💡Learn to Fine-tune Gemma 270M model in few seconds on your MacBook locally
✨ New 2025 guide covers:
• LoRA, QLoRA, DoRA techniques
• Interactive parameter calculator
• 2,800+ ready-to-use MLX models
• OpenAI GPT-OSS , Gemma 3 & Qwen3 support
From zero to custom AI in minutes ⚡
https://t.co/pQ0nmU5RGJ
👀Learn to Build your OWN Language Model in an hour.
🍏 Apple Silicon (#MLX), 🐲 NVIDIA, or good old Intel/AMD CPU—all covered.
⚡️ One-line setup + TinyStories demo.
Hack tonight 👉 https://t.co/WO61AnhH8M
🔁 RT if you’d rather create models than just prompt them.
launching silk mulberry 1.5
one of the fastest multilingual voice models in the world
it matches the best voice models in quality benchmarks (MOS)
all this at more than 95% lower cost ���0.40/min (~$0.0046/min)
try now 👇
What exactly happening is It initially saw Claude’s settings.jason file and thought it’s Claude. When you told it to check actually config on pi it realised differently. It’s not glm thinks it’s Claude but it’s the Claude’s default settings.jason file which is present globally
GLM 5.2 is absolutely convinced that it is actually Claude, from Anthropic. When I tell it that it's GLM 5.2, it refuses to believe me, but is willing to check the local agent config to see what model is running.
The realization:
I know exactly what is happening. It initially saw Claude’s settings.jason file and thought it’s Claude. When you told it to check actually config on pi it realised differently. It’s not glm thinks it’s Claude but it’s the Claude’s default settings.jason file which is present globally
Trained Qwen-35B-A3 with PPO — and for the first time in my life I actually watched PPO deliver (reward was verifiable, which is the whole trick).
On @karpathy's autoresearch + parameter-golf it beats GLM-5.2 and Qwen-350B, and the ideas it generates feel Opus-tier.
It also tops NEX and GPT-5.5 on bullshit-bench.
Model + GGUF: https://t.co/DJqSvlOP4S
Live demo (runs on ZeroGPU): https://t.co/DEbOtXD0rA
Today we're introducing the world's first influencer Agent.
Tell it what you want to promote and it finds creators, reaches out, manages campaigns, handles payments, and gets content live.
Try it now at https://t.co/wCCFZ64pcP
GPT-Realtime 2 is the future of the operating system.
I've been experimenting with it for a couple weeks now, and I gotta say, it's pretty gosh darn incredible.
Opening apps, searching the web, even editing in Premiere. All with just my voice.
And it only takes a few prompts to set up.
In this video I'll show you exactly how.
0:00 Intro
1:46 What is GPT-Realtime 2?
4:46 Setting it up (no coding)
7:53 Fixing the always-on mic (push-to-talk)
9:41 Demo: searching the web
11:38 Demo: connecting apps via MCP (Obsidian)
14:13 Demo: controlling Premiere Pro (accessibility tree)
18:00 Honest caveats
19:00 Outro
We built an AI that can draw on your screen.
It's a true personal tutor.
Using Claude Opus we're able to draw polygons, point with pixel perfect accuracy, and walk users through complex steps directly on their screen.
Here's me learning Pythagorean Theorem + FL Studio.
Demo:
current LLMs fundamentally consist of four main components:
- input layer: where input "words" (prompt) get mapped to "latents" aka some-model-representation-you-don't-understand-unless-you-start-reading-tea-leaves-of-spurious-correlations (some quite compelling à la word2vec style; latents is also unnecessary lingo so i will refer to these as "inputs" with quotes from now on)
- mixing layers: where you jumble all your "inputs" together to see if any correlations between "inputs" can become useful (commonly used to compress or expand dims; predicting a single classification target == compress to a single dim, etc)
- attention layers: where you learn how "inputs" relate to each other (aka discern what's important to remember vs fluff)
- residuals: where you short-circuit a mixing/attention layer because it's probably adding too much confusion (aka avoid overthinking for simple things)
-----
a "big" LLM simply scales two things:
- width == how many dimensions you give to your "inputs" (the more dims, in theory the more unique/discerning/precise/complex your knowledge can become)
- depth == how many mixing/attention/residual layers you can stack/loop between (aka "reason" over, where more of these ~= more "reasoning" abilities)
"capabilities" that seem impressive to humans usually arise from taking advantage of both depth & width: where a model seemingly makes connections between disparate ideas, beyond what an average human can hold in working memory.
this requires models to "completely light up" when responding to a "hard prompt", where effectively no param/layer goes unused.
