Hypothesis:
Debugging infra outages with AI every time might slowly make you a weaker engineer.
You won’t notice it in a week or a month. But one day, when AI is unavailable or wrong, you may feel strangely paralysed debugging something you could’ve reasoned through earlier.
Hypothesis:
Debugging infra outages with AI every time might slowly make you a weaker engineer.
You won’t notice it in a week or a month. But one day, when AI is unavailable or wrong, you may feel strangely paralysed debugging something you could’ve reasoned through earlier.
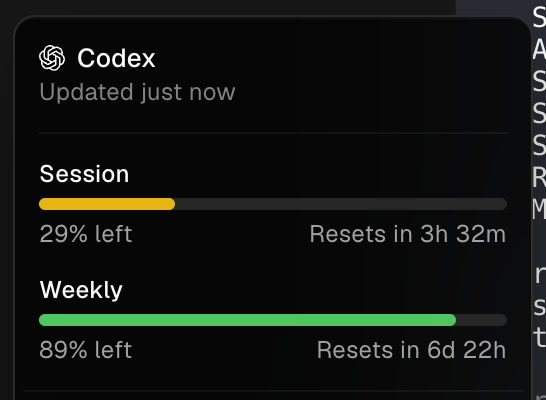
The Codex usage limits have been reset for all paid ChatGPT subscriptions. You should be back to 100% weekly and 100% hourly limits.
Let the tokens do incredible things today and have fun.
- used codex
- it created whatever i wanted
- rage baited claude code that codex created something better than you
- claude code refined it and created something better
- rage baited codex …………….
We all build horizontally scalable systems, but scaling is not as simple as saying "just add more machines" or "I will configure an autoscaling group". The challenge comes when we design systems that continue to behave predictably as traffic and load increase.
Here are some common things you will run into and the pointers that will help you when you are building systems that scale horizontally:
1. Cache everything that can tolerate stale reads
2. Handle noisy neighbors with CPU/memory limits
3. Keep services stateless - scaling becomes easy
4. Databases do not scale easily - know your limits
5. Know your data access patterns before partitioning
6. Queue asynchronous work to absorb traffic spikes
7. Design for failure - retries, timeouts, fallbacks
8. Eliminate single points of failure
9. Make operations idempotent - handle retries safely
10. Understand consistency tradeoffs early
11. Invest in observability - metrics, logs, and tracing
12. Avoid distributed transactions where possible
13. Rate limit critical services and APIs
14. Scale reads and writes differently
15. Capacity planning still matters despite autoscaling
By no means is this exhaustive, but these are some of the most common considerations that tend to surface as systems grow.
Hope this helps.
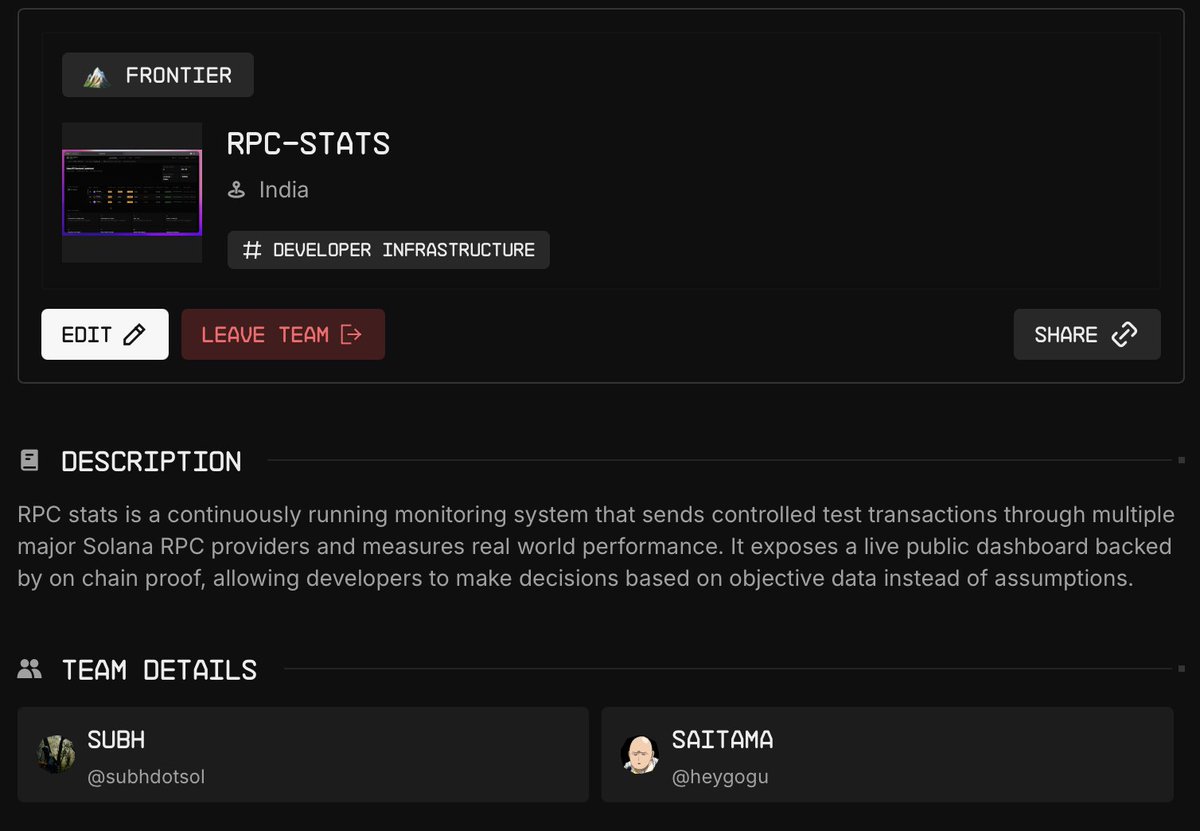
just submitted rpc-stats to @colosseum Frontier.
the idea is simple: every RPC provider claims they're the best at landing transactions. none of them can prove it.
so we built a system that tests helius, triton, and alchemy every 30 seconds. on-chain verified via geyser. live public leaderboard.
no marketing. just data.
built with @Subhdotsol 🤝
Bruh, Why do we need observability ???
we don’t.
Just have humble customers who’ll call you every time your app breaks, debug production for free, and even tell you which API is down 💀