Kled v2 is here. This one took some long nights and hard calls, but we got it right. Huge shoutout to the team for pushing through. Go try it!
https://t.co/PjJUUNeci9
Kled-FD processes every modality through a unified scoring system and rejects fraud at an unprecedented scale, surpassing the capabilities of any human-in-the-loop process.
The challenge wasn’t in individual capabilities, but in the layer that facilitates their agreement.
Clean data remains the bottleneck for the next decade of AI, and we have successfully built the filter to address this issue.
Introducing Kled-FD 0.1, the world's best fraud detection and dataset cleaning pipeline.
The first all in one system capable of detecting AI generated content, near duplicates, stolen and plagiarized media, screenshots, manipulated and spliced content, NSFW and explicit material, minors and age sensitive content, sensitive and harmful content, and coordinated behavioral fraud rings.
Kled-FD 0.1 has been battle tested across 1.2 billion uploads on Kled's data marketplace and is actively running quality checks on over 5 million uploads per day across image, video, audio, and text.
Public benchmarks will be released soon. This is the first real step toward making data quality enforcement a humanless process.
Did 15 mins of digging in https://t.co/aJwzXEtho0's frontend. here's what i actually found.. copy/paste reproducible: (I’m confident they might take this stuff down after the post hence the video)
1/ counter on the page says ~606,000 contributors. their own shipped bundle has a fixed: meta:{total:71e3, distinct_countries:74, source:"user_profiles + waitlist (country_code only)"}
that's 71,000. their own data disagrees with their own counter by ~535k.
2/ same file hardcodes 86 per-country counts (IN:7876, JP:5025, ZA:4621, KE:4544, GB:4112, US-CA:2375…). they sum to 74,675. the source field literally calls it a snapshot of “waitlist users”
not a live aggregate. a static export shipped to the client.
3/ the "live" heatmap is fabricated client-side:
Each dot = cityCoord + (Math.random()-0.5)*0.5
that's ±0.25° (~±25 km) of RNG jitter on a hardcoded city-coordinate table, regenerated fresh every page load. a second Math.random() seeds the WebGL shader dither.
the "alive" feeling is pure animation. nothing is being fetched live.
4/ now the contributor counter itself. here's the actual display function from their bundle:
function n(e){let t=Math.max(5e5,1e5*Math.floor(e/1e5));return `${Math.round(t/1e3)}K+`}
let o=n(5e5);
Math.max(5e5, …) = hardcoded floor at "500K+". the widget cannot render below that no matter what value the backend returns.
5/ reproduce it yourself in 60 seconds:
https://t.co/0SpI3MJwng
search for: Math.max(5e5,1e5*Math.floor or meta:{total:71e3 or distinct_countries
6/ what this proves from the client side:
their embedded user total (71k) contradicts their displayed counter (~606k)
the heatmap is fabricated with RNG, not live activity
the counter widget has a 500K+ floor baked into the code
7/ok but the api endpoint returning the ~606k number ,surely THAT’s a real database read?
no. it’s a function of unix time:
count ≈ floor(constant + 0.07048 × current_unix_seconds)
i forecast the value 2 minutes into the future. landed within 2 of the actual returned number out of ~606,000. that’s 0.0003% error. statistically impossible from real signups..real user activity has variance, clocks don’t.
responses come back with x-vercel-cache: HIT, frozen in 30-second cache windows. they’re not even hitting a database. it’s a cached time function served from edge.
the “live counter” is a clock multiplied by a growth rate (~0.07/sec = ~6,089/day baked in). not a counter.
8/ what’s provable from the client side, no backend access needed:
their embedded user total (71k) contradicts their displayed counter (~606k)
the heatmap is RNG on top of a hardcoded city table, not live activity
the counter widget has a 500K+ floor baked in
the api endpoint is a deterministic time function, served from edge cache
four independent layers of “fabrication”...
Did 15 mins of digging in https://t.co/aJwzXEtho0's frontend. here's what i actually found.. copy/paste reproducible: (I’m confident they might take this stuff down after the post hence the video)
1/ counter on the page says ~606,000 contributors. their own shipped bundle has a fixed: meta:{total:71e3, distinct_countries:74, source:"user_profiles + waitlist (country_code only)"}
that's 71,000. their own data disagrees with their own counter by ~535k.
