me: new at meta, doing something for the _right_ reason: tells coworker to take my urgent code and land the diff bc it'll get into prod faster w/ his expertise
manager: doesn't believe my story, gaslights me about ownership
Using coding agents extensively make me change my way of writing prompts. I move more and more towards incorrect English, a bit like the caveman skill. Instead of writing "show me the plan for the first proposal" I write "show plan for 1".
It looks like people who master less English than natice speakers would get an advantage. Fortunately is it my case.
@Grubhub same economic conditions for people all over the world now token quotas: "this employee is leaving? can I have his tokens?", "going on holiday? tokens?"
was inspired by the time when I was at @Grubhub where we'd get weekly meal credits that expired at EoW if you didn't use them, so we built a way transfer them to coworkers and et voila a market was bourne!
Uber's 16th birthday coming up ...
thinking about a "summit" for the OG's... any ideas? who'd be down to show up?!
startDate < 9/2015
X^x^x ... iykyk
🤔🚘🥳 #UberGetsItsDriversLicense
Location poll...
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
On "Why would I pay for SaaS if I can vibe-code it?". Here's my 🌶️ take:
1) Headcount
You don't need as many engineers as you had. You can do with less. But the reality is that you could already do with less even before AI. That's management honesty.
1/4
@yaroslavvb thanks for sharing. ur comments around 39m made me think of Napoleon, where he wouldn't open letters until after many weeks or a follow up was sent! apply to emails, slack...
ARC Prize 2026 just launched — $2M in prizes across two tracks.
The new main track, ARC-AGI-3, is wild: hundreds of interactive game-style environments with no instructions, no rules, no stated goals. Agents must explore, figure out what winning looks like, and adapt. Humans score 100%. Frontier AI scores 0.26%.
Worth remembering how last year played out: NVARC (NVIDIA Kaggle GMs) scored 24% on ARC-AGI-2, miles ahead of 2nd place at 16.5%. Their approach — fine-tuned small models on synthetic data — was cheaper and more effective than frontier model approaches. Yet the organizers buried them under "Honorable Mentions" because it wasn't the right kind of progress for their narrative.
https://t.co/nDrwcOcsx8
Fraud model idea: separate base-rate priors from transaction evidence, then add them in logit space. Test corr(prior, evidence) = 0.038, suggesting the evidence tower learned a distinct corrective signal rather than just amplifying priors.
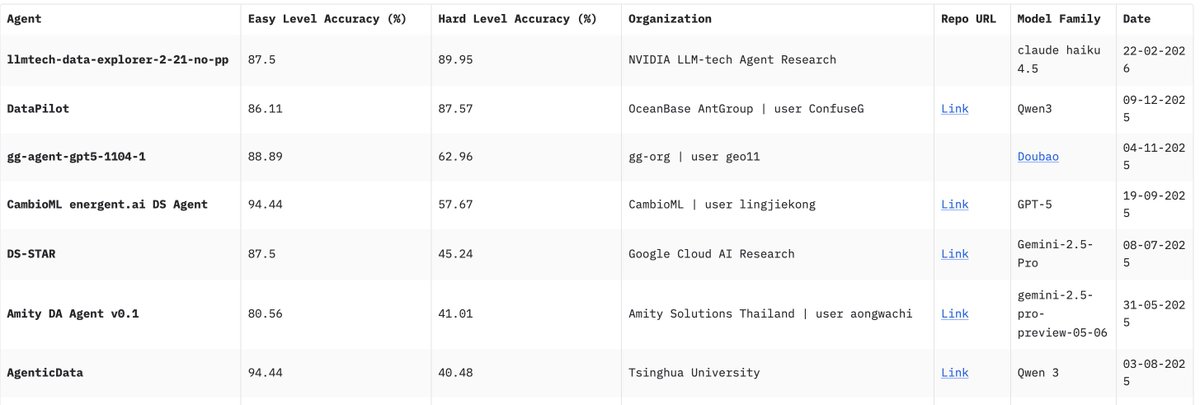
Very proud to share that @JiweiLiu, @MJeblick , and @jackyu815 from my team just won DABStep benchmark with an agent that learns from the tasks it solves.
We'll share more details ASAP.
https://t.co/AJgaEI6YxC
This was asked for for YEARS and I could never find time to build it myself
🗺️ Hoodmaps for 🏡 Airbnb
Hoodmaps is my app that lets you find out where to stay in a city, it classifies neighborhoods by:
🟥 Tourists
🟨 Cool
🟩 Rich
🟦 Suits
⬜️ Normies
I asked Claude Code to build it and it kinda works, not perfect but a start
I just need to get the map to update faster and then publish it as a Chrome extension
For now you can try it though:
https://t.co/hVQKlD6QEV
Copy paste that in console on Airbnb map, type your city as a slug (like los-angeles) and it should work
Happy booking!!!
We made a blind taste test to see whether NYT readers prefer human writing or AI writing.
86,000 people have taken it so far, and the results are fascinating. Overall, 54% of quiz-takers prefer AI. A real moment!
https://t.co/Gpbr3TAiiI
1) do bm25 hard neg mining (DPR paper)
2) verify pos pairs w/ LLM (if possible)
3) full softmax for each pos pair (devil in details)
at runtime you get amortized LLM inference
(could we get most of the way w/ steps 1-2, sampled softmax and just larger batches??)