OMG finally 😻 what a merge! It's done, we pressed the release button for DocArray v2 🎉
If you're building a machine learning application that deals with multimodal data, then DocArray is the way to go 😼
https://t.co/hQy2EqKmKF
🚨DocArray now fully supports @pydantic v2 !
We have been working on supporting both versions of Pydantic and we finally released it today with DocArray v0.39.
It brings better performance overall of about +20% and more than +240% faster serialization of complex tensor!
🎉@docarray is now an Incubation Stage project!
Their dynamic schemas, vectorDBs integration, and seamless framework compatibility are fueling their journey of success.
Join us in celebrating their achievements! 🌟
Read more: https://t.co/GtsPADMaIs
We've just released DocArray v0.37, featuring:
👉 @milvusio integration
👉 Filtering in HnswDocumentIndex
👉 Pre-filtering in InMemoryExactNNIndex
👉 Choosing your own tensor format in DocVec
👉 And more!
Read the release notes now: https://t.co/wlCMB0kUPR
DocArray 0.36 is out! 🥳
New features:
👉 JAX Integration
👉 Redis Integration
Plus faster searching with HnswDocumentIndex and multiple bug fixes!
https://t.co/OnWCKj5YTH
We've updated Jina to 3.19 with new features:
👉 Support for all versions of @DocArray
👉 Hubble adapts to the local DocArray version
👉 Support for pulling from private registries using Kubernetes secrets
👉 Rewrote documentation for new DocArray
https://t.co/s8RRZKLqHa
Finally we have managed to bring all the new benefits introduced with @docarray refactor into https://t.co/zTTv1uOF09.
Now you can serve your models and applications with your own types and schemas. Jina adapts to your data instead of forcing you to adapt to Jina expected schema
We all love when a perfect couple finds each other, like DocArray and Otter.
DocArray brings native multi-modal data structures to Otter, a native multi-modal model trained for in-context and few-shot learning. See how in this article from Jina AI.
https://t.co/yfs1ccHetM
DocArray 0.35.0 is out! 🥳
New features:
👉DocVec now has the same serialization interface as DocList
👉File format validation on URLs
👉New methods to create BaseDoc instances from schemas
https://t.co/lLfGEKB9av
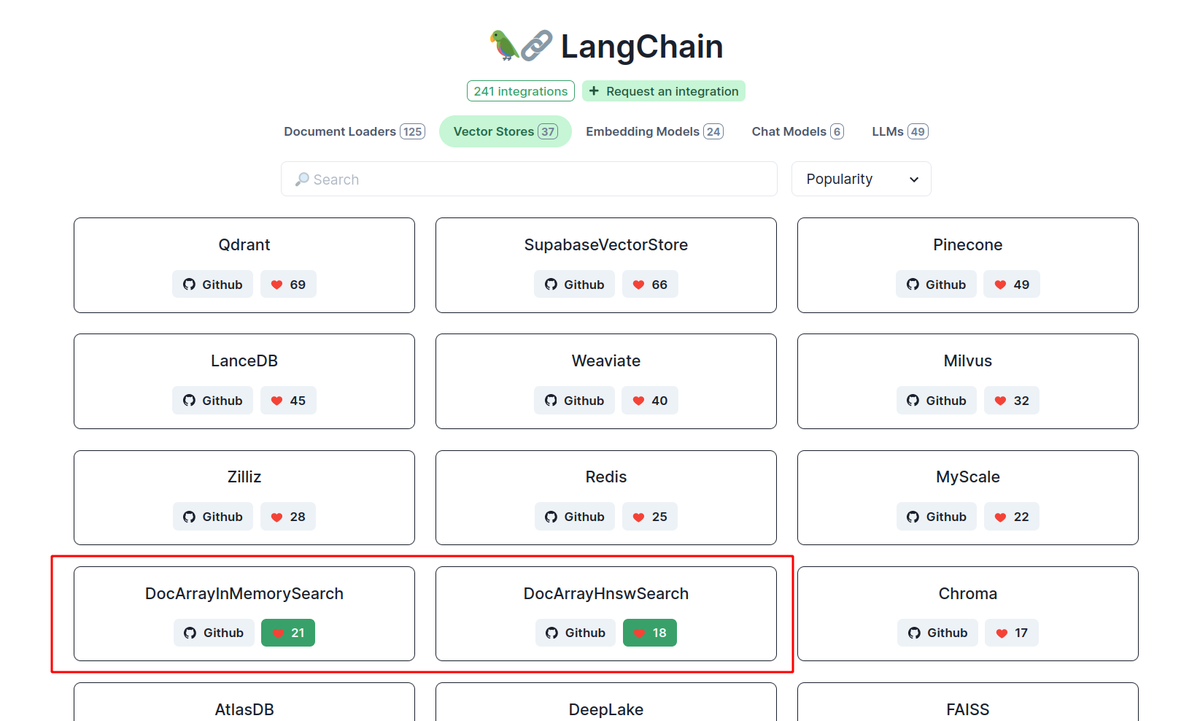
Love @langchain 🦜⛓️?
Love DocArray?
Langchain just launched their new integrations hub and DocArray is right there in the mix - twice!
