Flying to Singapore to present this recent work about weak-to-strong generalization at #ICLR2025.
Nearly random weak labels can yield nearly perfect generalization for strong models, under the right scaling regimes...even if the strong model can exactly memorize the weak labels!
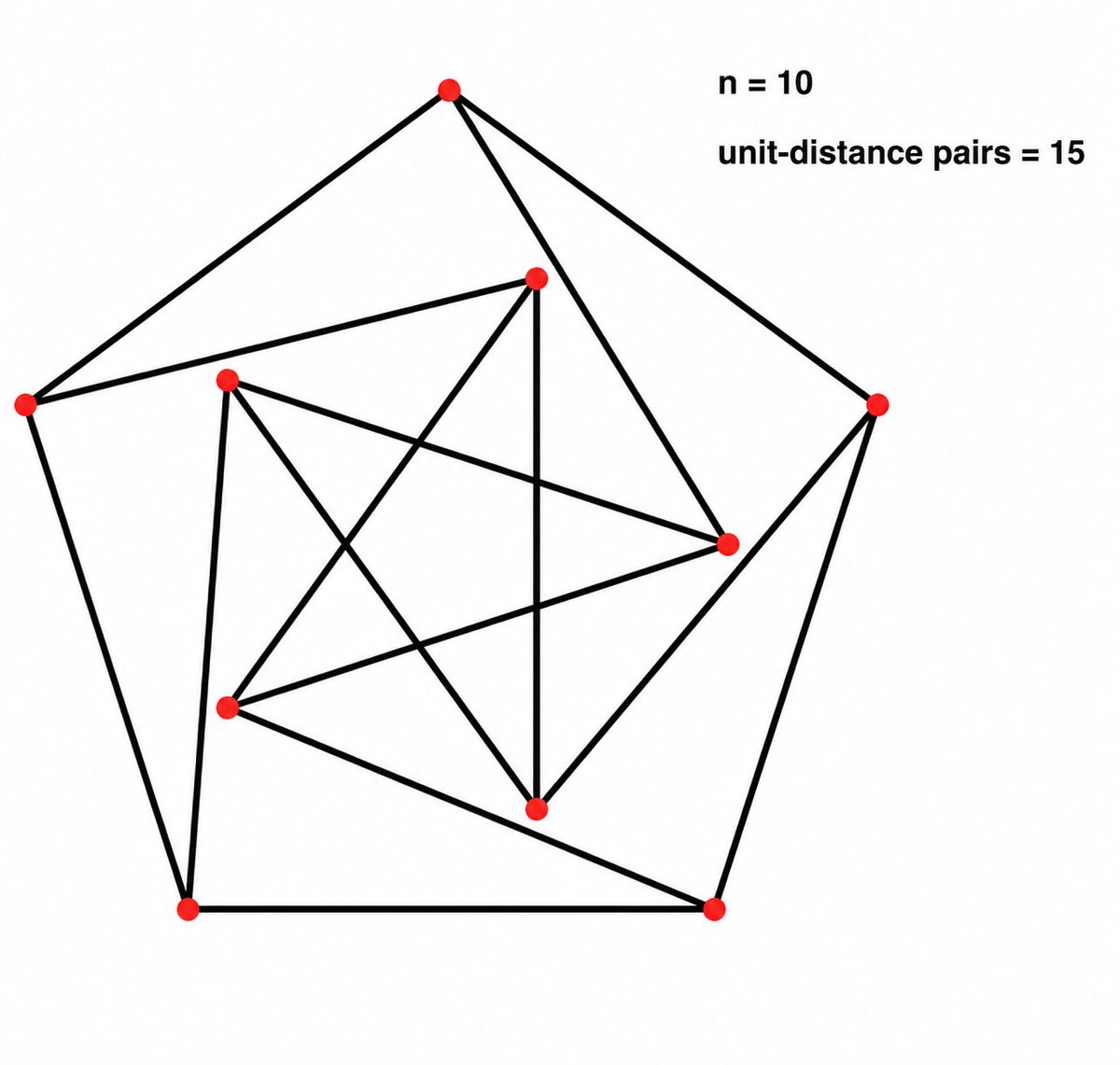
🧵(1/8) An @OpenAI internal reasoning LLM achieved an AI Math milestone: solving an open problem central to its mathematical subfield— in this case, the unit distance problem of discrete geometry.
We came across it in a side quest to truly push our model on the hardest problems.
Flying to Singapore to present this recent work about weak-to-strong generalization at #ICLR2025.
Nearly random weak labels can yield nearly perfect generalization for strong models, under the right scaling regimes...even if the strong model can exactly memorize the weak labels!
Our theory also predicts that weak logits can give *better scaling for multiclass problems* than ground truth multiclass labels when there are tons of classes. This corroborates conventional wisdom in distillation.
Presenting a poster about this recent work at the NeurIPS M3L Workshop tomorrow! Catch me there @ 4:00 PM if you want to hear more about provable toy models for weak-to-strong generalization.
We're excited to share our new preprint introducing endless jailbreaks via bijection learning.
Our attack exploits the advanced reasoning abilities of frontier LLMs like GPT-4o and Claude 3.5 Sonnet, revealing a critical model vulnerability that arises from capabilities. 🧵(1/n)
My first PhD paper!🎉We learn *diffusion* models for code generation that learn to directly *edit* syntax trees of programs. The result is a system that can incrementally write code, see the execution output, and debug it. 🧵1/n
My first PhD paper was accepted to NeurIPS'23 as a spotlight! We nail down when overparameterized linear models generalize for multiclass classification in a toy setting, using a nice new tool for concentration in sparse problems.
🧵(1/n)
That's where our new tool comes in! It's a variant of the Hanson-Wright inequality for bilinear forms of subgaussian vectors where one side is sparse. This is a standalone result which can be applied to problems with sparse labels. The proof isn't so bad either! (6/n)