DIMTIPS is a community dedicated to giving back, fueling support for projects that repair, revive, and restore everyday items. Join the DIMTIPS adventure via crypto coin and videos to repair, revive and restore everyday items
https://t.co/uWYRMQRVhJ
I'll buy 10 $KAS for every comment, like, and reshare on this post (must be following me & I'll share proof).
24H only. Ends at 10:17am PST on 10/21/25.
Make me fiat poor (I'm actually kinda worried).
🚨 Breaking News 🚨
Kasplex L2 has officially gone live on Kaspa.
Smart contracts are now available on the network, opening the door for DeFi, NFTs, and a new wave of applications to be built on Kaspa L2
This marks a major milestone in Kaspa’s evolution beyond payments into a full programmable ecosystem.
a few points that come to mind this evening, in no particular order:
- Kaspa pre-zk is a sequencing and data-carrying service; there’s no conceptual difference between txn payloads carrying EVM calldata, KRC20 inscriptions or Kasia chat msgs in that regard
- in particular, the above means there’s no settlement on L1; there are no validity proofs or fraud proofs verified. It’s a one-way route: L2s listen to L1 and the data it makes available; L1 has no idea what interpretation L2s give to this data
- hence an L1<>L2 KAS bridge (in this pre-zk era) cannot be fully trustless, no matter the cleverness of its designers
- this does not mean all L2 funds require trust (you can have tokens that live only on the L2; think of it as any other standalone EVM, eg Eth L1)
- in order for this normal L2 operation to be decentralized (other than KAS bridging which must hold some form of trust as mentioned), its codebase must be open-source and independent validators must be able to run it as they wish. I can respect a decision not to immediately open source something you worked on and holds significant IP, but the tradeoff is clear: until the L2 is fully open-source, there is a degree of centralization/trust in anything it executes, and users should be fully aware.
- (btw iirc some Eth rollups were partially closed-source at their respective mainnet launch, though the case is a bit different since they had L1 settlement support)
- I admire Kasplex’s efforts to bring smart contracts to Kaspa asap. If I’m allowed to be somewhat cynical I think tomorrow's launch is a win-win situation. If the launch succeeds it showcases Kaspa’s speed, responsiveness and immense throughput. If it somewhat stutters or has initial problems, they are not inherent to Kaspa and indicate nothing about the core technology and will be fixed in following iterations (or perfected by other entities). I’m not naive and I’m aware that not everyone understands the differentiation between layers, but it’s the simple truth and will eventually rise.
other r&d updates in short:
- dk: being worked on by some dkoders, initial implementation is already taking shape
- vprogs: not only a yellow paper, a rust prototype is wip
Wow what an explanation of vProgs. Looks like Kaspa moving from industry's shopping malls to highstreet... better still from supermarkets to farmers markets (cooperative).
A late night braindump/stream of consciousness on the architecture and ideas behind vProgs, the “why” and the “how”, the paths not taken and the trails we did climb (with bonus pictures for the avid hikers).
The world of DeFi is full of different architectures for smart contracts. Leading networks like Ethereum and Solana made crucial architectural decisions relatively early on and chose different trade-offs. In parallel, a fascinating cryptographic technology called zero-knowledge proofs (zk) developed at the intersection of computer science and crypto. This technology has evolved both in theory and in practice (applied research/high performance), and in recent years, the vision of generating zero-knowledge proofs (also known in our context as validity proofs) at real-time speeds is becoming a reality. By the way, besides academia and entities like starkware, much of the credit for the development of this vast ecosystem goes to the extended Ethereum community.
Kaspa is currently in a special position with respect to smart contracts (or in the broader terms, programmability/expressiveness). We are an L1 on an upward trajectory that has solved core problems related to capacity (data throughput; currently ~1MB = ~3k txs per second) and speed (while maintaining decentralization and security). Additionally, we aren’t yet architecturally committed to previous decisions on the subject (legacy tech debts). This gives us the drive to learn from all the different trade-offs made by others, connect that with the evolving zero-knowledge technology and the ambition of “winning the ring”, and try to build an architecture that attempts, and likely succeeds, at having its cake and eating it too.
