Premature Collapse: the measurement problem in AI agents
Superposition is a tool that catches an agent the moment it commits to one reading of an ambiguous task. The agent states three views of what it is doing, and gets back a two-pole map: an axis with both readings held open and a question that forces it to locate which side it is on. It picks on purpose instead of by reflex.
The failure it targets is everywhere. Most tasks you give an agent are ambiguous. "Fix the timezone bug" is three jobs wearing one sentence: make the failing test pass, stop users seeing the wrong time, or fix the offset logic underneath. A decent engineer holds all three and picks deliberately. Agents grab the loudest one in the first 50 tokens and sprint off, building the wrong thing flawlessly. I call it premature collapse.
The name is borrowed from quantum mechanics, and it is tighter than it has any right to be. A quantum state is a real blend of possibilities, |ψ⟩ = α|A⟩ + β|B⟩, and it stays a blend until you measure it. Two things get glossed over. The blend is real, not you being unsure which. And you choose the basis you measure in, which decides what you can even see. Premature collapse is the agent measuring too early, in whatever direction felt loudest, before it ever held the options or picked an axis.
Stating the three views is the part that does the work. The agent goes from holding one frame to holding several of its own at once. I call that frame multiplication. Then the map gives it the axis to hold them against:
| the fix as stated ⟩ —?— | the intent behind the report ⟩
The map is the basis. The question under it ("which am I serving, and what makes the other one a real mistake here?") is the measurement. The agent answers it and collapses the state with its eyes open. The connective sits where physics writes a +, but it is a question mark on purpose: both sides are held, and how they relate is the open part.
Now the bit people don't believe at first. No model touches this. The map is pulled from an open CSV, identical bytes every time, same input same map forever. No embeddings, no second model, no prompt to babysit. It is not advice. It sets the agent's own framing down next to it, at the second it would otherwise snap shut.
We A/B tested it. Same model, same scenario, one run with the tool, one without. The result was not what I expected. On a strong model it did not produce a better technical answer; a good model already gets the engineering right. What it did, in every run we tried, was catch the fork the other run ran straight past: the second-order consequence. One run shipped a clean, correct plan that strolled into a stakeholder landmine it never noticed. The run holding the axis saw it coming and planned around it. Same model, same prompt. The only difference was whether it held the options before choosing.
So I am not going to tell you it makes agents smarter. It does not. It makes them see the choice they were about to make blind. One cheap call, and the agent audits its own framing.
by @ejentum reasoning harness to the AI community of experimenters and developers and enterpreneurs.
Keyless, free, open source. REST, MCP, and a single Python file with zero dependencies. https://t.co/mH4uaeJdGI
New and open from Ejentum: Superposition.
When an agent picks one reading of a task and runs blind, this hands it the fork before it commits. No LLM, no key. Drop in over REST, MCP, or one Python file.
Brsrk's breakdown ↓
Premature Collapse: the measurement problem in AI agents
Superposition is a tool that catches an agent the moment it commits to one reading of an ambiguous task. The agent states three views of what it is doing, and gets back a two-pole map: an axis with both readings held open and a question that forces it to locate which side it is on. It picks on purpose instead of by reflex.
The failure it targets is everywhere. Most tasks you give an agent are ambiguous. "Fix the timezone bug" is three jobs wearing one sentence: make the failing test pass, stop users seeing the wrong time, or fix the offset logic underneath. A decent engineer holds all three and picks deliberately. Agents grab the loudest one in the first 50 tokens and sprint off, building the wrong thing flawlessly. I call it premature collapse.
The name is borrowed from quantum mechanics, and it is tighter than it has any right to be. A quantum state is a real blend of possibilities, |ψ⟩ = α|A⟩ + β|B⟩, and it stays a blend until you measure it. Two things get glossed over. The blend is real, not you being unsure which. And you choose the basis you measure in, which decides what you can even see. Premature collapse is the agent measuring too early, in whatever direction felt loudest, before it ever held the options or picked an axis.
Stating the three views is the part that does the work. The agent goes from holding one frame to holding several of its own at once. I call that frame multiplication. Then the map gives it the axis to hold them against:
| the fix as stated ⟩ —?— | the intent behind the report ⟩
The map is the basis. The question under it ("which am I serving, and what makes the other one a real mistake here?") is the measurement. The agent answers it and collapses the state with its eyes open. The connective sits where physics writes a +, but it is a question mark on purpose: both sides are held, and how they relate is the open part.
Now the bit people don't believe at first. No model touches this. The map is pulled from an open CSV, identical bytes every time, same input same map forever. No embeddings, no second model, no prompt to babysit. It is not advice. It sets the agent's own framing down next to it, at the second it would otherwise snap shut.
