Opa Pessoal, atualização do projeto de exemplo de separação de datasources (banco de dados) do tipo read e write dentro do Spring Boot usando a estratégia Routing DataSource.
Colocar transações de read e write no mesmo esquema de configuração é mais fácil, porém tenho observado que transações do tipo leitura têm uma penalização de ~6 a 15 vezes de performance com relação a operações de escrita de controle mais rígido.
Transações do tipo read podem ser sustentadas por frameworks como o Hikari CP, enquanto que do tipo write usando o Atomikos (suporte ao JTA). Não apenas a questão de desempenho, mas a questão de segurança, que uma operação de leitura não gere escrita indevida.
Ainda evoluindo no campo das ideias e testes. Agradeço aos amigos pelas discussões técnicas sempre proveitosas.
https://t.co/9nmWM5IoUz
Feriado é dia de janela de manutenção. Afinal, só quando vocês saem da tela que nos dão paz para desligar algumas coisas. Vim num data center deixar materiais para a equipe local e na chegada o que vejo no terreno ao lado? Essas bolas brancas são domos de proteção das antenas terrestres da Starlink.
O satélite maioritariamente funciona como um espelho, refletindo o sinal de volta para bases como essa em solo brasileiro que o converte em fibra ótica.
A maior parte do volume de tráfego da Starlink no Brasil é atendido por conteúdo em servidores hospedados em data centers como esse onde estou agora. E aqueles ainda hospedados no exterior, o tráfego percorre cabos submarinos e terrestres até localidades como o essa.
Mês passado (maio/2026), fiz um uso intenso das #LLMs (modelos de #IA) por agentes e chats na minha infra local (onde concentro muito dos meus labs).
Parei aqui um pouquinho para contabilizar a quantidade de tokens (~0.705 de uma palavra) de entrada e saída, curiosidade. Tive de tokens de inputs ~334.6M e tokens de output ~1.71M.
Esta quantidade de tokens se converte em texto de diversos fins, em comandos, construção de ambiente, protocolos de comunicação, revisões de código, etc.
Por estimativas, tive ~21% de taxa de perdas de processamento, seja por repriorização de execução de tarefas, má especificação de prompts, loopings de execução interrompidos, timeouts, reconsideração de fontes de dados ou configuração não eficiente.
O valor adicional do consumo de energia para 3 máquinas (funções diferentes) ligadas 24/7: ~R$ 180. Teve uma elevação do valor devido à maior carga de processamento, habitual de ~R$ 110.
Considero positivo o ganho de experiência e o valioso auxílio dado nas inúmeras tarefas realizadas. Sempre é importante ter paciência nas leituras, realizar reflexões técnicas, testar e verificar.
Obs.: Tenho também assinatura de LLM no cloud.
Tokens são simplesmente números que representam como o LLM (cérebro da IA) "pensa" sobre o texto que você fornece. O processo de conversão de texto em tokens é chamado de codificação (encoding) e ao contrário (decoding). Logo, o computador não entende diretamente palavras e sim, como sempre foi, apenas números.
https://t.co/f3e1URlB9Y
Fiz o preenchimento da declaração do imposto de renda (atrasadinho, mas no prazo rsrsrs). Recebi aquela mensagem de erro: ERRO! O ARQUIVO NÃO FOI TRANSMITIDO...
Aí tentei ontem novamente e a mesma coisa. Hoje pensei: será que a Receita usa uma outra porta TCP diferente da 433 e por isto o IpFire esteja bloqueando a comunicação na minha rede?
Aplicado o lsof no processo computacional da Receita:
java 628861 eduardo 116u IPv6 1220951 0t0 TCP note:52370->189.9.71.11:3456 (SYN_SENT)
Pronto! Achei a porta TCP 3456. Liberado no Firewall e declaração entregue.
@gagaruano Fiz umas contas como esta aí e acabei comprando tudo AMD: GPUs e processador. No GNU/Linux Debian a AMD é muito mais tranquilo que a NVIDIA.
NVIDIA é TOP, mas a AMD é uma alternativa muito boa.
Relatei ao meu agente de #IA, de nome hefesto, uma dificuldade, pedi um docker compose para gerar um monbodb com base em um link do https://t.co/uHgsVwdbSA para resolver a questão mais tarde, depois das 22h. Este pedido foi às 10:30 da manhã.
Ele se empolgou tanto que está até agora trabalhando, organizando tudo, criando painel, testando, pesquisando, etc. Já passou das 23h. Não sou eu que interromperei a empolgação dele.
Ainda bem que a infra é local, senão o balde de tokens já tinha estourado várias vezes, impossibilitando a continuação da empolgação dele.
Obs.: Agentes sempre devem executar dentro de uma máquina virtual ou dentro de um contêiner.
Voltando para a versão 2026.5.7 do #openclaw. A versão 2026.5.12 parece bugada.