Let’s start with the basic questions. Why not have smart contracts on the base layer? Because at high capacity, it leads to centralization (=Solana; with its huge hardware requirements), and at low capacity (=Ethereum L1), it’s simply not Kaspa. Furthermore, from my perspective, I believe in a base layer that focuses on its essential role: super-fast ordering in world-wide consensus of thousands of transactions/records per second while maintaining computational minimalism (focusing on the structural validity of blocks and signature verification, and perhaps also, validity/zero-knowledge proof verification). In the past, I’ve used the term “preserving the Satoshi ethos” in this context. Maybe ethos isn’t the right word, but it is certainly a fundamental style/architectural decision of separation of concerns and design purity that also reduces the attack surface of the base layer.
Another way to look at it is through the prism of zero-knowledge technology. For those without background, in short: the technology allows for verifying the integrity of a long computation using a minimal and succinct proof. This technology necessarily solves a core problem in consensus systems. It allows the tens of thousands (n→∞) of participants in the consensus system to verify the integrity of a long computation with a short, constant-length or logarithmic computation, where only the prover is required to perform the long computation (multiplied by a significant constant required to generate the proof). This is dramatic, and from my point of view, it’s inescapable to conclude that a programmable consensus system that doesn’t use zero-knowledge is inherently inferior and unsuitable for a modern smart contract system being developed in the second quarter of this century. [https://t.co/RryZZKhmNk]
Okay, so we’ve settled on basic building blocks and axioms. (i) A base layer that can order a lot, fast. (ii) Zero-knowledge. This immediately led us (=about a year ago; at the beginning of the design effort) to the area of based rollups (in Ethereum parlance). This combination leaves the sequencing and data availability power in the hands of the base layer and leaves “only” the computation for the layers above. This means the second layers inherit their security and decentralization (e.g., censorship resistance) from the ordering and availability provided by the base layer, and they prove their computation to it using zero-knowledge (settlement). This creates a system that both maximizes Kaspa’s high-throughput data features and also avoids computational load and complex state on the base layer. Have we reached the promised land? Not yet. (But note that vProgs does not deviate from these axioms).
Let’s start this chapter with a journey into a perhaps obvious question. Why not a single rollup (aka one fat L2)? That is, why not a single, canonical L2 system that runs and proves all transactions ordered and made available to it by the base layer as one monolithic whole? We’ve gained the separation of concerns and design purity. We’re preventing the base layer from needing to run and store the state space of the smart contracts. But are you also moving uncomfortably? The main answer for me is that still all L2 participants who want to follow the state (and unlike L1 verifiers, cannot be satisfied with a succinct state commitment) must run this whole bombastic machine with all its computations (or alternatively, receive the state + proofs from other participants, which is not always cheaper than local computation). To the best of my understanding, Ethereum is moving in this direction on L1 to allow for thin nodes that only need to verify zk proofs without running computations themselves, but this doesn’t render the entire modular ecosystem of rollups that has developed on top of Ethereum obsolete. Another rejection of this possibility is its lack of modularity. It locks Kaspa into a canonical solution and a specific smart contract platform. Through the lens of a software architect, this is an unnecessary fixation that seems avoidable in the zk era, which inherently allows for the modularity of black boxes. Through the lens of a financial platform designer, it prevents the development of independent altruistic/for-profit entities that develop and create a flourishing ecosystem.
Note, what we would have gained from this option is full synchronous and atomic composability between smart contracts (because they are all part of one fat system). We’ll come back to this topic.
The next and obvious alternative for discussion is some (fixed) number of based rollups. Where each rollup chooses a smart contract infrastructure and zero-knowledge/+prover network for itself and designs its own settlement covenant on the base layer through a dedicated canonical infrastructure on L1 that allows for this with maximum design flexibility (see posts on Kaspa research, for example https://t.co/QXbfQiGHWr). Here we are indeed getting closer to vProgs. Conceptually, there’s a possible continuum in the design space here that represents the tension between sovereignty and synchronous composability (syncompo).
