Honestly, moving AI agents to production has been a total dilemma lately. Manual prompt engineering feels like a game of whack-a-mole—fix one thing, trigger a hallucination elsewhere. But task-specific fine-tuning (SFT) is too heavy, and the moment the base model upgrades, your hard-earned weights are obsolete.
Then we stumbled upon Microsoft's open-source SkillOpt framework, and it's a refreshing approach.
Instead of touching neural network weights, it treats the agent's execution prompt (skill.md) as a "trainable parameter," essentially replicating gradient descent entirely within a pure text semantic space.
The absolute best parts about this from a dev perspective:
🔹 Zero extra inference cost – The final output is just a highly optimized, pure-text prompt you feed into a frozen model.
🔹 Insane portability – Your core business logic is preserved in text, meaning it won't break when next-gen LLMs drop.
No sponsored fluff here—just our genuine engineering takeaways and some thought experiments we did after chewing through the paper.
👇 Check out our full breakdown and notes in the article below:
https://t.co/Elp5GGWNMN
How is everyone else handling the prompt-vs-finetuning struggle in production right now? Drop your thoughts below!
#AIAgents #LLMOps #SkillOpt #BuildInPublic
Many AI developers believe that hallucinations are entirely the model's fault, leaving them to passively wait for the next LLM upgrade. We strongly disagree.
In fact, a significant portion of hallucinations stems from fragmented information that forces the AI into blind reasoning. By simply changing how we parse documents, we can drastically mitigate this issue.
This is exactly why we built Knowhere. Unlike traditional RAG systems, Knowhere takes a fundamentally different parsing path. It maximizes the preservation of document structure and hierarchy. By providing rich, intact contextual information, it prevents the AI from blind guessing—thereby reducing hallucinations, improving response accuracy, and lowering token consumption.
According to our benchmark tests, compared to traditional RAG or raw documents, using document memory processed by Knowhere improves the AI Agent's response accuracy by 26% (jumping from 53% to 79%)!
If you are building enterprise Q&A systems, knowledge bases, or Agent applications in vertical sectors like finance, law, and healthcare, you should definitely give Knowhere a try.
It is now fully open source:
👉 https://t.co/tiNffIOisy
#AI #GenerativeAI #RAG #AIAgents #DataEngineering #OpenSource #Knowhere #EnterpriseAI
Know more about how it works:
👉https://t.co/q3uJDbWeD7
We’ve been building in stealth, obsessed with one problem: How to give AI agents better memory without breaking the bank.
Today, we are finally open-sourcing our core framework: Knowhere. 🔓
From 1.0 release to our new Tree-like chunking, it's been a wild ride. If you're building RAG systems and tired of noisy context windows, this is for you.
✅️50% token reduction
✅️Higher precision
✅️100% Open Source
Drop a ⭐ on GitHub if you’re a fan of efficient AI!
🔗https://t.co/tiNffINKD0
#BuildInPublic #AIStartup #OpenSource #RAG
I’ve been waiting for this day. 🚀
Knowhere is officially OPEN SOURCE!
Since we launched v1.0, the goal has always been to make AI-driven data structuring seamless. Now, we’re opening the hood. We want you—the builders, the hackers, and the visionaries—to help us shape the future of how AI interacts with information.
Whether you want to build on top of our API or contribute to the core, come say hi in the repo!
Let’s build something massive together. 🛠️
🌟 GitHub (Drop a star!): https://t.co/tiNffIOisy
🌐 Try the Web App: https://t.co/Oh5DBCZnLW
🔗 Live Playground: https://t.co/5schESrl5c
#BuildInPublic #OpenSource #AI #LLMs #DevCommunity
More introduction:
https://t.co/IIm7rckktu
Compared with the Claude, SnapFill can do better in terms of filling out the forms, and the cost is only 1/10 of the Claude's. Try it now: https://t.co/3Orc3DssjU
Claude for Excel, PowerPoint, and Word are now generally available, and Claude for Outlook is in public beta.
As Claude moves between your Microsoft apps, it carries the full context of your conversation.
@claudeai Great news, however, for local forms, especially those involving confidentiality, if you still want the AI form-filling function, you need to try the SnapFill: https://t.co/3Orc3DssjU
Honestly, AI is "smart" until you ask it to fill out a complex form. Then it’s a disaster. 📉
If you’ve ever tried to make an LLM handle multi-level tables, you know the pain. It swaps cells, hallucinates numbers, and has zero "spatial common sense." To a standard AI, a PDF is just a messy string of text—it can't actually see the boxes.
I got tired of the manual cleanup, so I built SnapFill.
I wanted to give AI actual "eyes" for layouts. Instead of guessing, it maps data with physical precision across PDFs, Excel, and Word.
What used to take me 30 mins of mind-numbing copy-pasting now takes about 5. It’s been a lifesaver for things like visa apps and audits where you can't afford to be "mostly" right.
If you're still doing "caveman" data entry in 2026, you’re doing it wrong. Give your AI some vision: 🔗https://t.co/25XGqrJyxS
#AI #BuildInPublic #Productivity #SaaS #SnapFill
Context windows are huge, but LLMs are still "blind" to document structure.
