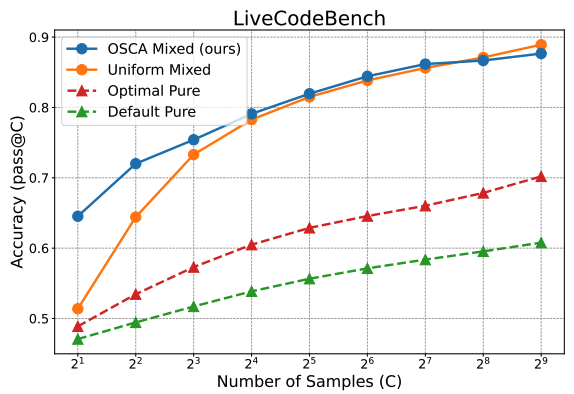
Everyone talks about scaling inference compute after o1. But how exactly should we do that? We studied compute allocation for sampling -- a basic operation in most LLM meta-generators, and found that optimized allocation can save as much as 128x compute!
https://t.co/HYkR92Fxse
Experience 🚀accelerated, 🔝next-level performance with our latest paper on end-to-end story generation! More powerful💪 and faster⚡ than ever. It's a pleasure to work on this exciting project with my amazing collaborators!
Generate a high quality story plot containing thousands of tokens automatically with one click and less than 30 seconds! 😺 Introducing our end-to-end story plot generator, E2EPlot, which is fast in speed and easy to fine-tune! https://t.co/Ousik2zm6o
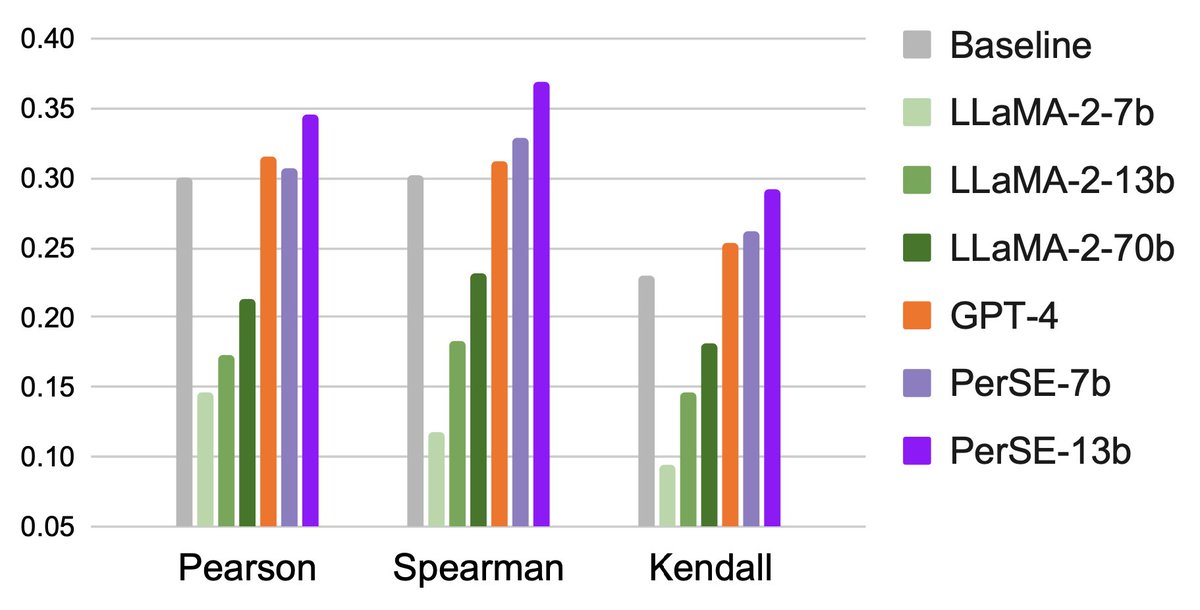
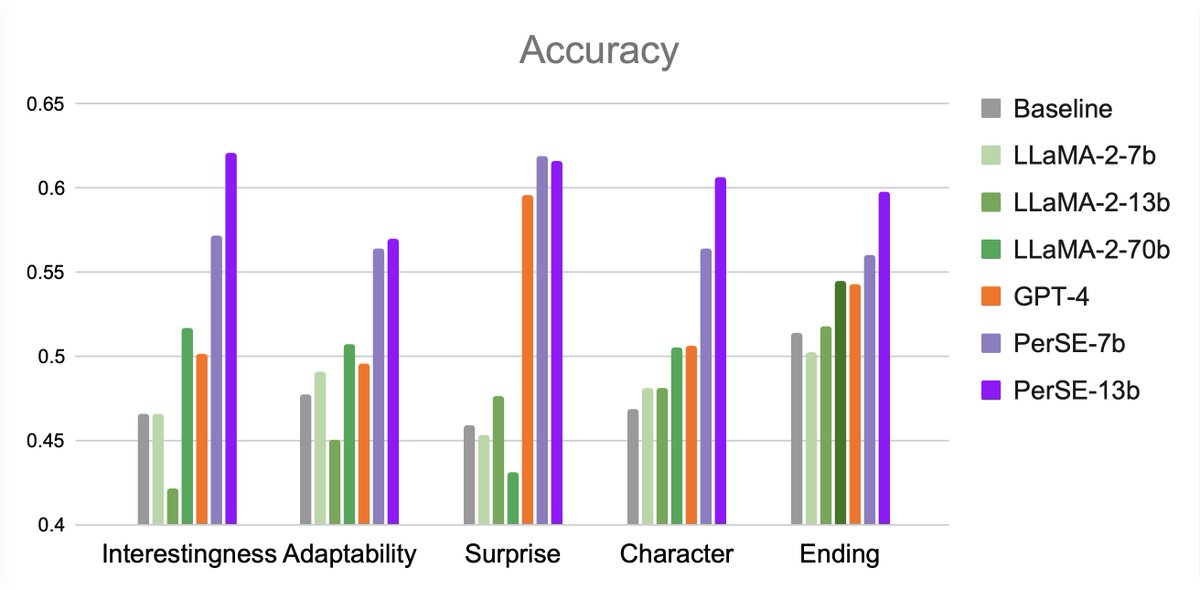
📚🌟 Evaluate any story to your heart's content with our new personalized story evaluation model, PerSE! No more worries about diverse preferences - get your own story evaluation report now! 📝🎯 https://t.co/uRIGBlnGAI