2/ same file hardcodes 86 per-country counts (IN:7876, JP:5025, ZA:4621, KE:4544, GB:4112, US-CA:2375…). they sum to 74,675. the source field literally calls it a snapshot of “waitlist users”
not a live aggregate. a static export shipped to the client.
3/ the "live" heatmap is fabricated client-side:
Each dot = cityCoord + (Math.random()-0.5)*0.5
that's ±0.25° (~±25 km) of RNG jitter on a hardcoded city-coordinate table, regenerated fresh every page load. a second Math.random() seeds the WebGL shader dither.
the "alive" feeling is pure animation. nothing is being fetched live.
4/ now the contributor counter itself. here's the actual display function from their bundle:
function n(e){let t=Math.max(5e5,1e5*Math.floor(e/1e5));return `${Math.round(t/1e3)}K+`}
let o=n(5e5);
Math.max(5e5, …) = hardcoded floor at "500K+". the widget cannot render below that no matter what value the backend returns.
5/ reproduce it yourself in 60 seconds:
https://t.co/0SpI3MJwng
search for: Math.max(5e5,1e5*Math.floor or meta:{total:71e3 or distinct_countries
6/ what this proves from the client side:
their embedded user total (71k) contradicts their displayed counter (~606k)
the heatmap is fabricated with RNG, not live activity
the counter widget has a 500K+ floor baked into the code
7/ok but the api endpoint returning the ~606k number ,surely THAT’s a real database read?
no. it’s a function of unix time:
count ≈ floor(constant + 0.07048 × current_unix_seconds)
i forecast the value 2 minutes into the future. landed within 2 of the actual returned number out of ~606,000. that’s 0.0003% error. statistically impossible from real signups..real user activity has variance, clocks don’t.
responses come back with x-vercel-cache: HIT, frozen in 30-second cache windows. they’re not even hitting a database. it’s a cached time function served from edge.
the “live counter” is a clock multiplied by a growth rate (~0.07/sec = ~6,089/day baked in). not a counter.
8/ what’s provable from the client side, no backend access needed:
their embedded user total (71k) contradicts their displayed counter (~606k)
the heatmap is RNG on top of a hardcoded city table, not live activity
the counter widget has a 500K+ floor baked in
the api endpoint is a deterministic time function, served from edge cache
four independent layers of “fabrication”...
I just found out that Luel AI, the company that completely copied my company Kled's entire website, is misrepresenting their compliance practices, using Delve to outsource it, fabricating their website user numbers, and pulling in massive amounts of fraud data from exclusively fraud oriented regions.
Skip to 1:15 if you want to skip context.
You truly cannot make this up. This is egregious, disgusting behavior from everyone involved.
This is people's data. It cannot be taken lightly. The only way a company like this can truly succeed is by investing the time and resources to commit 100% to the trust and compliance of their users' data. Luel AI is doing the exact opposite. Disgusting behavior for a company trusted with people's data.
LazarBeam has just invested into Kled.
23 million subscribers, one of the biggest YouTubers of all time, and someone I personally watched relentlessly growing up.
Welcome to the cap table Lannan. He will be joining, Diplo, PandaBoi, 24kGolden, and all the other creatives who have angel invested in Kled. Proud to have you join us.
Why We Ship: @useKled
Pokémon Go players generated 30 billion images and videos that Niantic used, and never saw a cent for it. @avipat_ built Kled so the people generating the data get rewarded.
50,000 DMs and three and a half years later, it's the largest human-powered data collection effort in history, distributing rewards on Solana.
@useKled AI companies are paying out $50 billion per year for data collection, making it one of the fastest growing job sectors. Kled is the first of many apps that will enable this.
https://t.co/0RMNxNS8BU
AI data collection companies like Kled are paying up to $10,000/month for U.S.-based college students and graduates. No CS degree required.
This quarter, we're doubling down on U.S. opportunities by slowly introducing over $30,000,000 in task rewards for qualified, KYC'd users.
Tasks are built around everyday human activity: upload 500 selfies for $1,000, record a quick video of yourself taking out the trash for $5, or upload your tax return for $150.
