At @ThriveHoldings, we built a product with @OpenAI to automate tax prep for the 30+ accounting firms we own across the country.
This season, it processed 7k+ returns. But what I think is more interesting is that the product meaningfully self-improved as accountants used it.
Today, Pace has raised a $46 million Series B, co-led by @ThriveCapital and @Sequoia, with participation from @emergencecap and @pruvencapital, to help our customers insure more of the world’s risk.
@pacecom agents have completed more than 250,000 critical insurance operations, growing 3x every quarter. The world’s leading insurers, like Prudential, WTW and Convex, trust Pace to scale back-office operations.
60% of the world's losses last year went uninsured. Closing this $9 trillion protection gap starts with AI-native operations.
SYMPOSIUM IS BACK?! In Toronto! 🍁
Calling ALL builders, makers, artists, engineers!
Meraki Symposium 2026 x Toronto Tech Week - May 29th @ William Doo auditorium, UofT
mark your calendars, set 3 alarms, don't be late...
the next social network is a prediction market where your feed is ranked by accuracy not engagement. the person who is right 80% of the time gets seen while the person who is loud gets buried
SkyRL now supports end-to-end vision-language post-training, from SFT to agentic RL, and adds vision model support to SkyRL’s Tinker interface! Existing multimodal cookbooks, e.g. VLM classification, work out of the box:
SCOOP: Cursor plans to use xAI's infrastructure to train its Composer 2.5 coding model, according to people familiar with the matter.
Cursor will use tens of thousands of xAI's GPUs, they said.
the harness vs model moat debate is missing a third layer: serving infrastructure. you can have the best harness and the best model but if your inference is slow or expensive at scale the product dies anyway. sora had arguably the best video model and a disney deal and still got killed by GPU economics last week. the real stack is model + harness + serving, and the companies that win long term will be the ones who own all three layers. right now most startups pick one and pray the other two stay commoditized @Yuchenj_UW
hi people in berkeley/sf,
i run a paper reading group on interpretability (and other deep learning topics) at our amazing group house in berkeley. we'd love for more curious people to join us.
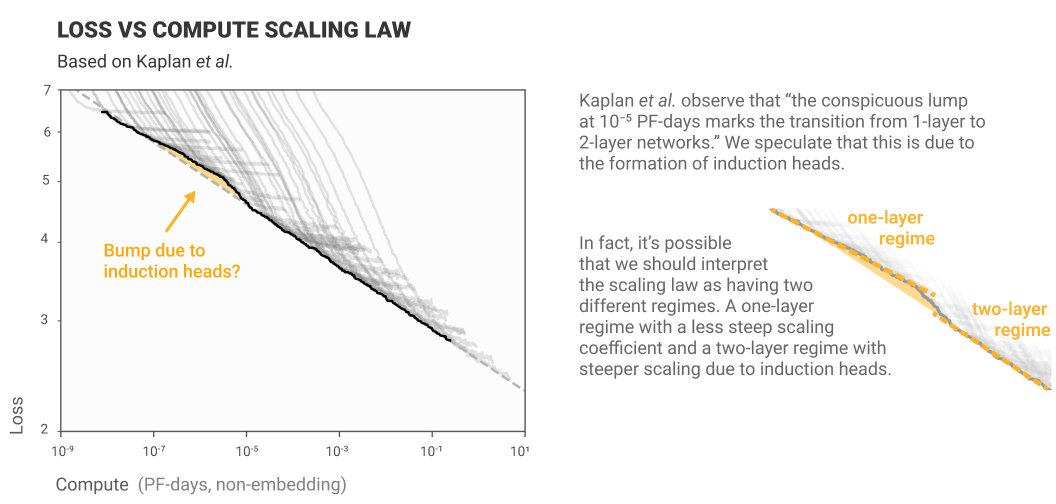
this wednesday (4/1), we're discussing anthropic's "in-context learning and induction heads" paper which shows how induction heads are responsible for majority of in-context learning in transformers.
if you're interested in joining, pls reach out! no interp background required as long as you're just a curious person.
ALS has gradually taken away Kenneth’s ability to speak. Through Neuralink’s VOICE clinical trial, he’s exploring how a brain-computer interface designed to translate thought to speech could help restore autonomy in his daily life.
Watch to learn more:
Luckin Coffee (Chinese Starbucks) acquired Blue Bottle retail operations for $400M from Nestle, who had bought a majority at a ~$700M valuation back in 2017. Blue Bottle had raised from True, Index and GV.
Nestle will keep the FMCG brand.
Luckin was delisted from the Nasdaq in 2020 when it came out that they had fabricated $310M of sales, and paid a $180M fine. They seem to have turned it around and might get relisted after 5 years in the penalty box. It’s trading at ~$10B on OTC markets
https://t.co/VqRjbMQ38f