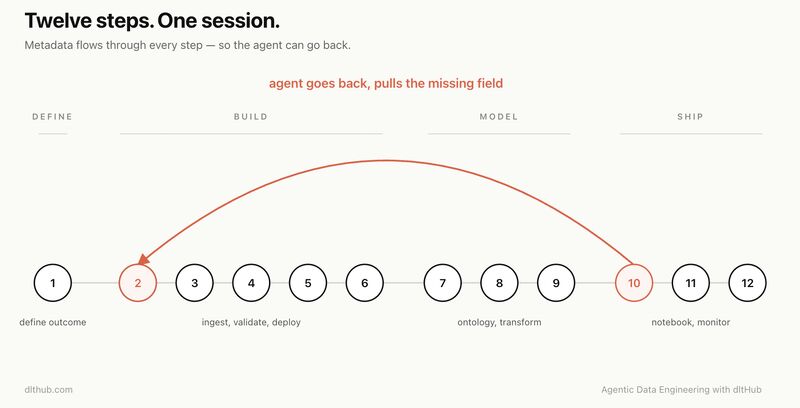
Building pipelines with AI usually means losing context between tools.
dltHub AI Workbench runs the full 12-step workflow as a continuous session, schemas, incrementals, traces, transformations, and notebooks share context across the stack.
https://t.co/o8k2ht3KrU
@inngest@lightdash_devs@Streamkap At dltHub, @elviskahoro will demo our new Transformations public preview.
Expect demos from practitioners and startups building real-world AI and data systems, and a look at what agentic analytics looks like in practice.
📅 June 3 · SF
https://t.co/uc6ozcHiLZ
Agentic Analytics Demo Night lands in San Francisco this Wednesday 🚀
We're joining @inngest, @lightdash_devs, and @streamkap for an evening of demos from teams building at the intersection of AI, analytics, and data infrastructure.
🧵
@sameer_alsakran@metabase Sameer started Metabase as a side project, waited years before charging, ignored conventional SaaS advice, and built a product now used by 90k+ companies with 8-figure ARR.
We'll discuss OSS, AI, customer feedback, and building products that last.
https://t.co/BnEJoBLmi4
What does it take to build a product people actually keep using?
On Wednesday, we're hosting @sameer_alsakran, Founder & CEO of @metabase, at our office in Berlin for a live conversation with Francesco Mucio from Data Berlin.
🧵
@modal We’ll cover:
→ turning agent traces into dashboards for AI adoption, cost, and real business impact
→ how teams use Modal Sandboxes to run agents safely, plus a live background agent demo
📅 May 27 · 6–8 PM GMT+2
📍 Berlin
https://t.co/FSDDKF11gn
Berlin’s Applied AI Week is looking pretty special.
Tomorrow, dltHub and @modal are hosting an evening in Berlin for founders, engineers, and builders shipping agents in production.
Featuring Kenny Ning, Jefferson Girao & Alena Astrakhantseva.
The open source AI stack walked into a bar in Silicon Valley. Ingestion, retrieval, and metadata all showed up.
🚀 The community came through at our event with @dltHub & @LanceDB for a night of technical talks built for engineers actually shipping AI in production. No fluff. Just engineers talking shop.
Stay tuned for more community meetups!
Three production stories from @GrabID, @dltHub, and @iFood. Three very different starting points. One shared foundation. ����
Our May Town Hall brings together the teams answering the same question from very different angles: how do you make context actionable for AI at scale? 📈
Register: https://t.co/y5DdLtTEIJ
Some of the best open source AI conversations happen in person. We're joining @dltHub and @LanceDB in Menlo Park on May 21 for technical talks and demos from the engineers building the ML stack. Join us!
👉 https://t.co/5ceLRQpe18
Next Thur May 21: @lancedb x @dltHub x @DataHubCloud demystifying the missing data layer for ML:
- Lance, the default storage layer for multimodal AI
- dltHub, the connective tissue of your AI data stack
- Supercharging Cortex with DataHub
https://t.co/1yBTXcKMWt
The AI stack is evolving fast, but reliable data movement is still the foundation.
Join dltHub, @LanceDB and @DataHubCloud on May 21 in Menlo Park for talks on multimodal AI storage, AI data pipelines, and trusted lineage systems.
🔗 https://t.co/u50aE57vaF
@elviskahoro@temporalio@nyghtowl@cecilphillip In under 10 minutes, we’ll cover:
- AI-assisted pipeline setup
- GitHub → dlt workflows
- Where AI helps vs where engineers still need to steer
- How to inspect & validate pipelines
📅 May 20 · 10 AM PST
📍 Live on YouTube
Watch live: https://t.co/9cTzRCInbE
How fast can you go from zero to a production-ready data pipeline when AI is your copilot?
Next Wednesday, @elviskahoro joins @temporalio alongside @nyghtowl and @cecilphillip for a live Vibe Check building a GitHub-powered pipeline with AI + dlt.
Explainer on ontology engineering and what we're building around it: why just clean schemas and prompts aren’t enough, and how adding a canonical model + taxonomy + ontology changes what agents can correctly compute (ARPU being the clearest example).
https://t.co/n1v6XylAy6
@probabl_ai We’ll show how agents can power data pipelines as code, turning traces into fresh, reliable datasets.
Stack: dlt, LanceDB, Pydantic, Ibis, HuggingFace + more → behind our agent evaluation platform.
📅 May 5 | 🕒 12:20–12:40
📍 Station F, Paris
https://t.co/9h6n2FrqhH
We’re excited to share that Violetta Mishechkina will be speaking at GOSIM Paris 🇫🇷
Invited by @probabl_ai to join the “Own Your Data Science and AI” workshop.
🎤 From Agent Traces to Analytics
Agents generate code, text, telemetry, yet most teams still rely on stale datasets.