@VLucet @KCazelles Maybe @ucfagls would have thoughts on this too. Gavin, how would you typically list packages in the CCV?
Or is bringing up the CCV too traumatic now that you don't have to do them anymore? 😅
@VLucet @KCazelles I would list it under "Knowledge and Technology Translation". However, I don't know if that shows up for every CCV version (different agencies allow for different categories)
@ASeatonSpatial @VLucet Sorry to hear we won't get to chat in person, but it would be great to chat over Zoom some point about this. Let's touch base again in August
@VLucet @ASeatonSpatial Actually, @ASeatonSpatial, are you at ISEC next week? I don't think we've met in person, but it'd be great to meet up to chat about this paper. It'll give me a good excuse to go through it in depth on the plane ride :)
The CSEE Meetings account is evolving! 😂🤣😅
Thank you to the outstanding #CSEE2024#Vancouver#dreamteam led by @gerlame 👏👏
We 👀 forward to seeing you in #Sherbrooke July 6-9th, 2025, for a meeting co-chaired by Fanie Pelletier & @festa_bianchet
https://t.co/vR3YLJL0wy
🎆I am beyond thrilled to announce that I will be joining @Concordia Biology department as an Associate Professor in the Fall 2024! My Computational Genomics lab will use multi-omics to understand environmental and genetic contributions to human health. 🧬🧑💻
@karlrohe Intuitively, I think you should be able to recover the first n moments of f(p), but I have to think about how to prove that more carefully
my current thought process: "something-something moment generating function?"
@camjpatrick@IsabellaGhement@stephenjwild@ucfagls Quadratic penalization in glmms are directly interpretable as using a MVN prior on coefficients, and if you estimate penalties via restricted ML it can be interpreted as using an empirical Bayes model
@IsabellaGhement@stephenjwild@ucfagls Also, it's important to note that the goal of stats in science is not to win a philosophical debate, but to build rigorous tools for testing scientific ideas. Since neither approach is going away anytime soon, knowing when results are comparable across traditions is useful
@IsabellaGhement@stephenjwild@ucfagls For example, I would say that Bayesian cross validation would have been much slower to develop purely from a Bayesian philosophical viewpoint, and modern frequentist hierarchical models / penalized regression has benefited immensely from the Bayesian viewpoint on these models
@stephenjwild@ucfagls I would second this one; I've been reading through it and it does a really nice job of threading the needle of "enough theory to get students started, enough practical advice to be useful".
I also like Simon Woods's Core Statistics for the same reason
@carlislerainey@stephenjwild Changing from `s(x, bs="tp", m = 2)` [penalty on the 2nd squared derivative] to `s(x, bs="tp", m =1)` [penalty on 1st sqrd deriv] represents a bigger change in assumptions: penalizing 1st derivatives generally results in more "wiggly" looking curves than 2nd derivatives
@carlislerainey@stephenjwild One important point though: smoothers with different names (e.g. bs="cr" and bs ="tp") can end up with practically very similar estimated curves if they make the same assumptions about how the curve should be penalized: by default, both "cr" and "tp" penalize (dy/dx)^2
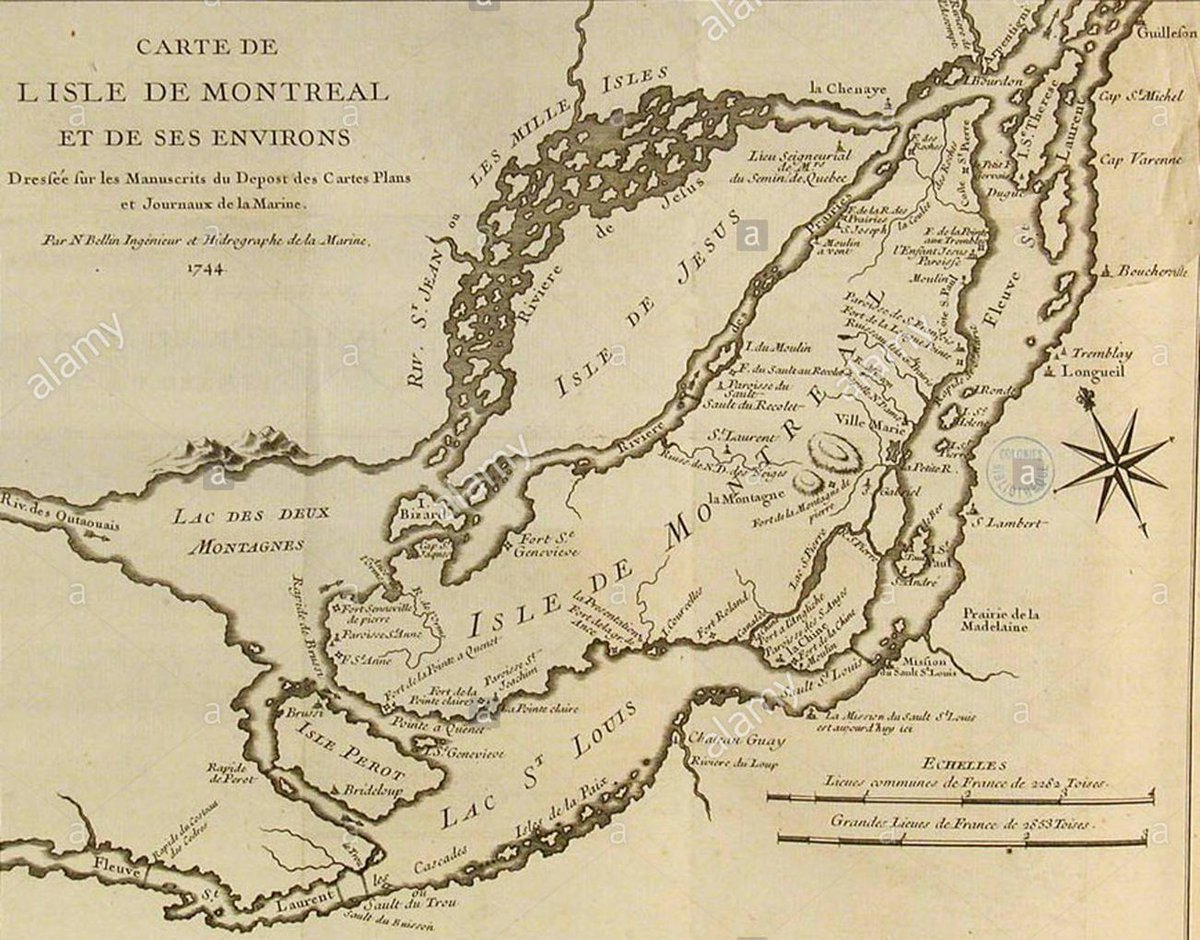
An 18th century map of the Island of Montréal, revealing where several small rivers once ran freely - before they were canalized or buried as underground sewer lines.