The best part: You can even give us a ❤️
https://t.co/Lv2Ji2ocD2
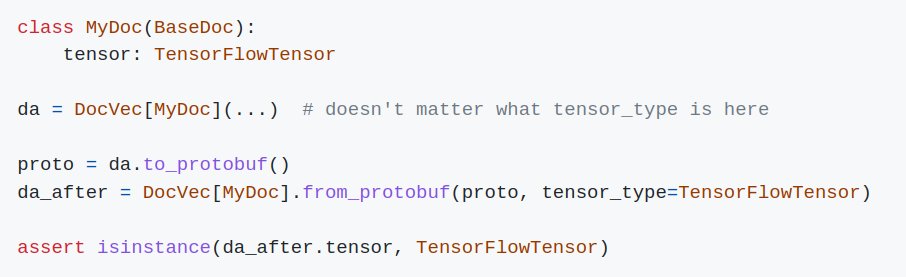
⚡️Deserialize DocVec directly to numpy, torch, or tf
When you deserialize a DocVec from Protobuf, you can now choose if its tensors should be loaded to numpy, pytorch, or tensorflow:
DocArray 0.34.0 is out! 🥳
🚨 BREAKING CHANGE: Requires Python 3.8 or higher!
New features:
🔍 Nested search in InMemoryExactNNIndex
�� Easily check if a Document is already in a DocumentIndex
⚡️ Deserialize DocVec directly to numpy, torch, or tf
https://t.co/CGw5Be0P0V
🎉 Excited to introduce DocArrayRetriever in @langchain!
Looking to link external data to LLMs? @docarray is your key to:
1⃣ Representing data flexibly
2⃣ Numerous data storage options
3⃣ Smooth integration into Langchain
Follow this thread for a step-by-step guide 🧵
1/5
This is a big deal.
Now @jinaAI_ fully support @docarray v2 and allows to build multi-modal AI API with an experience similar to @FastAPI
Here is how it looks like now
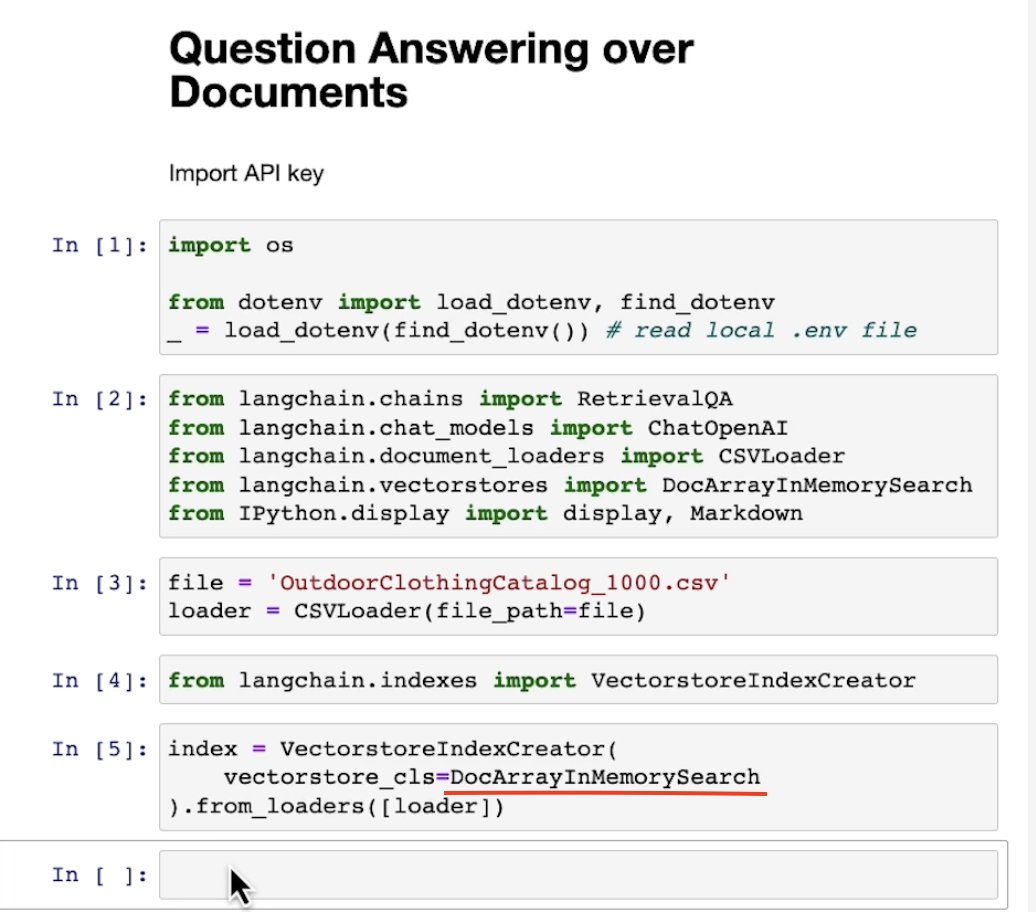
Thrilled to see @docarray in action within @DeepLearningAI_'s Langchain course, delivered by @AndrewYNg and @hwchase17!
DocArrayInMemorySearch really is an excellent foundation for kickstarting your own LLM applications with @langchain