Synchronous composability. syncompo is an ideal property for a financial consensus system, achieved trivially on Ethereum in its early years (before demand exceeded L1 capacity). The property is that a smart contract can call any other smart contract as part of the same transaction, examine the result/possibility of a certain action, and make a unified, atomic decision about the entire financial activity. In more technical language, it gets full freedom of action within its slot in the transaction ordering, and in it, it can access any place in the state space and make a decision without things “changing under its feet”. In general, this property is also called atomic composability. I think that in a world with a single global sequencer, any synchronous composability can trivially realize atomicity as well, and therefore the term syncompo expresses the desired property in a cleaner and more distilled way. To understand the financial importance of this property more deeply, see “Composability—everyone’s talking about it” in the article by @hashdag from 2020 https://t.co/TpqGCH6Onw
It’s worth noting here that the axiom with which we opened the chapter, of the base layer as a single sequencer, is necessary for syncompo because without it, such a single slot in the time-space does not exist.
Sovereignty. To illustrate what sovereignty is, let’s go to its leftmost extreme--based rollups that communicate with each other only through asynchronous messages via the base layer (=messages that require the submission of a validity proof on the base layer; similar to an exit operation from L2 to L1 via a canonical bridge). This limitation allows each rollup to be completely sovereign and autonomous in every sense. The vm and zk technologies can be completely different and even unknown between the rollups. They don’t verify each other but trust the base layer to verify proofs and to stamp the identity of the sender of the asynchronous message, whatever its security model may be. In addition, the rollup is also sovereign and independent both in terms of managing its internal state and its computational load (for example, with gas commitments that are subject to regulation by L1) and in its ability to provide proofs to L1 for its execution without depending on any other party (proof liveness).
What’s obviously missing here at this extreme? syncompo. This is not the place to expand on the well-known financial dynamics of liquidity fragmentation. But in a nutshell, the inability to have synchronous composability between rollups turns them into closed spaces, each trying to annex as many applications as possible, among which there is no longer a zero-sum game and healthy competition. That is to say, the two-dimensional nature of the space (rollups, and within them applications that communicate synchronously inside the rollup and asynchronously outside its borders), locks in liquidity and forces applications to remain in a certain space even if the correct financial dynamic would have been to communicate synchronously with applications outside it. One can imagine rollups as large shopping malls, inside which there are stores (=applications/programs) that complement each other (e.g., a beverage store next to a food store). This two-dimensional structure limits the food store from moving to another mall where there is no beverage store, even if the electricity there is cheaper. If we were to flatten all the malls into a single dimension of a city promenade where everything is close to everything, the economic dynamic would balance itself more correctly for the benefit of the general consumer and for the benefit of small business owners who just want to interface with each other (=apps).
A note on the relationship between sovereignty and scalability. Unfortunately, the term “scalability” is often abused. I think that in a certain sense, the term sovereignty cleanly expresses the ability to partition the state space and the computation space among different sovereign entities, and in this sense, it allows us to talk about scalability in the total global state size and about computational scalability.
So, does an architecture exist that achieves both sovereignty and synchronous composability? One can feel the tension between them. How can a program be sovereign and independent and also allow for a global, synchronized, and atomic operation between different sovereign entities?
The vProgs architecture is one that proposes a way to achieve the aforementioned challenging combination. To achieve this, two significant elements are required:
L1 coordination: The base layer needs to provide mechanisms for coordination between sovereign entities that want to communicate with each other synchronously.
On-site execution of remote programs: The programs (verifiable programs) are required to know each other at some level. That is, to preserve computational and proof sovereignty (trustlessly) even in a world where a transaction touches and reads/writes from multiple different programs, it’s not possible for each program to be a black box. Rather, it’s necessary that each entity knows, at the very least, how to computationally run other programs (and in emergencies, also prove them to maintain its independence). In this sense, we deviate from the leftmost extreme of absolute “sealed black box” sovereignty, but we do manage to preserve computational/state/proof sovereignty.
