Our paper discussing the SVCC 2025 summary has been accepted to ICASSP 2026! 🥳
Check it out here: https://t.co/Ln25qtCxrX
We're still working on an extension journal paper that covers more details about SVCC, so stay tuned 😄
The first SVCC 2025 baseline system is now out! 🥳 We introduce Serenade: A Singing Style Conversion Framework Based On Audio Infilling. This preliminary investigation covers the main difficulties of singing style conversion (SSC) and details our findings.
👉 IEEE SLT 2024 Call for Recent Breakthrough Results. We invite submission of your recent findings on spoken language technology. Submit an abstract by the final deadline of Nov 15.
Submit via this form:
https://t.co/BpnFr3kjbh
@shinjiw_at_cmu@HungyiLee2@IEEE_SLTC
🚀🚀🚀 A Zero-Shot TTS model MaskGCT (Masked Generative Codec Transformer) is open-sourced in Amphion now. Trained with Emilia. Only needs 5 sec speech to clone
Paper: https://t.co/OdoQ3niCeY
HF: https://t.co/2mCZA9GLzD
Discord: https://t.co/FvmcJ5pm6z
Watch the demo by MaskGCT
👥 Keynote highlights from industry and academia! 🤝 Supported by top tech leaders and innovators!
📅 Secure your spot now: https://t.co/oQHpP9snLi
#SLT2024
The Emilia dataset, 101k hours of multilingual in-the-wild speech data, is now available to download from HuggingFace! Join the discord if you have any feedback.
HF: https://t.co/NMR7C6LOrZ
Discord: https://t.co/cEgPRt0Lho
LLM-as-a-Judge is one of the most widely-used techniques for evaluating LLM outputs, but how exactly should we implement LLM-as-a-Judge?
To answer this question, let’s look at a few widely-cited papers / blogs / tutorials, study their exact implementation of LLM-as-a-Judge, and try to find some useful patterns.
(1) Vicuna was one of the first models to use LLMs as an evaluator. Their approach is different depending on the problem being solved. Separate prompts are written for i) general, ii) coding, and iii) math questions. Each domain-specific prompt introduces some extra, relevant details compared to the vanilla prompt. For example:
- The coding prompt provides a list of desirable characteristics for a good solution.
- The math prompt asks the judge to first solve the question before generating a score.
Interestingly, the judge is given two model outputs within its prompt, but it is asked to score each output on a scale of 1-10 instead of just choosing the better output.
(2) AlpacaEval is one of the most widely-used LLM leaderboards, and it is entirely based on LLM-as-a-Judge! The current approach used by AlpacaEval is based upon GPT-4-Turbo and uses a very simple prompt that:
- Provides an instruction to the judge.
- Gives the judge two example responses to the instruction.
- Asks the judge to identify the better response based on human preferences.
Despite the simplicity, this strategy correlates very highly with human preference scores (i.e., 0.9+ Spearman correlation with chatbot arena).
(3) G-Eval was one of the first LLM-powered evaluation metrics that was shown to correlate well with human judgements. The key to success for this metric was to leverage a two-stage prompting approach. First, the LLM is given the task / instruction as input and asked to generate a sequence of steps that should be used to evaluate a solution to this task. This approach is called AutoCoT. Then, the LLM uses this reasoning strategy as input when generating an actual score, which is found to improve scoring accuracy!
(4) The LLM-as-a-Judge paper itself uses a pretty simple prompting strategy to score model outputs. However, the model is also asked to provide an explanation for its scores. Generating such an explanation resembles a chain-of-thought prompting strategy and is found to improve scoring accuracy. Going further, several different prompting strategies–including both pointwise and pairwise prompts–are explored and found to be effective within this paper.
Key takeaways. From these examples, we can arrive at a few common takeaways / learnings:
- LLM judges are very good at identifying responses that are preferable to humans (due to training with RLHF).
- Creating specialized evaluation prompts for each domain / application is useful.
- Providing a scoring rubric or list of desirable properties for a good solution can be helpful to the LLM.
- Simple prompts can be extremely effective (don’t make it overly complicated!).
- Providing (or generating) a reference solution for complex problems (e.g., math) is useful.
- CoT prompting (in various forms) is helpful.
- Both pairwise and pointwise prompts are commonly used.
- Pairwise prompts can either i) ask for each output to be scored or ii) ask for the better output to be identified.