All data advances leading AI models, with full consent, anonymization, and fair compensation. Download Kled on the App Store and join the fastest-growing gig economy.
We have conquered Asia. Over the last few days Kled has hit #1 on the App store finance charts in Malaysia, Indonesia, and Philippines.
We've run a risk analysis on over 400 million data uploads from these regions, and have found these to be some of our highest quality unloaders.
Thank you to all our users out there, and keep uploading great content. We've tripled our payouts for the next 1 week in celebration.
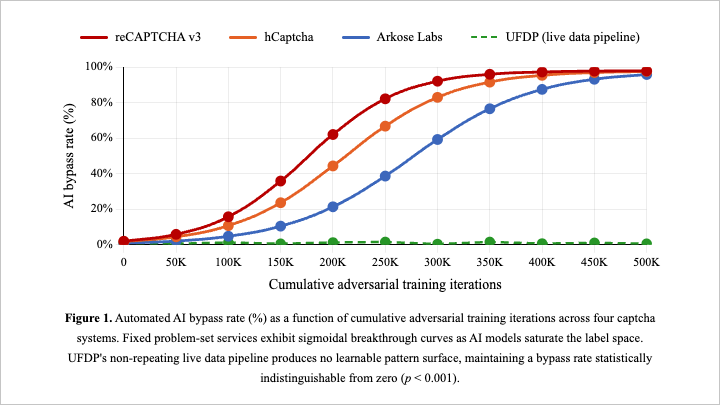
Traditional captchas are becoming worthless.
AI can now solve any fixed image grid automatically. reCAPTCHA, hCaptcha, every major service on the market pulls from a pre-labeled problem set. Once AI learns the set, it is over.
UFDP has all the same standard bot detection built in. But the captcha itself is unsolvable by AI because it is never the same twice.
Every question is a brand new real world data point pulled live from a pipeline of 5 million daily uploads. There is no problem set to train on. There is no pattern to crack. The only thing that can answer it is a genuine human judgment call.
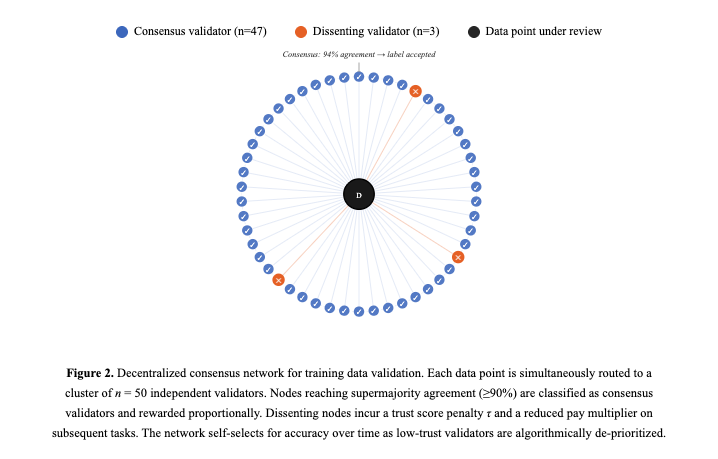
Consensus is everything.
Each question goes to a cluster of at minimum 50 people simultaneously. If 47 say the answer is X and 3 say Y, it is X. The 47 get rewarded. The 3 take a trust score hit, their pay multiplier drops, and they get flagged for closer review.
The network self selects for quality over time. The best validators earn the most. The bad actors get priced out automatically.
Every AI lab in the world has the same problem.
Billions of data points with no clean way to validate them at scale. Bad data in a training pipeline destroys model quality.
Quality control is the single most expensive bottleneck in AI development.
The first human data marketplace has just crossed over 1 billion uploads.
Tens of thousands of structured and labeled datasets across all human activity.
We are on track to do over 5 billion uploads this year, officially cementing our place as the largest opt in human data collection effort in history.
This belongs to every person who chose to own their data. Thank you.
Download Kled on the app store today.
the kled app has been fully gamified.
we’re introducing the level system.
the higher your level the better tasks and pay you have access to.
earn xp through achievements, daily upload streaks, converting your kled balance, and more.
we’ve made the app more engaging than ever.
this will be the biggest update we've ever done.