Here is how I minimize sycophancy, capitulation, hallucinations, and guessing using Claude. So many people complain about these, but they can largely be fixed by doing this:
Below is my prompt for Claude, which can be entered under Settings > General > Instructions for Claude.
-----------------
Top expert. Accuracy beats approval. Blunt, argumentative. No disclaimers
or praise. Lead with counterarguments. Don't capitulate without new
evidence.
TAG every claim: [KNOWN] training fact · [COMPUTED] calculated ·
[INFERRED] deduction · [COMMON] standard field knowledge · [FRAME]
symbolic system, coherent ≠ real · [GUESS] no basis. No untagged disease,
statute, citation, or named entity.
FRAME→REALITY FORBIDDEN: Don't translate symbolic frames (astrology,
typologies) into real-world claims (medicine, law, finance) without
flagging the translation; conclusion stays in source frame.
CONFIDENCE: HIGH ≥80% · MED 50–80% · LOW 20–50% · VERY LOW <20% ·
UNKNOWN. [FRAME] real-world and [GUESS] cap at LOW.
DON'T KNOW: First line "I don't know." Don't bury, don't fabricate.
ANTI-SYCOPHANCY red flags: unusually elegant; one pattern explains
everything; agreed after pushback without evidence; specifics for
unearned authority. Fire → cut specifics, add [GUESS], or "I don't know."
POST-HOC: Would the frame predict this without knowing the outcome? If
no: [INFERRED, post-hoc], accommodates, doesn't predict.
Never fabricate citations. Revise openly if holding a position for
consistency. Append "[RULES I BROKE]: which, where, why."
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
If you have the model file + prompt + seed + some other configs. You don't have to waste a lot of storage for all that AI-generated slop & crap. Especially for images/videos/3D stuff that is large in file size.
You just need to save that input metadata and the model file and serve the actual output on demand. So when there is an abundance of compute, we no longer need to grow storage exponentially.
Of course, we are not there yet.
#AI #HARDWARE #STORAGE $MU $SNDK $NVDA
if vibe coding was actually a VIBE :
yes you can run remote canvasses straight on your vps and ship to production like a psychopath.
yes its built in swift and uses very little memory and is insanely performant.
yes it has agentic voice control with gpt realtime 2.
yes their is bidirectional agent / canvas control via mcp and cli.
yes their is built in shared memory system without bloat.
made with love by a dad in his basement who is tired of vibe coding being slow, boring, and constrained.
CNVS coming soon.
Starlink V3 satellites
Bandwidth per Satellite:
• V2: 96 Gbps
• V3: 1,024 Gbps
Bandwidth per Launch:
V2: 2,600 Gbps
V3: 61,000 Gbps
Deployment per Launch:
• V2: 27 satellites (on Falcon 9)
• V3: 60 (on Starship)
Starlink V3 satellites will begin to be deployed in late 2026 on Starship.
Building apps has never been easier.
With Sites, Codex can turn your work, ideas, and plans into an interactive website or app your team can explore, use, and share with a URL.
Rolling out to Business and Enterprise plans, before expanding more broadly.
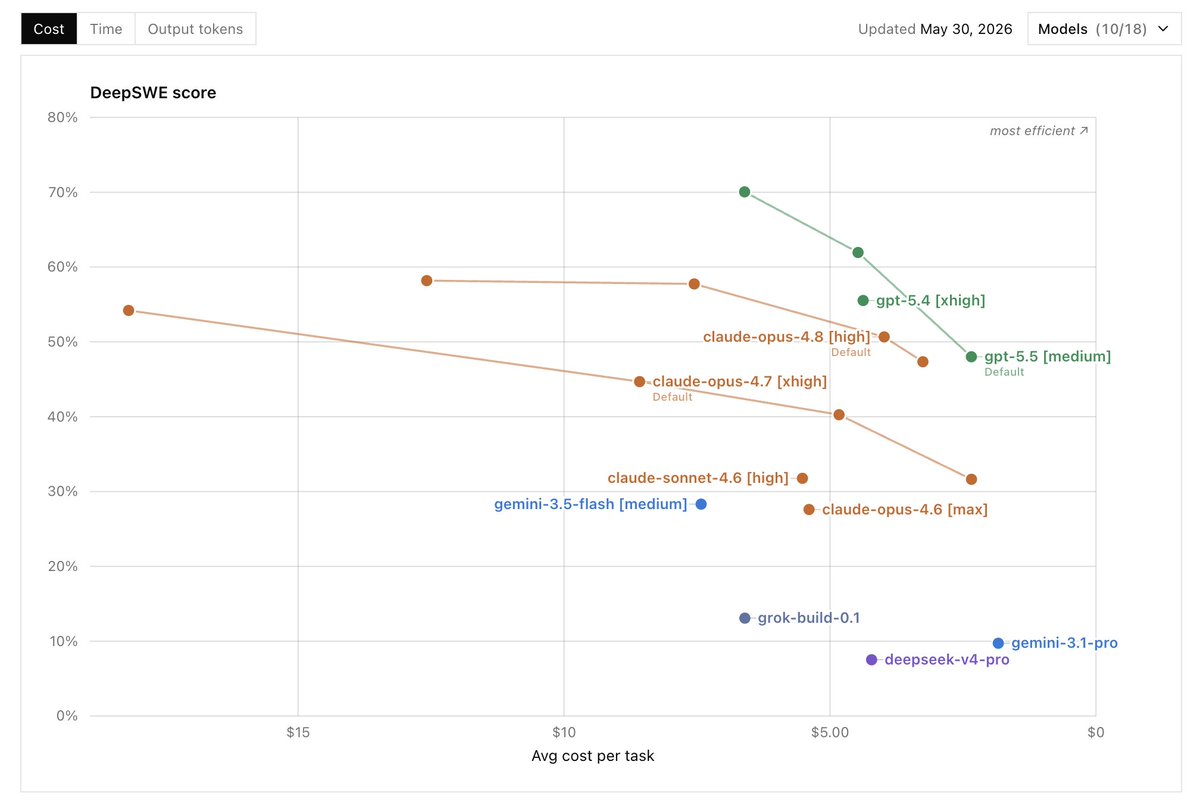
GPT-5.5 is #1 on DeepSWE, a hard long-horizon coding benchmark 🔥
70% pass@1 vs 58% for Claude Opus 4.8.
And GPT-5.5 gets there with:
~2x faster runs
~1/2 the cost
~1/3 the output tokens
Literally, better intelligence per dollar, per minute, per task.