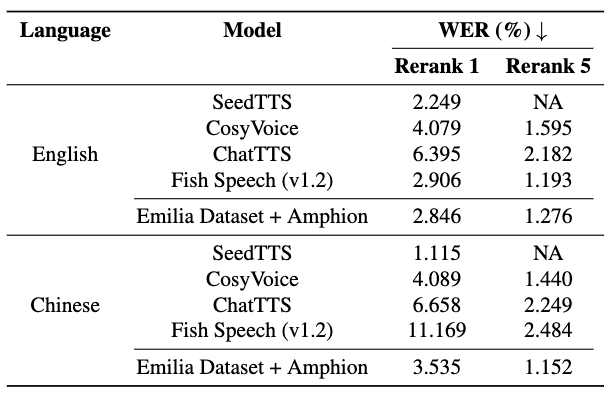
🔥🔥We have open-sourced Emilia for speech generation, a 101k-hour dataset in six languages from in-the-wild (e.g. talk shows, interviews, debates). Checkout perf of model trained with it.
HF: https://t.co/Om1BmJo357
ArXiv: https://t.co/fwuXpnlzFt
Demo: https://t.co/qXVOXxqMYD
I just submitted a changelist to remove HTS (HMM-based speech synthesis toolkit) from Google's repository.
I was the first maintainer of this open source toolkit when I was a PhD student (20 years ago!). I checked in it to the repository 12 years ago and maintained.
🚀 Excited to share SD-Eval benchmark dataset that can help LLM to understand speech better than ChatGPT 4o! It covers the understanding of emotions, accents, age and bg environmental sounds.
Paper: https://t.co/nvyPD9FbsR
GitHub: https://t.co/cBD0g04pAp
We're excited to announce the Call for Sponsorship for IEEE SLT 2024! Join us in Macao from Dec 2-5, 2024, to explore the latest in speech and language technology. Check out our sponsorship packages and enhance your organization's visibility!
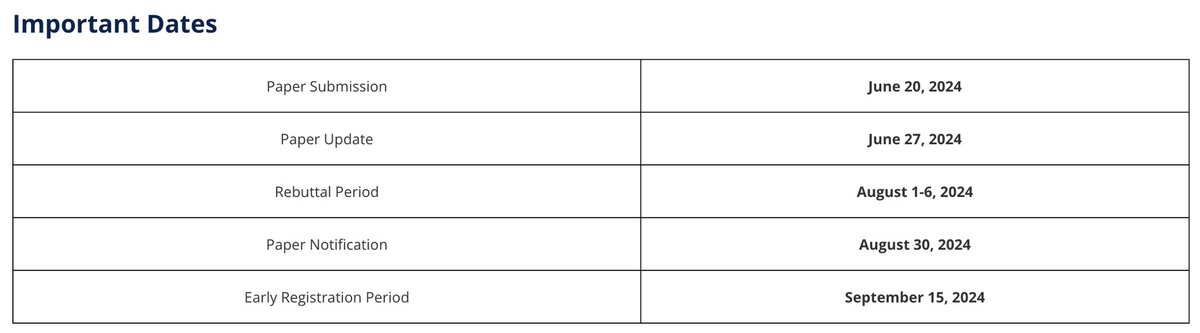
We recently concluded the challenge proposal phase for SLT 2024. Now, it's time for you to prepare your papers! Please note that the submission deadline is June 20th. We look forward to seeing you in Macao this December! #SLT2024#CallForPapers
Amphion now supports the FACodec, which is the core component of NaturalSpeech3 and the pretrained checkpoints are released.
Paper: https://t.co/bVbwpcTXBo
Checkpoints: https://t.co/CpF3zDArVZ
Demo: https://t.co/uFWnNEb309
Code: https://t.co/wUvqBoCHiD
@xutan_tx@yuancwang
IEEE Spoken Language Technology Workshop (SLT 2024) will be held in Macao later this year, China in Dec 2-5. We are calling for challenges! Make a proposal by March 13
IEEE Spoken Language Technology Workshop (SLT 2024) will be held in Macao later this year, China in Dec 2-5. We are calling for challenges! Make a proposal by March 13
IEEE Spoken Language Technology Workshop (SLT 2024) will be held in Macao later this year, China in Dec 2-5. Get your paper ready :) we are looking forward to seeing you in Macao!