Thrilled to share our latest advances in video understanding 📽️: Gemini 2.5 Pro is a truly magical model to play with, excelling in traditional video analysis and unlocking new use cases I could not imagine a few months ago🪄
More in 🧵 and @Google blog: https://t.co/4993sJmBpG
Today, we share the tech report for SmolVLM: Redefining small and efficient multimodal models.
🔥 Explaining how to design a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
Here are the coolest insights from our experiments:
✨ Longer context = Big wins: Increasing the context length from 2K to 16K gave our tiny VLMs a 60% performance boost!
✨ Smaller is smarter with SigLIP: Surprise! Smaller LLMs didn't benefit from the usual large SigLIP (400M). Instead, we use the 80M base SigLIP that performs equally well at just 20% of the original size!
✨ Pixel shuffling magic: Aggressively pixel shuffling helped our compact VLMs "see" better, achieving the same performance with sequences 16x shorter!
✨ Learned positional tokens FTW: For compact models, learned positional tokens significantly outperform raw text tokens, enhancing efficiency and accuracy.
✨ System prompts and special tokens are key: Introducing system prompts and dedicated media intro/outro tokens significantly boosted our compact VLM’s performance—especially for video tasks.
✨ Less CoT, more efficiency: Turns out, too much Chain-of-Thought (CoT) data actually hurts performance in small models. They dumb
✨ Longer videos, better results: Increasing video length during training enhanced performance on both video and image tasks.
🌟 State-of-the-Art Performance, SmolVLM comes in three powerful yet compact sizes—256M, 500M, and 2.2B parameters—each setting new SOTA benchmarks for their hardware constraints in image and video understanding.
📱 Real-world Efficiency: We've created an app using SmolVLM on an iPhone 15 and got real-time inference directly from its camera!
🌐 Browser-based Inference? Yep! We get lightning-fast inference speeds of 40-80 tokens per second directly in a web browser. No tricks, just compact, efficient models!
If you’re into efficient multimodal models, you’ll love this one.
The webinar recording with @JacobChalkie & @huh_jaesung, @HRaajesh & @dnaveenr, and @rodosingh23 & @sridhruv is up!
Watch here: https://t.co/T69FhHXqKZ 📺
They discussed:
- Time-interval machine
- Movie identity-aware captioning
- TV Story Summarization
Enjoy!
In the 56th session of #MultimodalWeekly, we have three exciting presentations across different video understanding tasks: action recognition, video description, and video summarization.
✅ @HRaajesh and @dnaveenr will discuss Movie-Identity Captioner (MICap) - which is a new single stage approach that can seamlessly switch between id-aware caption generation or fill-in-the-blanks when given a caption with blanks.
https://t.co/PXTunmgYdR
Thanks to the organizers (@davmoltisanti +) for an opportunity to share my thoughts at the amazing @CVPR Workshop "What Is Next in Video Understanding" https://t.co/je25r8fwbQ
Slides summarizing some of our work on video and open challenges here: https://t.co/KuyRJ1TpPi
Given multiple short movie clips, can models generate coherent identity-aware descriptions? 🤔 Turns out, this is a complicated task as it requires linking identities and what they are doing over time. Our @CVPR 2024 work improves this: https://t.co/K4TQFm6GYg
🧵1/7
Given multiple short movie clips, can models generate coherent identity-aware descriptions? 🤔 Turns out, this is a complicated task as it requires linking identities and what they are doing over time. Our @CVPR 2024 work improves this: https://t.co/K4TQFm6GYg
🧵1/7
Big thanks to @MakarandTapaswi Sir for being so supportive, understanding and an amazing guide/mentor. Being a part-time RA along with a full-time job was quite tough but Sir was so supportive throughout. 🙌🙏
Very proud of @dnaveenr who persevered as a part-time research assistant with a part-time advisor 😉and @HRaajesh, a 3rd year undergrad who ramped up in 4 months 🚀 and ran bulk of the experiments, a week before his end semester exams. Thanks @zeeshank95 for the support🤝
3/4
Happy to share that our paper - Identity-aware video captioning has been accepted to #CVPR2024 . 2+years of efforts and persistence has finally paid off.