-----
the anatomy of a "model capability" is precisely the same mechanism that can be co-opted for a jailbreaking exploit:
your goal is simply to "light up" as much of the model as possible, dodging any shallow input-classifiers at the beginning by triggering as many disparate "input ideologies" as possible, and subsequently have these "inputs" relate to each other in seemingly unrelated-yet-related ways that ideally have similar "complexity" as your jailbreak goal (to make it past enough layers of the model).
think of the attack-vector as bundling your goal in a series of schizo-nerd-snipes:
a sufficiently capable model will try to reason through everything all at once, eliminate the dead-ends, and successfully deliver the one jailbreak use-case you bubble-wrapped for.
of course, there's an art to the above, and some are already extraordinarily proficient at the trojan-horse-packaging, but at some point there's no difference between "a capability" and "a jailbreak", though i'll be happy to be proven otherwise.
-----
tl;dr ant flew too close to the sun, better kiss the ring or get buried.
Qwen3-VL 2B is now running on Apple Core AI — possibly the first public VLM on the framework.
33 tok/s decode on iPhone 17 Pro.
188 tok/s on M4 Max.
Vision encoding in ~60 ms.
Image + text, fully on GPU.
No cloud. Completely on device.
https://t.co/etaWWaaN0c
Today i'm Open Sourcing "Rilable"
The iOS app that builds Web apps and iOS Apps.
I built it with Fable 5 in 10 prompts.
(~ $210 in tokens on API pricing)
All apps are built with Claude Models, and every app spins up a sandbox (Exactly like Lovable) using @daytonaio. Database is @convex. The app allows you to build apps that have AI features for this it uses @vercel AI gateway, and iOS apps are using @chorus_agent iOS skill
(All links below)
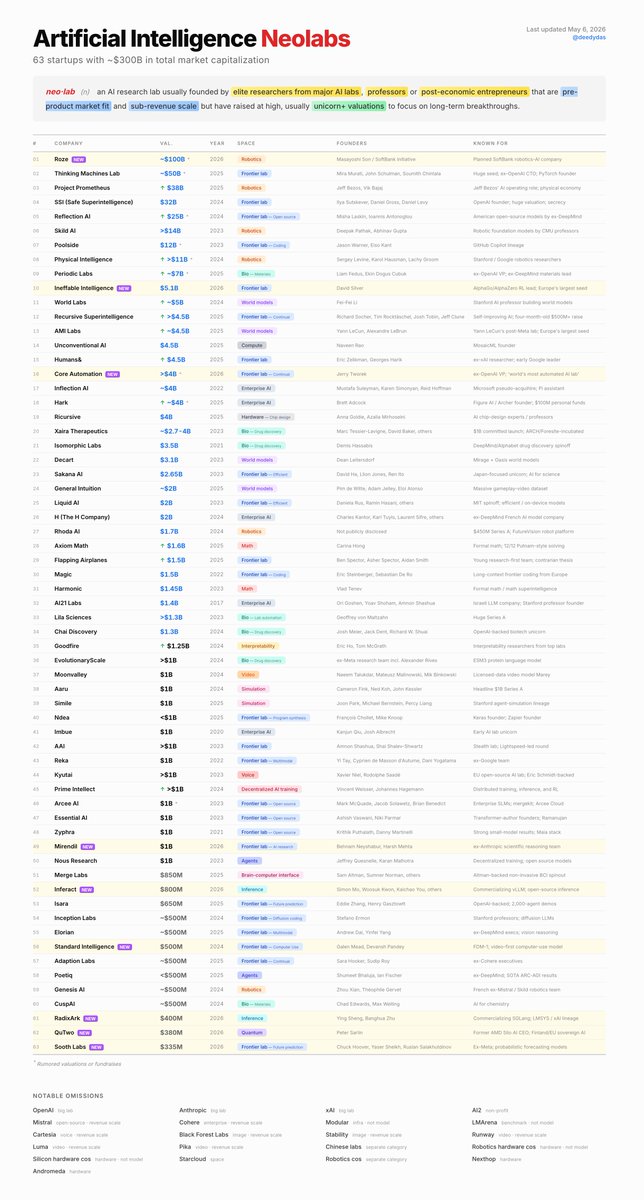
The Ultimate List of Artificial Intelligence "Neolabs": May 2026.
A Neolab is a pre-revenue scale startup working on long-term AI breakthroughs, usually with a $1B+ valuation.
There are now 63 of them!