DevOps Diaries:
Do you know why your AWS EBS volumes might be costing you 3x more than they should? Or why your database feels slow despite "enough IOPS"?
I recently dug into EBS volume types after a prod incident where our RDS instance was throttling - and we were still on gp2. Turns out, there's a lot more to EBS than just "pick the default and forget."
Let me share what I learned about how EBS volumes actually work:
When you provision an EBS volume, you're not just getting disk space. You're getting three separate performance characteristics that AWS meters independently:
1. Throughput (MB/s) - How much data can flow per second
2. IOPS - How many read/write operations per second
3. Storage (GB) - The actual disk space
Here's the gotcha -----> In gp2 (the old default), IOPS scales with size. So if you need 10,000 IOPS, you MUST provision ~3,334 GB even if you only need 100 GB of storage -----> You're paying for 3,234 GB you don't use.
But with gp3, these three are independent. You can provision:
- 100 GB storage
- 10,000 IOPS
- 500 MB/s throughput
And pay only for what you actually need.
Practical Use Cases for Understanding This:
1. Database workloads - High IOPS needs, moderate storage → gp3 with custom IOPS saves 60-70% vs gp2
2. Log aggregation - High throughput, low IOPS → gp3 with boosted MB/s, baseline IOPS
3. Archive storage - Low everything → gp3 baseline (3000 IOPS, 125 MB/s) is enough
Real Example from Our Prod:
- Old setup (gp2): 2 TB volume = $200/month (to get 6,000 IOPS)
- New setup (gp3): 500 GB + 6,000 IOPS provisioned = $65/month
- Same performance, 67% cost reduction
Note:
There's also io2 Block Express for extreme workloads (256,000 IOPS!), but unless you're running a massive database that's actually bottlenecked on storage, gp3 is the sweet spot for 95% of use cases.
- As always, the comment section is yours:- share your insights, point out corrections, or drop related article links. Let's learn (and unlearn) together 😊
#AWS #DevOps #CloudComputing #SRE #devopsinterview
#DevOps Diaries #134
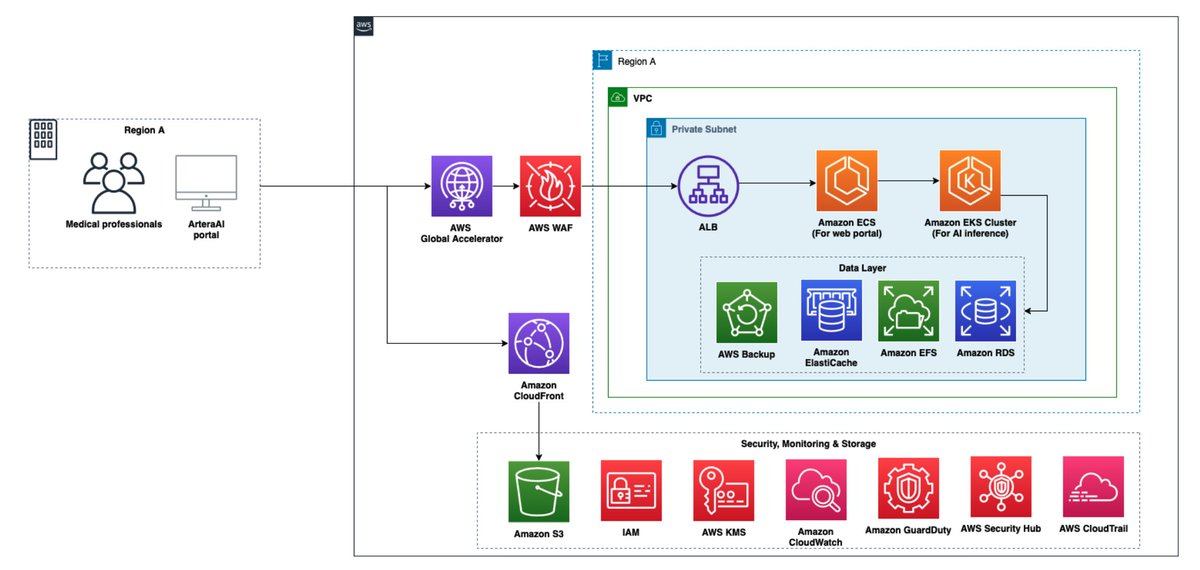
Just read the AWS Architecture Blog on Artera’s prostate cancer AI solution.
They take 8GB whole-slide biopsy images, split them into tens of thousands of patches, and run computer vision + multimodal AI on EKS - delivering results in 1–2 days instead of 6 weeks of current available solutions, while keeping the tissue intact for further testing, interesting to see AI is solving reallife pain.