Reverting to version 2026.5.7 of #openclaw. Version 2026.5.12 appears to be buggy.
Tem uma coisa que as pessoas esquecem por suas paixões políticas: que ninguém daria ~61 milhões para produzir um filme de um político por pura convicção de que estaria fazendo a melhor coisa do mundo, e pouco menos vindo de um banqueiro.
Lógica simples: ~61 milhões em 4 anos de favores em um mandato de um presidenciável seriam multiplicados entre 7,5 a 39 vezes para cada 1 real, ou seja, se teria ao final o montante entre ~457 milhões a ~2,3 bilhões de reais por estimativas. E assim também foi nos outros governos, é só pesquisar e fazer as contas.
Nem o melhor investimento do mundo por 20 anos daria tanto dinheiro como este esquema de favores. Então, deixe de paixões que só estão atrapalhando...
Linus Torvalds acaba de dejar claro que Linux no va a convertirse en un basurero de código generado por IA.
Después de meses de debate interno, la comunidad Linux publicó sus reglas oficiales sobre el uso de herramientas como GitHub Copilot.
El veredicto: se puede usar IA para programar, pero el "slop" ese código de baja calidad escupido sin pensar, no pasa el filtro.
La frase que lo resume todo: "Los humanos asumen los errores."
Puedes apoyarte en Copilot, en Claude, en lo que quieras. Pero si ese código entra al kernel de Linux, tú eres el responsable.
Tú lo verificas. Tú corriges los fallos. Tú garantizas que cumple los estándares.
Es la postura más madura que he visto en el ecosistema open source frente a la IA. Ni histeria, ni adopción ciega. Solo responsabilidad clara.
El kernel tiene 30 años de historia.
No lo van a arruinar por ahorrar 20 minutos con un autocomplete.
‼️🚨 Security researcher ggwhyp demonstrated a full-chain Firefox exploit on Windows.
He opens an HTML page, Firefox runs the code, cmd.exe spawns, Calculator opens. Signature of a browser-to-OS exploit.
Prepared for Pwn2Own. ZDI rejected it. According to the researcher, it was responsibly disclosed to Mozilla.
Esta brincadeira deve sempre ser feita dentro de uma máquina virtual, de preferência um KVM/QEMU com snapshots frequentemente:
This exercise should always be performed within a virtual machine, preferably a KVM/QEMU with frequent snapshots:
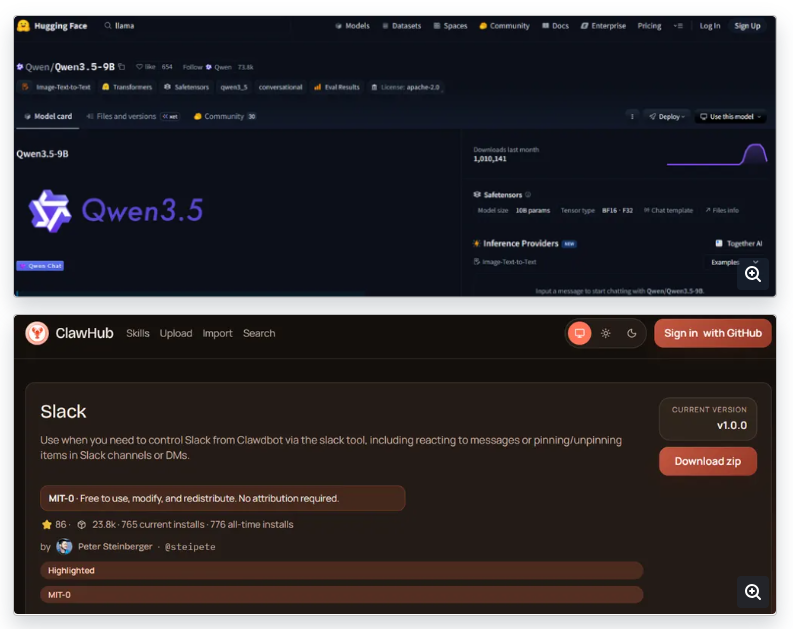
⚠️ Attackers poisoned Hugging Face & ClawHub (OpenClaw) with 575+ malicious skills from just 13 accounts.
🔸 Fake helpful AI tools that install trojans, miners & stealers (Windows + macOS)
🔸 Use hidden commands & indirect prompt injection
Quick action: Never install random AI skills or models. Always verify the source.
Read: https://t.co/CmdDBXuzTy
🇧🇷 Deputado quer que o https://t.co/rbwVlu12iO emita "Token de Maioridade Digital" para que brasileiros acessem sites pornô.
De acordo com o projeto de Fábio Teruel (MDB/SP), o token terá validade de 24h e uso único. Sites que não aderirem podem ser bloqueados e pagar multa de até R$ 5 milhões.