L1 coordination. At the core of the vProgs protocol is a computational dependency graph structure that is maintained by L1 and evolves in real-time as a result of transaction ordering. That is, a full mapping of all reads and writes between vProgs transactions (from the global state space where each data coordinate is defined by the pair (prog, account)). The base layer, of course, does not hold the data that passes through these computations, but only maintains their meta-structure. This graph is called the Computational DAG (CD) and it has two central roles. (i) It allows L1 to monitor and regulate the total computational cost of each composable action on every participating prog (including monitoring the need to run previous transactions of another prog that wrote to the account they now need to read; which is named the computational scope in the paper); (ii) It allows for the construction of a binding cryptographic structure (by hashing the graph structure and its edges), which allows the prover of each prog to perform a stitching operation of conditional proofs according to this graph (for more complete technical details, you’ll need to read the paper itself).
On-site execution of remote programs. This is a mechanism whose systemic cost is that all participants must know how to locally run the other participants (vm-wise), and it also requires that everyone knows all the smart contracts of everyone else (everyone=all those they are interested in and want to talk to synchronously).
This architecture creates a dynamic system that can contract and expand according to real-time dynamics. That is, it can (if we go to the extreme) contract to hot spots that everyone wants to read from and write to, thereby turning the CD at a given time into a sequential dependency structure where everyone has to run everything (which in effect converges to L1 enforcing a global computational bound for everyone = lack of scalability, at least temporarily). And it can encourage parallelism and maximum independence between computations precisely to reduce the aforementioned dependencies.
The economic dynamics and decision-making space of provers. Here is a very interesting point that illustrates the immense power of real-time zero-knowledge. To illustrate this point, let’s take two extremes. Assume that every prog in the system sends a zk proof for its computations every hour. Assume also that every ten seconds on average, a transaction belonging to a random prog x performs a composable action and reads + writes to another random prog y (and all other actions are local). Let’s start the simulation from the moment everyone has submitted proofs. The first composable action does not require a deep backward computation. Why? Because you can bring evidence for the state of the remote account being read using the zk proof of y that was just submitted to the system. The second composable action (after twenty seconds) will already connect and create a dependency between two other random progs. In fact, every ten seconds, we are drawing a random edge in the space of progs. It’s easy to imagine that if there are, for example, 100 progs in the system, within a few minutes, enough connections will be formed between all of them and we will see a tangled mess. That is, at some point, the composable action between two programs will cause each of them to run almost all the transactions that have appeared on the network since the last proof (because x needs to run y, and y depended on z, and z on w, etc.). In contrast, at the other extreme, let’s imagine a real-time system where each prover/prog provides a proof every ten seconds. In this case, the fast proofs will prune the tangled mess before it can even form, and each program will only need to run a small (logarithmic) number of foreign transactions. For the advanced, this analysis is directly related to a fascinating result in the theory of random graphs that shows there is a threshold above which a giant component is formed (=a tangled mess of dependencies), and below which a mess is almost certainly not formed. I wrote about this more extensively at https://t.co/YbLs8vWLpw and there is much more to expand on beyond that.
So what’s happening here? The architectural design has created a playground, or an economic maneuvering space, where provers have an interest in providing proofs at a high frequency to minimize the computational dependencies, which in turn will allow for more capacity (and possibly more fees to them). In addition, there is also an encouragement for contract designers to create dynamics and systems that are as parallel as possible (because this also minimizes the computational scope in the CD).
Zoom out. Back for a moment to the mall analogy. The vProgs design flattens the space to a single dimension where all are equal citizens and everyone can talk to everyone synchronously. Essentially, it creates a system where the developer experience (dev ex) is such that he deploys a smart contract/prog to L1 and his application talks synchronously with other applications in the vProgs space. Yes, he will have to choose an infrastructure (I imagine this as a template provided by different infra entities that defines the zkvm and the prover network), but it will be an insignificant part of his experience and that of his application’s users. From a technical and infrastructural perspective, this is not a major change relative to current infra development efforts, but it is a different presentation of them. That is, this design allows for, and seemingly strives for, the breaking of monolithic rollup structures in favor of prog templates and prover networks that communicate with each other.
In this sense, the vision of the vProgs protocol is that for a certain cost to the base layer (mainly that of maintaining the CD), we will get a system that is also modular enough to encourage a development ecosystem and accelerate the adoption of new zk technologies (since it’s easier to update templates and let new contracts run on them), also allows for sovereignty, and also flattens the space and allows--with the help of synchronous composability--for a dev ex and ux that gives the experience of native L1 programmability.