Tech Stack:
1. EKS for scalable ML inference/training
2. ECS for clinician web portal
3. S3 + EFS for storage & data locality
4. Global Accelerator sits in front of ALB — routes traffic over AWS global network to cut latency for large file uploads/downloads and improve global availability (HIPAA compliant).
Clean example of EKS + global networking for life-critical AI workloads.
Full blog link in comment-
#AWS #EKS #GlobalAccelerator #Kubernetes #DevOps #AI
#DevOps Diaries #133
#Kubernetes
Voluntary disruptions = things you control:
- Node drains
- Cluster upgrades
- Manual pod deletions
Involuntary disruptions = things you don't:
- Node crashes
- Hardware failures
- OOM kills
Most of the teams never sets up Pod Disruption Budgets (PDB) in Kubernetes. Until production goes down during a node drain.
One maintenance event → all pods evicted → full outage.
A PDB prevents exactly that. It tells Kubernetes: keep at least 1( or n number of pods) pod alive, no matter what.
Things that we miss:
- PDBs don't protect against node crashes. Only voluntary disruptions.
#linux #devopsinterview #containers
#RandomThoughts
Right now most setups look like:
Prompt → LLM → Hope it works
That’s not scalable. The next big wave?
AI Agent Orchestrators
Systems that will:
• Coordinate multiple agents
• Manage tools, APIs, permissions
• Handle retries, failures, fallbacks
• Maintain memory & context
• Add guardrails + observability
This is already started but not matured yet.
#AI #DevOps #LLM #Agents #TechTrends
#DevOpsDiaries #132
Deleted an AWS resource by mistake?
In theory, it’s not recoverable.
But in practice (at least from my experience), if you raise an AWS support ticket immediately, the support team can sometimes restore the service.
My guess is the resource isn’t deleted instantly in the backend. There seems to be a buffer period before the actual cleanup happens, allowing support to cancel the deletion.
This isn’t officially documented, and AWS never guarantees recovery - but it has worked in several cases.
If anyone from AWS knows how this actually works internally, would love to hear it.
As always, the comment section is yours.
#devops #sre #aws
I can see two types of engineers in the office now:
1. Prompt the AI agent and, while it’s completing the task, scroll phone / LinkedIn / personal stuff
2. Prompt the AI agent and, while it’s running, start another task or prompt in parallel
The real question:
Is AI improving my productivity or just filling idle time?
#ai #devops #startup #productivity
#DevOps Diaries #131
Heard of BridgeSwarm?
When people hear “AI coding assistant”, most of us instantly think of one single agent like Cursor or Claude. I’m not against them - they’re fast and super helpful for quick stuff.
But one agent is NOT enough when the task gets real. Example scenario: You’ve got a messy codebase to refactor + new features to add + tests to run + proper review needed.
• Back-and-forth chatting with one AI
• Context gets lost
• Code quality slips
• Takes forever Be honest… you’ve been there, right? 😄
Then I saw this awesome tool that’s actually solving the real issue: BridgeSwarm from BridgeMind. ==> Instead of one lone AI, you spin up a full team — coordinator, builders, reviewers, scouts - all working in parallel like senior engineers. They divide the work, own files, review each other’s code, and ship changes with almost zero chatter.
Result? Complex tasks get done way faster and cleaner. That’s the future of getting stuff done.
@bridgemindai 👊
As always, the comment section is yours. Have you tried multi-agent setups yet? Drop your wins (or fails) below. Let’s learn together. 📷 #DevOps #AI #Coding #BridgeSwarm #MultiAgent #VibeCoding #SRE
#DevOps Diaries #130
If I had to recommend ONE single AWS service you should learn first… my answer is always IAM.
Without proper IAM, nothing else in AWS really matters.
I was recently talking to a friend who strongly argued for VPC first. His point was is okay as VPC is important.
But here’s the reality:
You can build and run services without a custom VPC( lots of managed services ).
But without IAM? You’re completely stuck. You can’t create resources, you can’t assign permissions, you can’t secure anything, and every single service becomes useless.
IAM is the foundation of AWS security and access control. Everything else sits on top of it.
So my strong advice:
Don’t just “learn” IAM ==> Be a Master in IAM
Understand:
- Users, Groups, Roles & Policies
- IAM Identity Center (SSO)
- IAM Access Analyzer
- Least Privilege principle
- Policy evaluation logic
- Resource-based vs Identity-based policies
Trust me : the time you invest in mastering IAM will save you hundreds of hours of debugging weird permission errors later.
What’s your #1 AWS service you recommend learning first? Drop it in the comments
As always, the comment section is yours - correct me / drop your favourite devops stories, Let’s learn together.