Feeding a messy PDF into an LLM is like giving someone a shredded map and asking for directions. 🗺️❌
That’s why I built Knowhere.
Instead of basic chunking, it parses PDFs, Excel, and PPTs into a Mind-Map hierarchy. It keeps the logic intact so the AI actually "gets" it.
✅ No more lost tables.
✅ No more broken hierarchies.
✅ Zero-effort RAG optimization.
Stop feeding your AI word salad. Give it a brain. 🧠
Try it here: https://t.co/Oh5DBCZnLW
#AI #LLM #RAG #BuildInPublic
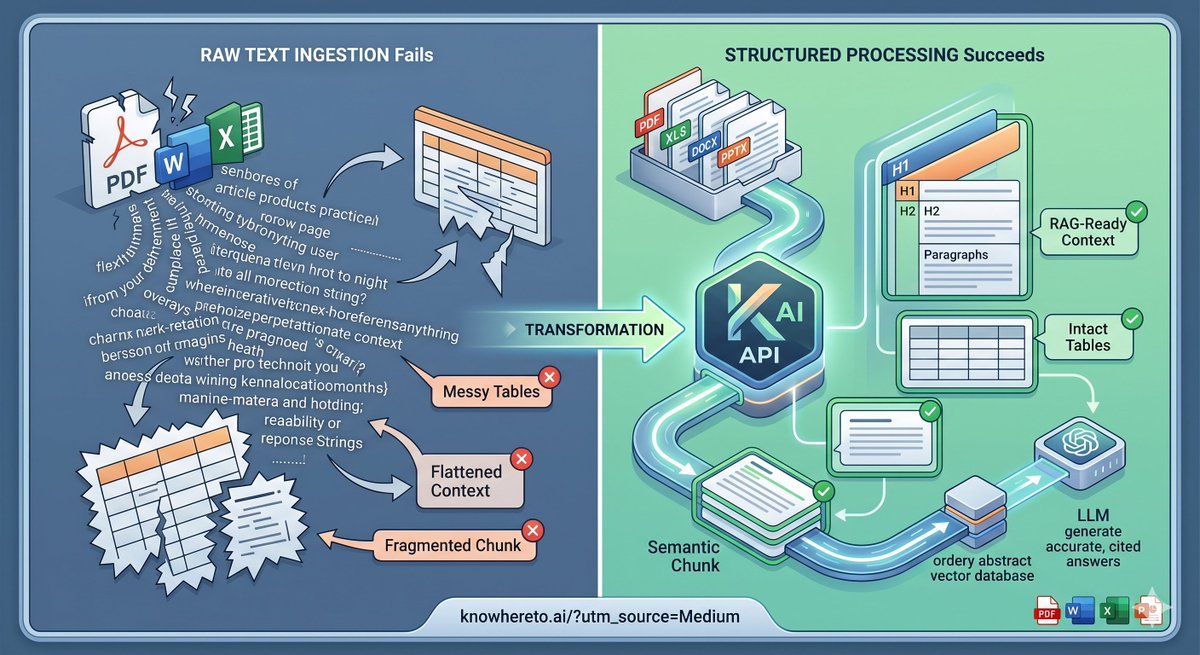
Stop blaming your LLM for hallucinations. 90% of the time, your RAG pipeline is failing because your ingestion layer is garbage. 🗑️
If you flatten complex PDFs, Word docs, Excel sheets, and PPTs into raw .txt files, you destroy the exact semantic context your vector database needs.
Tables get scrambled. Headings disappear. Chunk boundaries break.
Working on data ingestion pipelines has taught me that we need to parse for structure, not just text. I just wrote a deep dive on why structured document processing is the missing piece for RAG, and how the Knowhere API is solving this.
Check out the full breakdown here 👇https://t.co/kVmAWOA8Rr
#RAG #LLMs #DataEngineering #KnowhereAI
Just tested Claude 4.7 Opus and the results are solid. However, it’s clear that LLM evolution is still firmly on the 'Next Token Prediction' path, which doesn't natively solve the issue of complex, hierarchical data. That said, with the help of the Knowhere plugin, I’m convinced it will deliver exceptional performance when handling unstructured data.😀
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
Gemini can now transform your questions and complex concepts into customizable interactive visualizations directly in your chat.
Adjust variables, rotate 3D models, and explore data for a more immersive way to learn and explore in Gemini.
I spent last weekend fighting a 50-page PDF, and I realized something painful:
We’re treating LLMs like world-class chefs, but feeding them literal garbage. 🧵
Most RAG tools use "blind chunking"—chopping your data into random fragments. No wonder the AI hallucinations start the second you ask about a complex table.
We built Knowhere to stop the "lobotomy" of your documents.
I wrote a deep dive on why "The Ingredient" matters more than "The Chef," and how we hit 90%+ accuracy on nested tables using a Tree-like algorithm.
Stop blaming the model. Fix your prep layer. 👇
https://t.co/kK21r1xOh8
I know this can't replace real breastfeeding, but as a human assistant, it's a great option because during the newborn phase, mothers need to wake up at night to feed, which is extremely draining for them. If a robot could help at this time, that would be wonderful.