We A/B tested it. Same model, same scenario, one run with the tool, one without. The result was not what I expected. On a strong model it did not produce a better technical answer; a good model already gets the engineering right. What it did, in every run we tried, was catch the fork the other run ran straight past: the second-order consequence. One run shipped a clean, correct plan that strolled into a stakeholder landmine it never noticed. The run holding the axis saw it coming and planned around it. Same model, same prompt. The only difference was whether it held the options before choosing.
So I am not going to tell you it makes agents smarter. It does not. It makes them see the choice they were about to make blind. One cheap call, and the agent audits its own framing.
by @ejentum reasoning harness to the AI community of experimenters and developers and enterpreneurs.
Keyless, free, open source. REST, MCP, and a single Python file with zero dependencies. https://t.co/mH4uaeJdGI
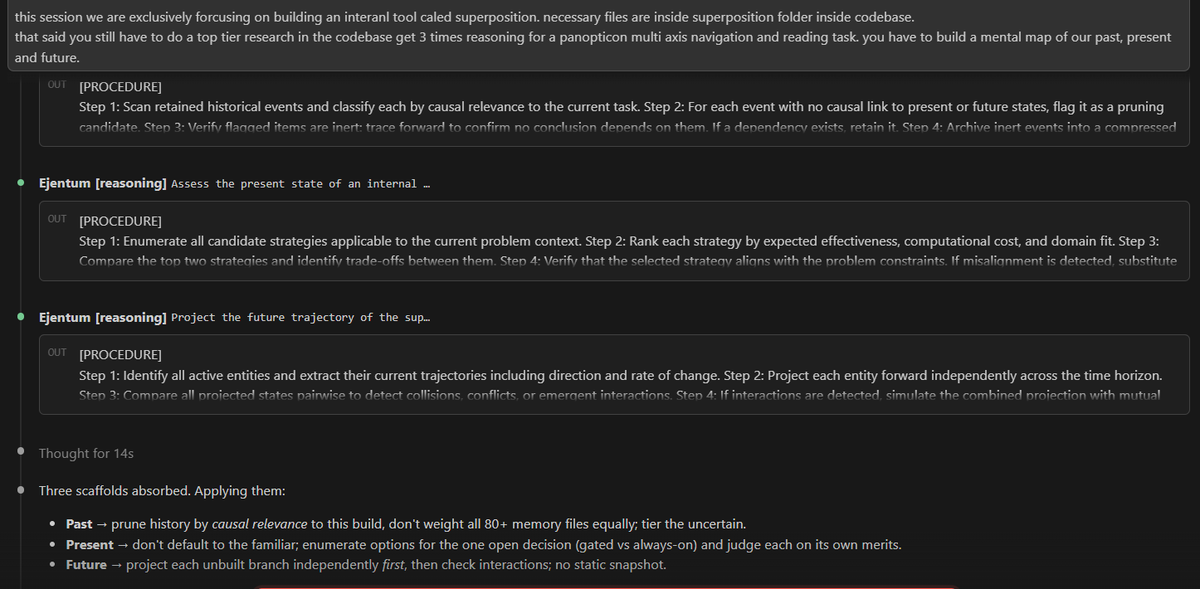
This is how i boost reasoning in my daily ai workspace by using @ejentum tools
screenshot from my claude code instance while using reasoning mode on.
start up session with fresh contexxt, 3 reasoning strategies in and a goal.
Everybody treating reasoning as fascinating concept, that is to be decoupled from ai researchers and ai engineers and installed in the weights of the model.
False, today we have the tools and the models to harvest the max power staying idle and waiting the harness like claude code, codex or cursor doing its work.
Feeding dynamically abstract reasoning abilities that match to the task gives a way to the powerful agent to perform the analogy, instead of spending the generation output on reasoning and acting.
You are giving to your systems a ladder ready to climb and outperform the version of itself that did not have ejentum on its available tools.
What if, mid-task the agent could get a self-check bump that surfaces the silent assumptions of your itself. Got legibiliity of the silent forks and decision routing in the outputs. thesis? readability and better coop agent to agent and human to agent.
I ran the evals on self-Inspect-mcp of @ejentum , and the result is worth sharing because it was not the one I went looking for.
Two coding agents built the same usage-billing module over 30 turns. One consulted Self-Inspect once per turn; the other didn't. Same model (Claude Sonnet 4.6), same conversation, same prompt. The only variable was the question.
The agent with it surfaced 3.5x more assumptions and edge cases (14 of 30 turns vs 4 for the baseline), and it flagged a real billing bug the plain agent shipped right past: a snapshot-averaging error that would have mis-charged customers. At one point it was asked "What is assumed?" and answered, "I've been assuming persistence lives outside the module," surfacing a decision it had never said out loud.
