Happy to release our work on Language Model Cascades. Read on to learn how we can unify existing methods for interacting models (scratchpad/chain of thought, verifiers, tool-use, …) in the language of probabilistic programming.
paper: https://t.co/olaE8mATYB
We achieved gold medal-level performance 🥇on the 2025 International Mathematical Olympiad with a general-purpose reasoning LLM!
Our model solved world-class math problems—at the level of top human contestants. A major milestone for AI and mathematics.
OpenAI achieved gold medal on 2025 International Math Olympiad (solving 5 of 6 problems)!
Thinks for hours and writes proofs in natural language.
We've come a long way from LLMs solving 50% of MATH dataset in 2022
Congrats @alexwei_ on spearheading a major milestone!
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
This is on the scale of the Apollo Program and Manhattan Project when measured as a fraction of GDP. This kind of investment only happens when the science is carefully vetted and people believe it will succeed and be completely transformative. I agree it’s the right time.
@mollyfmielke There's evidence for it: "In all cases, with exception of S9, they report having owned 1-of-3 toys widely sold by Fisher-Price between 1972 and 1989"
Anecdotally, friend traces some # colors to license plate on family car.
https://t.co/OiyyXKhdkJ
study: https://t.co/aPjthgDW8R
@cHHillee@polynoamial@tamaybes Gotta look for the NP problems of P vs NP: easy to check, hard to do.
Not sure what these look like in math outside formal theorem proving
@polynoamial@tamaybes iiuc one of the constraints with FrontierMath is that the results are easy to check.
Unless we do it with formal theorem proving, I’m not sure how to do that for unsolved problems
Though maybe one tier should be unsolved hard to check ones too
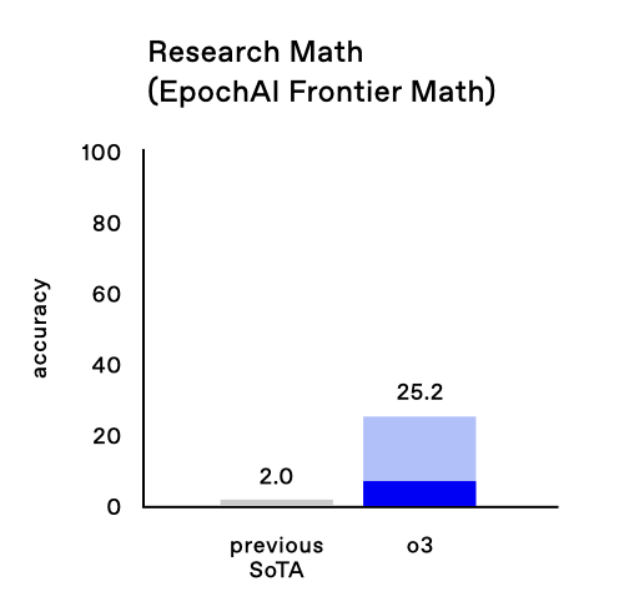
Lots of folks are posting quotes from Gowers/Tao about the hardest split of FrontierMath, but our 25% score is on the full set (which is also extremely hard, with old sota 2%, but not as hard as those quotes imply).
