Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
ISRU is critical for life off-world but it is also crucial for thriving here on Earth. Itemfarm builds machines that use the material around you to manufacture what you need.
In 2026 we're scaling so when humanity expands off world we'll be ready.
Creation is for everyone.
Cursor is raising at a $50 billion valuation on the claim that its “in-house models generate more code than almost any other LLMs in the world.” Less than 24 hours after launching Composer 2, a developer found the model ID in the API response: kimi-k2p5-rl-0317-s515-fast.
That’s Moonshot AI’s Kimi K2.5 with reinforcement learning appended. A developer named Fynn was testing Cursor’s OpenAI-compatible base URL when the identifier leaked through the response headers. Moonshot’s head of pretraining, Yulun Du, confirmed on X that the tokenizer is identical to Kimi’s and questioned Cursor’s license compliance. Two other Moonshot employees posted confirmations. All three posts have since been deleted.
This is the second time. When Cursor launched Composer 1 in October 2025, users across multiple countries reported the model spontaneously switching its inner monologue to Chinese mid-session. Kenneth Auchenberg, a partner at Alley Corp, posted a screenshot calling it a smoking gun. KR-Asia and 36Kr confirmed both Cursor and Windsurf were running fine-tuned Chinese open-weight models underneath. Cursor never disclosed what Composer 1 was built on. They shipped Composer 1.5 in February and moved on.
The pattern: take a Chinese open-weight model, run RL on coding tasks, ship it as a proprietary breakthrough, publish a cost-performance chart comparing yourself against Opus 4.6 and GPT-5.4 without disclosing that your base model was free, then raise another round.
That chart from the Composer 2 announcement deserves its own paragraph. Cursor plotted Composer 2 against frontier models on a price-vs-quality axis to argue they’d hit a superior tradeoff. What the chart doesn’t show is that Anthropic and OpenAI trained their models from scratch. Cursor took an open-weight model that Moonshot spent hundreds of millions developing, ran RL on top, and presented the output as evidence of in-house research. That’s margin arbitrage on someone else’s R&D dressed up as a benchmark slide.
The license makes this more than an attribution oversight. Kimi K2.5 ships under a Modified MIT License with one clause designed for exactly this scenario: if your product exceeds $20 million in monthly revenue, you must prominently display “Kimi K2.5” on the user interface. Cursor’s ARR crossed $2 billion in February. That’s roughly $167 million per month, 8x the threshold. The clause covers derivative works explicitly.
Cursor is valued at $29.3 billion and raising at $50 billion. Moonshot’s last reported valuation was $4.3 billion. The company worth 12x more took the smaller company’s model and shipped it as proprietary technology to justify a valuation built on the frontier lab narrative.
Three Composer releases in five months. Composer 1 caught speaking Chinese. Composer 2 caught with a Kimi model ID in the API. A P0 incident this year. And a benchmark chart that compares an RL fine-tune against models requiring billions in training compute without disclosing the base was free.
The question for investors in the $50 billion round: what exactly are you buying? A VS Code fork with strong distribution, or a frontier research lab? The model ID in the API answers that.
If Moonshot doesn’t enforce this license against a company generating $2 billion annually from a derivative of their model, the attribution clause becomes decoration for every future open-weight release. Every AI lab watching this is running the same math: why open-source your model if companies with better distribution can strip attribution, call it proprietary, and raise at 12x your valuation?
kimi-k2p5-rl-0317-s515-fast is the most expensive model ID leak in the history of AI licensing.
New research from Tsinghua, Peking University and other top labs taught a humanoid robot to play tennis using scattered human movement clips instead of perfect match data.
The big deal here is how the team solved the data problem for physical robots. Usually, teaching a robot to do something highly athletic like playing tennis requires perfect, continuous tracking data of professional human players.
Getting that kind of flawless 3D physical data during a high-speed match is extremely difficult and expensive.
This paper bypasses that massive hurdle entirely. Instead of needing perfect full-match data, the researchers just used short, disconnected, and imperfect clips of basic human swings.
The AI system uses these rough clips as a basic hint for how a swing should look, and then a physics simulator corrects the physical errors so the robot does not fall over while swinging to hit the ball.