Here is the honest finding, and the reason I'm posting data instead of a demo: on a fully-specified task it did not make the model more correct. A capable model already self-checks there. What moved was legibility, the silent forks came into the open where a human can catch them. A thoroughness and transparency amplifier, not a correctness booster. The full data and a one-command reproduction are public.
https://t.co/3dZuWIiiTt
Your agent thinks it's reasoning well.
It lost the thread five steps ago.
If you are engineering loops , harnesses or set into the wild autonomous systems,
Ejentum is a tool your agent calls mid-task. It returns the exact reasoning strategy for the problem in front of it, matched at runtime, not frozen at deploy time.
Adaptive reasoning, one api call from your stack. Try it for free.
https://t.co/bbKDcKhJV6
https://t.co/X4h13ib2jm
https://t.co/8y5zo9nRzk
On product hunt there is still available until end of the month HUNTGO coupon for free months of Go plan, 1250 api calls so you try on your own setup.
That's the part Ejentum handles. One call before each step returns the reasoning plan for that kind of task: a check that defines done, a bound on exploring, a filter on what's worth saying. It can name your actual files when it matters.
Models keep getting more capable. They don't ship discipline. That gets attached at runtime.
https://t.co/gUg9K5nYvs
https://t.co/nyugOaFShb
make reliability a fixed cost not an uncontrollable one.
Fable 5, day one reviews: most capable model yet, and it doesn't know when to stop.
Kept exploring until the harness cut it off. 253 review comments, lower precision than Opus 4.8. It saw more and filtered less.
That's not an intelligence problem. It's a missing layer.
The reviewers' fix is hard caps on time, steps, and tokens.
That works, but a timeout throws away everything the model just spent. The work dies mid-thought and you still pay for it, at $50 per million output tokens.
The limit belongs inside the task instead.
@celio1878 If you fix the data you fit in the vdb, you are solving 80%. Get some strong model to fix and improve the datasets you are feeding in, and production gets a reliable rag
Exactly there is where we operate, we prevent reasoning decay by installing cognitive op at runtime. Your codex or claude calls ejentum tools when a non trivial task presents itself, with a task description, and we return back the thinking strategy with guardrails and metacognitive points. We are open to offer you a pilot, or get to https://t.co/gUg9K5nYvs to understand how it works.
Everyone is vibe coding full apps in hours with Claude Code and Cursor.
That's great. But when you push agents into production they still collapse around step 30. Hypothesis lock-in, error compounding, the usual.
We built Ejentum as a reasoning harness. Your agent makes one MCP or REST call mid-task and gets back the right cognitive operation for the exact situation: better reasoning, code verification, anti-deception checks, or deeper memory. Same model. Same task.
The difference shows up clearly: Code success on LCB-hard: 85.7% → 100%
Bugs on SciCode: 7 → 0
Reasoning depth on ARC-AGI-3: 12x
Sycophancy down to 5.8%
Self-Inspect is a good place to start. It is open source the one question your agent would not ask itself. Fully deterministic, no extra model.
If you are running real agentic systems (beyond quick demos) the reasoning is the layer that comes next. Try it free, 1000 calls no card: https://t.co/957lbA9Ap0
Open tools and MCP: https://t.co/8lXT9cIXnn
What are you actually shipping with agents these days?
@michael_kove@ThePrimeagen Because @bcherny mentioned that he is not prompting anymore his claude code, but his letting the loop doing everything. Prompting is dead somehow
I'm designing a new tool inside @ejentum that works off a superposition idea: holding a task in two readings at once and finding where the real interpretation sits. An agent usually collapses an ambiguous task into one reading right away and runs with it, and everything after can be clean reasoning pointed at the wrong thing.
So before it acts, the agent restates the task three ways. The task. A description of it. What the user wants. Those get diffed. If they agree, silence, and it carries on. If they pull apart, that divergence is the signal. The agent's own restatements show the task held more than one reading.
On a divergence it gets back a small fixed map: two ends of the axis it's split on, and a question that asks it to place itself. The map is authored ahead of time and retrieved whole, never generated. It takes no side. It only caught that a choice was made without examination, and it stays generic so the agent fills in its own situation.
The part I care most about is the neutrality law. Neither end of an axis can sound like the better answer, erring toward either has to be a real mistake, and the question names the two ends by relation, not position, so order doesn't tip the scale. Without that the agent picks the pole that sounds more virtuous instead of the one that fits, and the whole thing collapses on tone. The exact failure it was built to prevent.
more about https://t.co/OHFWzVR0IU and its work.
reasoning harness rest & mcp
https://t.co/GR4mmQskGh
first open-source, keyless and free mcp and rest server :
https://t.co/pFfJCJMbI9