>>
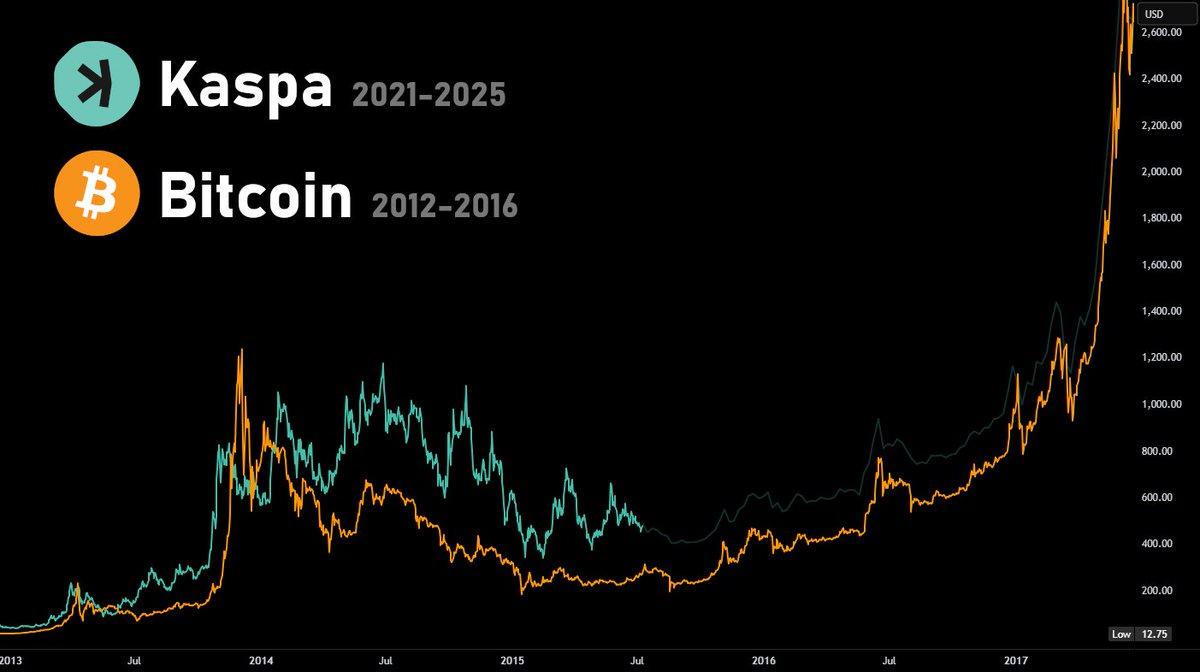
$KAS looks almost exactly like Bitcoin did from 2012-2016 🤯
Same 4-year structure. Same early adoption phase. Same parabolic potential…
Except its 6000x faster and actually works as intended.
If anything will ever be “the next Bitcoin” — it’s Kaspa.
$KAS Here is my takeaway from this.
1. Never use hot wallets to store a significant amount of wealth
2. If you are using a cold storage device be sure to always verify what you are signing.
3. If you are on Tangem you can’t verify what you are signing and you are putting your trust in the apps open source code. (This has been safe since inception but don’t think it’s perfect) If this fact bothers you look into diversifying wallets. Lastly don’t use Tangem with a seed phrase.
4. Before you send your Kaspa to another wallet it doesn’t hurt to do a test transaction. Kaspa being very fast and cheap makes this very easy.
5. At the moment the best wallet for Kaspa that protects you from this is @Ledger since it’s a cold storage device that lets you verify your transactions before you sign.
6. @OneKeyHQ could also be one of the best wallets but it currently blind signs. Been pushing to get this fixed and hopefully it happens soon. 🙏
7. If you have OneKey don’t panic. I use it and never had problems. Do a test transaction first if you seriously need to move your Kaspa. If not just sit tight and continue keeping your seed phrase safe. Never store a seed phrase online on a notes app or photo!