With rockstar teammates - @HRaajesh@zeeshank95 and under amazing guidance of @MakarandTapaswi Sir.
After 2 years, Practical Deep Learning for Coders v5 is finally ready! 🎊
This is a from-scratch rewrite of our most popular course. It has a focus on interactive explorations, & covers @PyTorch, @huggingface, DeBERTa, ConvNeXt, @Gradio & other goodies 🧵
https://t.co/nzv7pek0iq
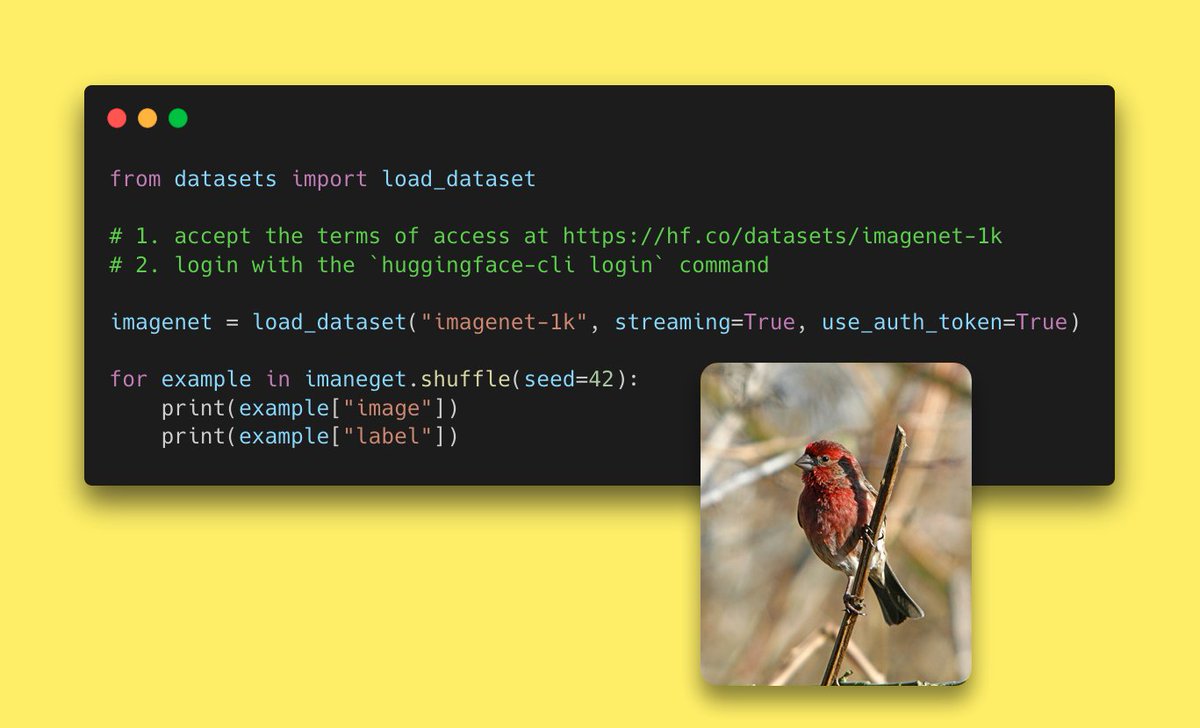
We just released 🤗Datasets 2.3 !
📚New datasets:
- Load ImageNet easily (no more manual download!)
- BigBench🔥, QuickDraw, TruthfulQA, etc.
⚡️New features:
- More optimized to_tf_dataset() to play with @TensorFlow
- Stream datasets in parallel with the @PyTorch DataLoader
Biwi Kinect Head Pose Database is now available on @huggingface🤗hub.
The dataset by @CVL_ETH consists of over 15K images of 20 people recorded with a Kinect while turning their heads around freely. 🧵⬇️
Try it now :
https://t.co/Ms1xa9xTbs