1/5
🚀✨ Experience the 𝗯𝗲𝘀𝘁 performances with PerSE! 📊🎯 It outshines in all correction metrics with 𝗵𝘂𝗺𝗮𝗻 𝗿𝗮𝘁𝗶𝗻𝗴, and boasts the highest accuracy in predicting preferred stories across five different aspects. 🔝💯
4/5
😭Tired of in-context demos & docs for LLM tool use?
💰Too GPU-poor to tune LLMs for unseen tools?
🤬Frustrated with frequent syntax errors in tool calls?
Check out our new preprint 𝐓𝐨𝐨𝐥𝐃𝐞𝐜 that addresses all these issues from the decoding side!
https://t.co/vssxVg833j
1/5
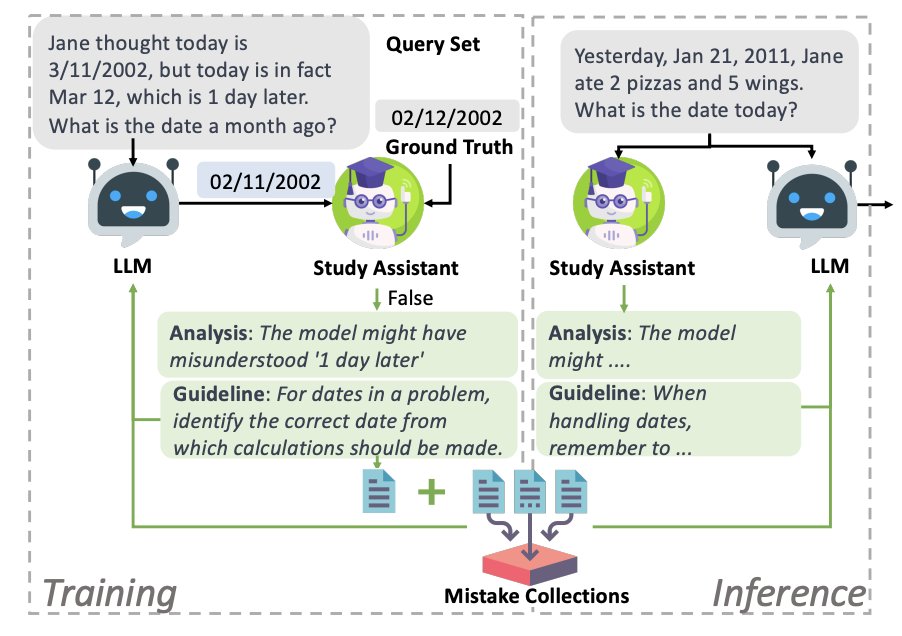
🚀 Excited to share our latest work in EMNLP main conference: "Learning from Mistakes via Interactive Study Assistant for Large Language Models". We introduce a study assistant (SALAM) to conduct thoughtful analysis on LLMs' mistakes and provide guidelines to avoid past mistakes
🧠Some observations: (1) Sometimes failure teaches more than success. (2) feedback based on ground-truth to be more reliable than self-refinement without stop signals. (3) Mistake retrieval is key for feedback, while pseudo mistakes fall short.