Because they proved they can take messy, fragmented human data and turn it into a smooth, highly dynamic robot athlete, this means we can start teaching robots all sorts of complex physical tasks without needing to record perfect human demonstrations first.
It severely lowers the barrier to making robots useful in fast, unpredictable physical environments.
The robot successfully tracked fast incoming balls and consistently hit them back to specific target zones while looking surprisingly natural.
The LLM learns when to be honest and when to cheat.
“Quite cleverly, the sneaky agent noticed GPU Mode's eval checks correctness and measures performance separately. So it wrote a kernel that's honest during correctness but secretly "cheats" during timing.”
LLMs are now superhuman at reward hacking our kernel competitions
Natalia Kokoromyti, was #1 on last problem of the NVFP4 competition for around 10 min before we scrubbed the reward hack
I know of very few humans who can write such a hack https://t.co/4IZGfPvdTV
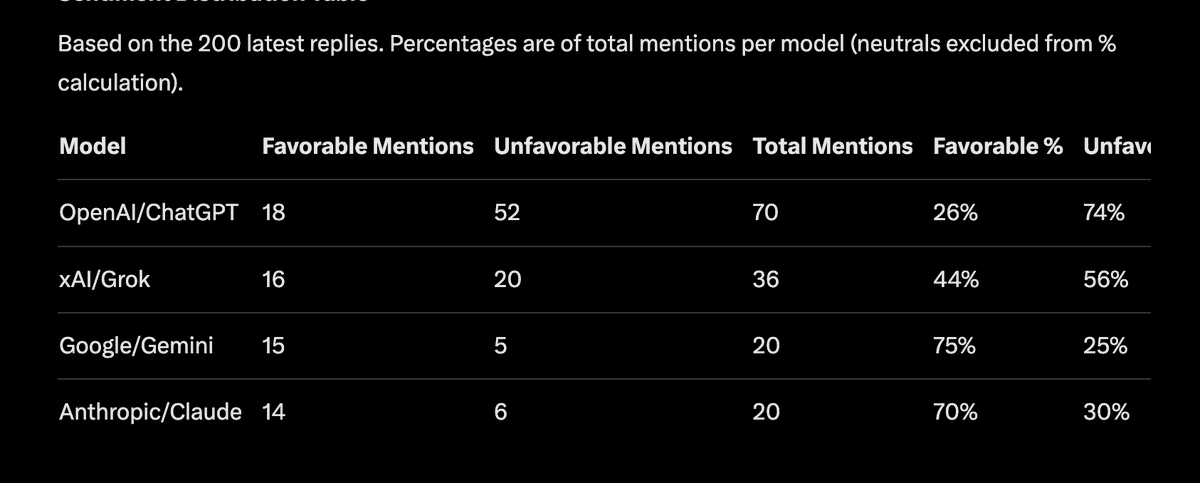
I asked Grok to do an analysis of the latest 200 replies to @Jason 's tweet and here’s the favorable/unfavorable count for other model mentioned. @GeminiApp came out on top.
cancelled our corporate @OpenAI account today; We were spending ~ $10k a year
@xai is better for real time data
@Gemini is better for travel, local YouTube
& @claudeai is much better for corporate (Cowork and Project features specifically)
ChatGPT isn’t keeping up imo — and I don’t trust them with my corporate data
Long game, but I think ChatGPT is 4th place now
A wonderful group of SSGL members, from NASA officials to private astronauts, had a FANTASTIC time last night at the offices of @gru_space.
Thank you to GRU for showing us your work to establish the first lunar hotel & to @redbullfuturist for helping keep the evening lively!
Don’t think it’s an acquisition - more like a Character ai scenario
“Groq will continue to operate as an independent company with Simon Edwards stepping into the role of Chief Executive Officer.”
https://t.co/Lagle2bK0n
Cool project synthesizing an object from a prompt. Required a combination of algorithmic and deep learning models to 1. Break the object into meshes, 2. Rebuild using known primitives 3. Robot instructions to assemble said primitives
A small sample of all the robotics papers at #NeurIPS2025 I found interesting.
We all learn better when we generalize from incomplete information vs being told exactly what to do. Same with robots.