment problem so they don’t have to pick it up.
That’s the work. Most people are still calling it something else.
Full piece 👇
https://t.co/M1e0upVpLq
1/
88% of enterprise AI agent pilots never reach production.
The industry calls this a deployment problem.
It isn’t. It’s a workflow redesign problem. And most leaders refuse to pick up the hammer.
🧵
#buildinpublic#ai
12/
I build and deploy agents for commercial real estate finance — 40-year-old ERPs, real money moving, compliance that doesn’t forgive.
The hardest part has never been the agent. It’s the decades of process built around manual coordination.
The teams that win rebuild themselves around the machine.
Jeff Bezos has owned the internet for the last 24 hours with his superbly sharp wisdom and insights.
His take on what AI will do is, my POV too of what will happen! https://t.co/fZJEB77BpB
Agentic AI is everywhere right now. But very few teams can explain why their agents behave the way they do, or how to systematically make them better.
People often describe traces as the “codebase” for agents. They show how an agent thinks and what it did at every step. As agents take on more tools, sandboxes, and skills, their paths multiply. That makes them harder to reason about and harder to improve. Static prompts don’t scale when every run looks different.
At @glean, we use traces as part of the learning and memory loop, not just logging. Trace learning lets agents learn from real usage, adapt to edge cases, and get better without model fine-tuning or long instruction sets. The goal isn’t to replay old runs, but to extract the signal that helps the agent make a better decision next time.
In the enterprise, tool strategies are never one-size-fits-all. Each company wires systems together differently, defines its own sources of truth, and has its own rules of engagement. Treating this as generic is both a security risk and a quality problem, because it ignores how work actually gets done. Work is also personal. The systems people touch, the updates they make, and the templates they use all vary.
So we built learning at two levels:
- Enterprise-level strategies for how tools and workflows operate
- User-level preferences for how work actually gets done
Traces give us a way to understand and shape agent decision-making, and to create a feedback loop that compounds over time.
If agentic AI is going to move beyond impressive demos to reliable day-to-day work, this kind of trace-driven learning is essential. It’s one of the ways we’re building self-learning agents that can execute real work, at scale.
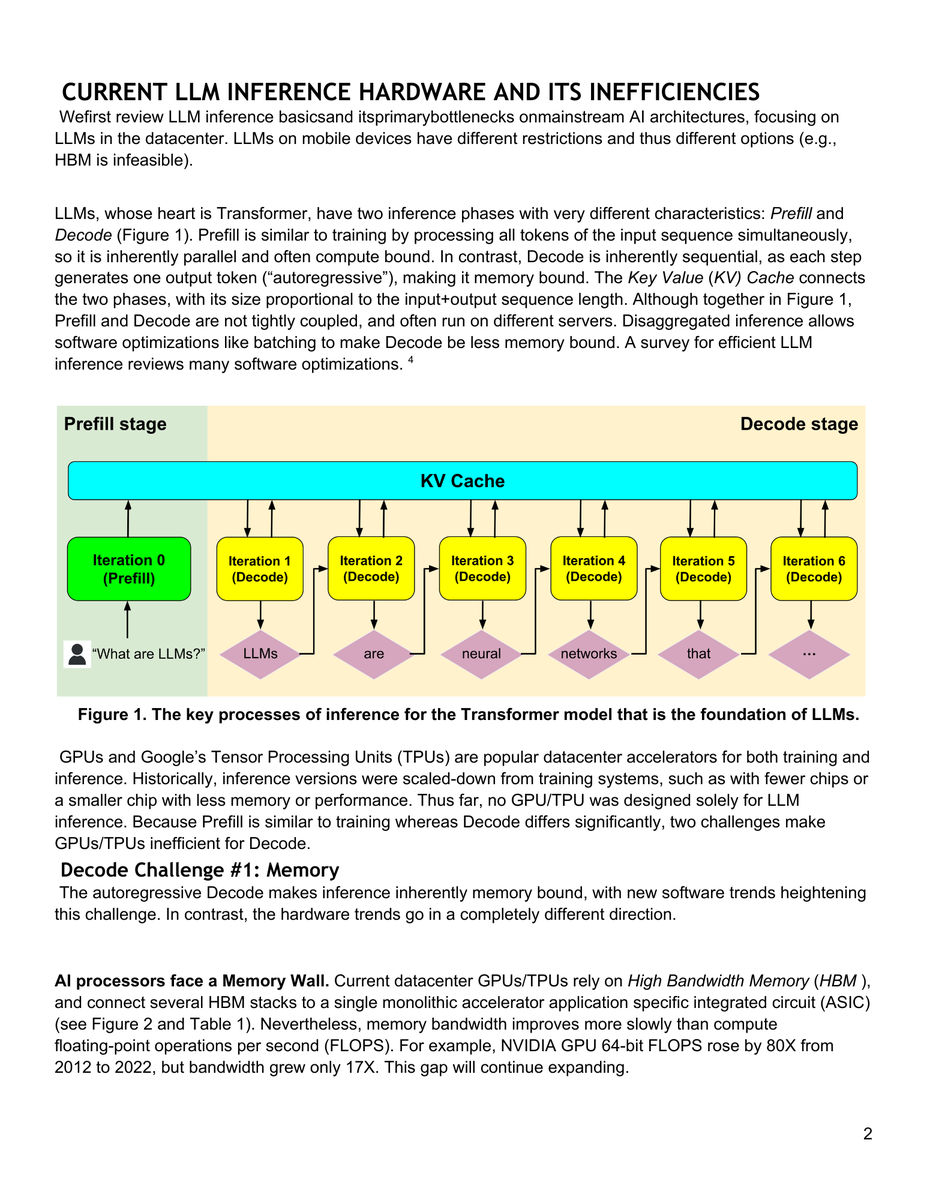
🚨 BREAKING: A Google researcher and a Turing Award winner just published a paper that exposes the real crisis in AI.
It's not training. It's inference. And the hardware we're using was never designed for it.
The paper is by Xiaoyu Ma and David Patterson. Accepted by IEEE Computer, 2026.
No hype. No product launch. Just a cold breakdown of why serving LLMs is fundamentally broken at the hardware level.
The core argument is brutal:
→ GPU FLOPS grew 80X from 2012 to 2022
→ Memory bandwidth grew only 17X in that same period
→ HBM costs per GB are going UP, not down
→ The Decode phase is memory-bound, not compute-bound
→ We're building inference on chips designed for training
Here's the wildest part:
OpenAI lost roughly $5B on $3.7B in revenue. The bottleneck isn't model quality. It's the cost of serving every single token to every single user. Inference is bleeding these companies dry.
And five trends are making it worse simultaneously:
→ MoE models like DeepSeek-V3 with 256 experts exploding memory
→ Reasoning models generating massive thought chains before answering
→ Multimodal inputs (image, audio, video) dwarfing text
→ Long-context windows straining KV caches
→ RAG pipelines injecting more context per request
Their four proposed hardware shifts:
→ High Bandwidth Flash: 512GB stacks at HBM-level bandwidth, 10X more memory per node
→ Processing-Near-Memory: logic dies placed next to memory, not on the same chip
→ 3D Memory-Logic Stacking: vertical connections delivering 2-3X lower power than HBM
→ Low-Latency Interconnect: fewer hops, in-network compute, SRAM packet buffers
Companies that tried SRAM-only chips like Cerebras and Groq already failed and had to add DRAM back.
This paper doesn't sell a product. It maps the entire hardware bottleneck and says: the industry is solving the wrong problem.
Paper dropped January 2026. Link in the first comment 👇