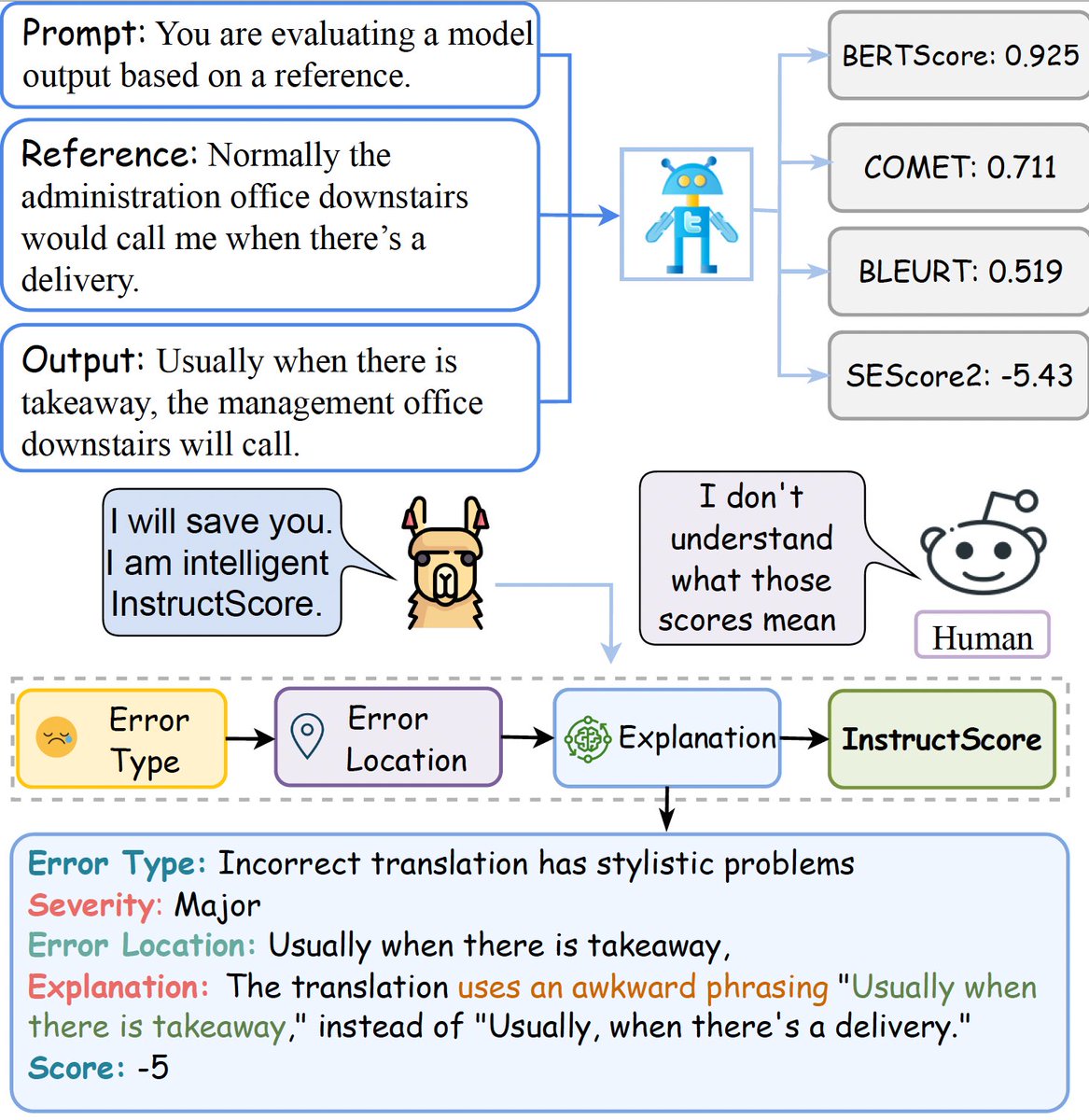
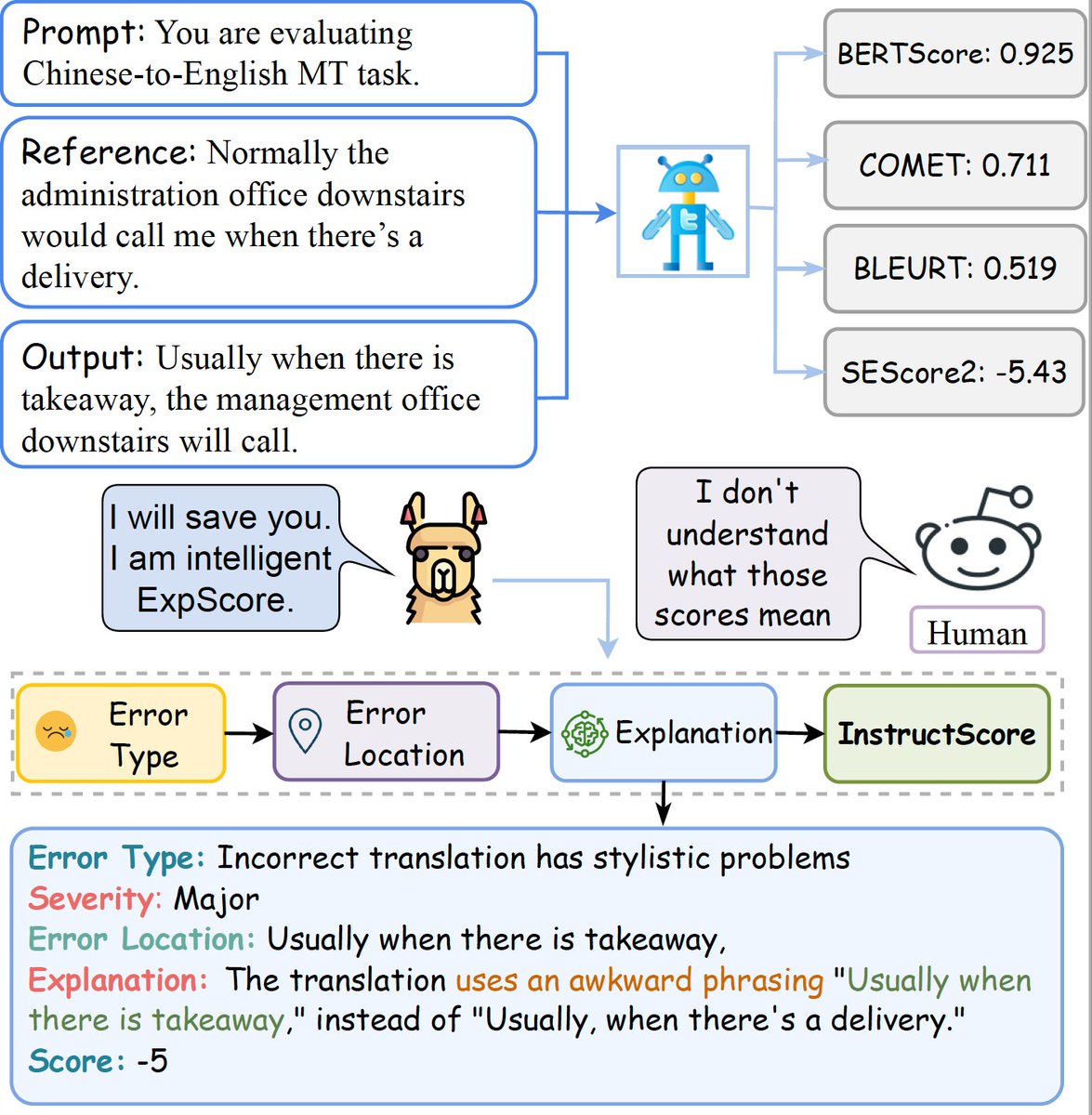
I am super excited for our proud work InstructScore to be accepted at EMNLP main. In this work, we are the first to present an explainable metric in text generation to pinpoint error types, error location, severity labels and explanations as output labels. @ucsbNLP @Google
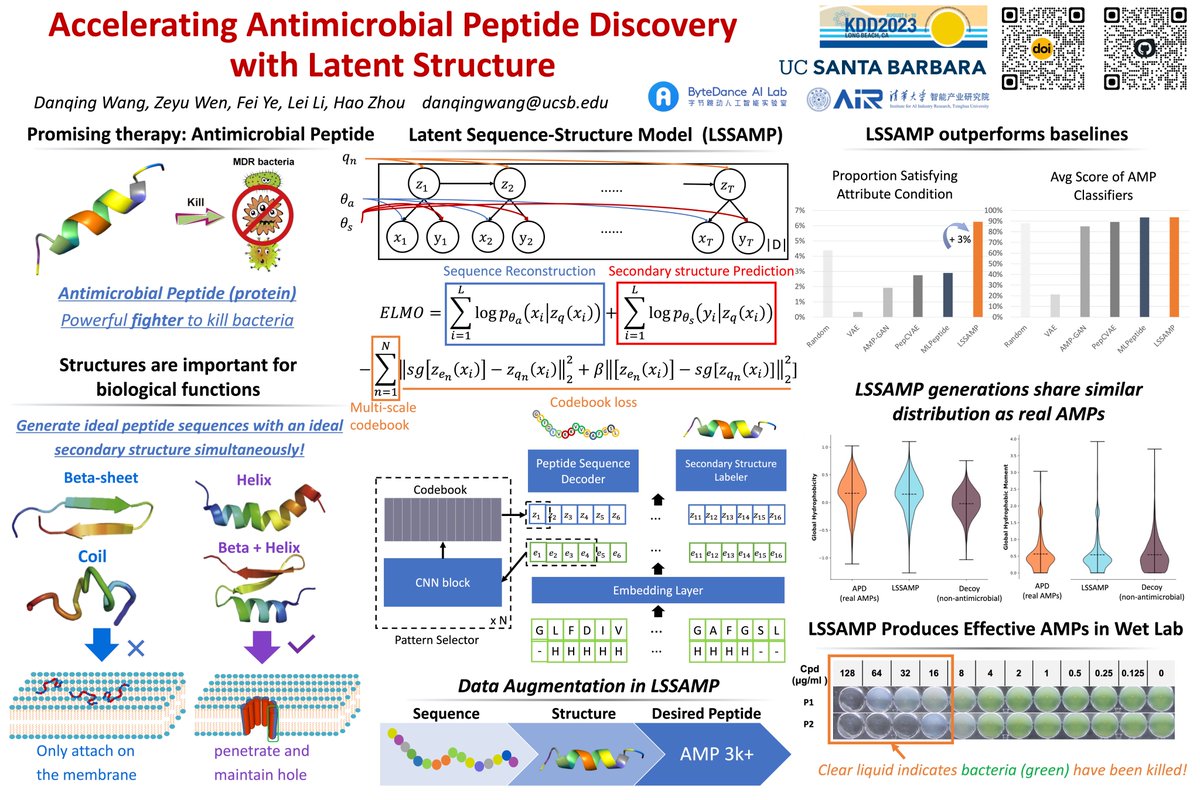