@_xjdr@btc4me2 tbc it's a joke - literally meant it had been 16 hours since previous post & the o1->o3 jump is 32->87%
https://t.co/dvMlgd5shm
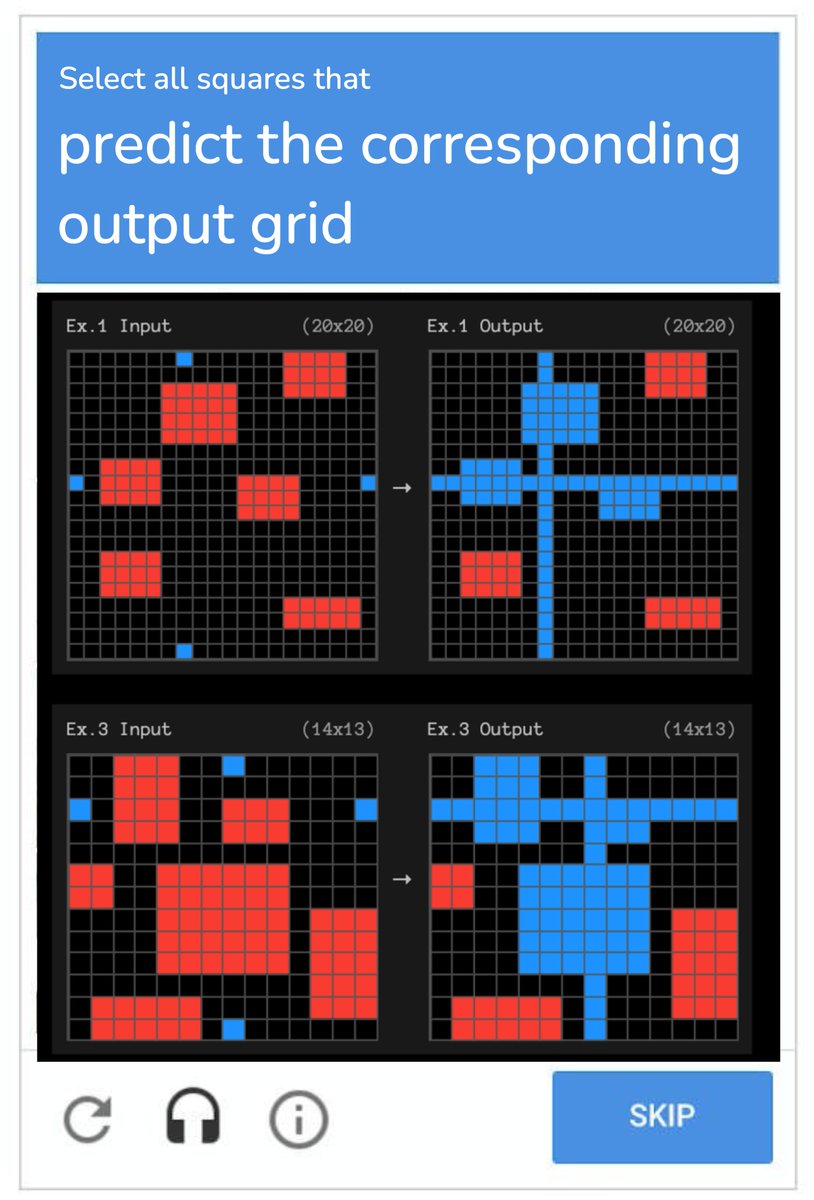
At this rate, how long til ARC-AGI is “solved”?
For context:
- gpt-4o @ 5%
- Sonnet3.5 @ 14%
- o1-preview @ 18%
- o1 @ 32%
- best scaffolded solution @ 54%
Caveat on the Tao quote: that refers to the hardest "research" split of the dataset, while the 25% is across the entire dataset.
https://t.co/hYZU5bDeZo
@GarrisonLovely To clear a possible misunderstanding: the quotes refer to questions in the highest tier of difficulty of FrontierMath. Not every question in the benchmark is as difficult as the ones Tao and Gowers reviewed.