#AWS #Cloud #IAM #devopsinterviews #security
#DevOps Diaries #129
You’re setting up CloudFront and want to add a WAF on it for protection!
You create the Web ACL in your usual region (us-west-2, eu-west-1, wherever you normally work) and try to attach it to the distribution. ---> You'll get error. “Invalid Web ACL” or “Web ACL not found”.
WTF? CloudFront is global, right? Should work anywhere.!!
Here’s the catch (and it bites everyone once):
AWS only lets you attach WAF Web ACLs that were created in us-east-1 (N. Virginia) to CloudFront distributions.
Even if your origin is in Mumbai or Frankfurt, the WAF itself has to live in us-east-1.
Lesson: Always spin up your CloudFront WAFv2 Web ACLs in us-east-1. . Don’t waste 30 minutes debugging like I did last week
Saves headaches, keeps your pipeline clean.
As always, the comment section is yours — hit me if you’ve seen this, or drop your favourite devops stories,
Let’s learn together.
#AWS #CloudFront #WAF #DevOps #Cloud #SRE #devopsinterviews
#DevOps Pulse #115
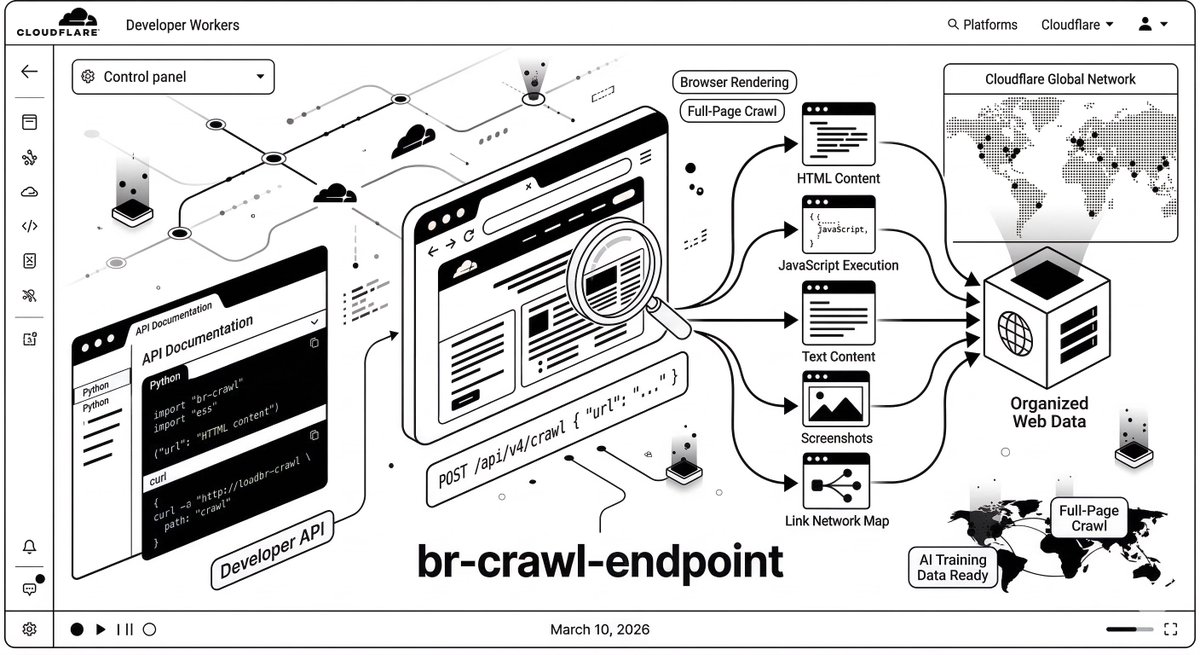
Cloudflare quietly dropped a new Browser Rendering /crawl endpoint yesterday.
With a single POST request to
https://t.co/ePoNUhuUTV
you can start from a URL and it will:
• Auto-discover the entire site (sitemaps + internal links)
• Render pages using a headless browser
• Return structured output in **HTML, Markdown, or clean JSON
It runs as an async job, so you trigger it once and poll for results later.
This basically replaces the usual stack of:
Lambda + headless browser + crawler + queue + storage.
Super useful for:
• RAG pipelines
• Website indexing
• Automated documentation extraction
• AI training datasets
DevOps engineers no longer need to build a spider from scratch.
#Cloudflare #DevOps #SRE #RAG #Automation
@danielepolencic The way which I like is, people create specialized agents and orchestrating it to do vibe coding , like one agent act as architect, another one only for strict PR review another for QA act- , then they orchestrate the flow, Boom!!!]