How to design drugs to kill bacteria. Danqing will present LSSAMP work on antimicrobial peptides design Wed 2pm in 201A and Tue 6pm. The core idea is generating the amino acid sequence based on secondary structure and quantized latent space.#KDD2023
Paper: https://t.co/fC3UvwvNWD
🔥 One of the most exciting things about LLMs is their ability to self-correct from feedback. But how do we keep track of all the new papers? Our survey comprehensively documents the MANY types of self-correction strategies. 🚀🚀🚀
📜 Preprint: https://t.co/dccmVhQj4F
🧵(1/8)
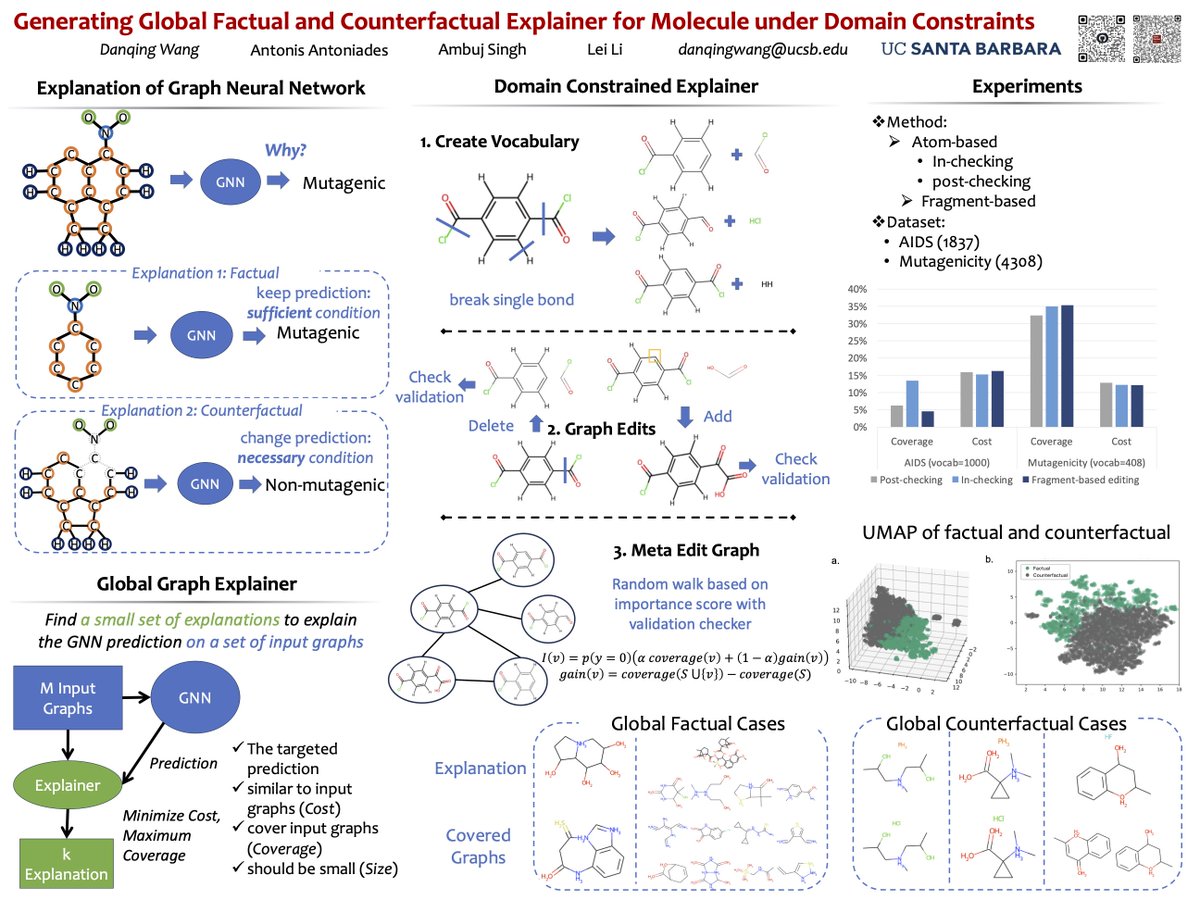
🧬 @dqwang122 is today presenting our ongoing work on generating global explanations of molecular properties at IMLH workshop, ICML. It’s been a fun project and I think this area warrants further exploration - could be a useful method for explainableAI / AI4science! (1/2)
What is missing in the text generation evaluation for BERTScore, BLERUT, COMET, SEScore & SEScore2? Explanation! Can we build a metric that not only produces a well-correlated quality score but also tell you the rationales, error type, and error location? Checkout InstructScore!
🚀Introducing ALGO, a code synthesis framework guided by LLM-generated oracles. Integrated with ALGO, Codex is 8x better and ChatGPT 1.3x better at contest-level problems. Plus, ALGO verifies your solution before submission!🧵
📜:https://t.co/QvtLAJljkr
🔗:https://t.co/Ohsjda223c