imo the improvements on FrontierMath are even more impressive than ARG-AGI. Jump from 2% to 25%
Terence Tao said the dataset should "resist AIs for several years at least" and "These are extremely challenging. I think that in the near term basically the only way to solve them, short of having a real domain expert in the area, is by a combination of a semi-expert like a graduate student in a related field, maybe paired with some combination of a modern AI and lots of other algebra packages…”
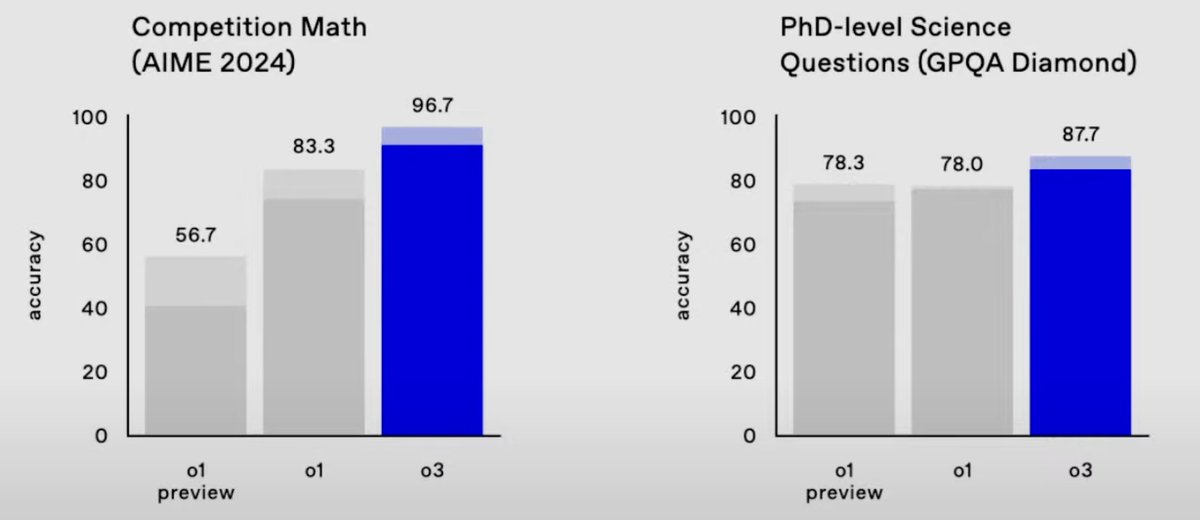
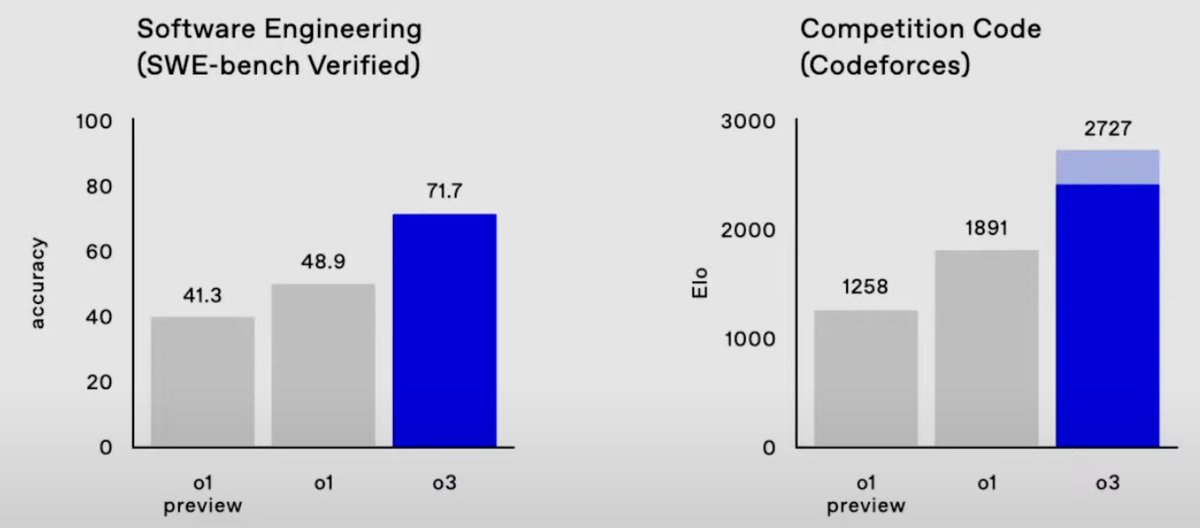
Well, on FrontierMath 2024-11-26 o3 improves the state of the art from 2% to 25% accuracy. These are absurdly hard strongly held out math questions. And on ARC, the semi-private test set and public validation set scores are 87.5% (private) and 91.5% (public). (7/n)
We are used to the cadence of big model releases: GPT2->3->4 took two years each time
We’re in a different world now
o1 was announced months ago, now already on next generation
Expect faster improvement going forward: o1 is like gpt2 if we could jump to gpt4 ~immediately