🚀 Launching Every Eval Ever: Toward a Common Language for AI Eval Reporting 🚀
A shared schema + crowdsourced repository so we can finally compare evals across frameworks and stop rerunning everything from scratch 🔧
A tale of broken AI evals 🧵👇
https://t.co/UOcxiMwKOL
@icmlconf At EvalEval, we’re working toward more reliable, informative, and sustainable AI evaluation practices. Interested in helping shape the future of AI evaluation?
Learn more about EvalEval: https://t.co/7eyTLMpo8I
⚠️ Key Takeaways:
- Nearly half of the benchmarks we studied show high or very high saturation, meaning they struggle to distinguish between models.
- Contrary to common assumptions, private test sets do not appear to prevent saturation once benchmarks become widely adopted.
- Studied 60 widely-used LLM benchmarks spanning reasoning, knowledge, coding, multilingual evaluation, and more,
- Annotated benchmarks across 14 properties (e.g., age, accessibility, language) to study how benchmark design relates to long-term resilience against saturation.
🚨 As AI models improve, many benchmarks are becoming saturated and losing their ability to distinguish between models. 🚨
Check out our new @icmlconf paper: “When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation”
🎯 We aim to understand which benchmarks are saturating, why it happens, and what makes some benchmarks remain useful longer than others.
- We introduced a new uncertainty-aware saturation index that measures when top-performing models become statistically indistinguishable,
Amazing effort by all the authors, working chairs and coalition members! If you're going to be at ICML, come say Hi! Stay tuned for updates on ICML socials 👋
🚀EvalEval is 2/2 accepted at @icmlconf 2026 🚀
1⃣ Who Evaluates AI's Social Impact? Mapping Coverage and Gaps in First and Third Party Evaluations
2⃣ When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Details below 🧵
Working groups led by @evijit, @AnkaReuel, @akhtarmubashara and Jenny Chim!
Preprints:
Social Impacts -> https://t.co/immzuJGQpe
Benchmark Saturation -> https://t.co/HSmu33Pgjq
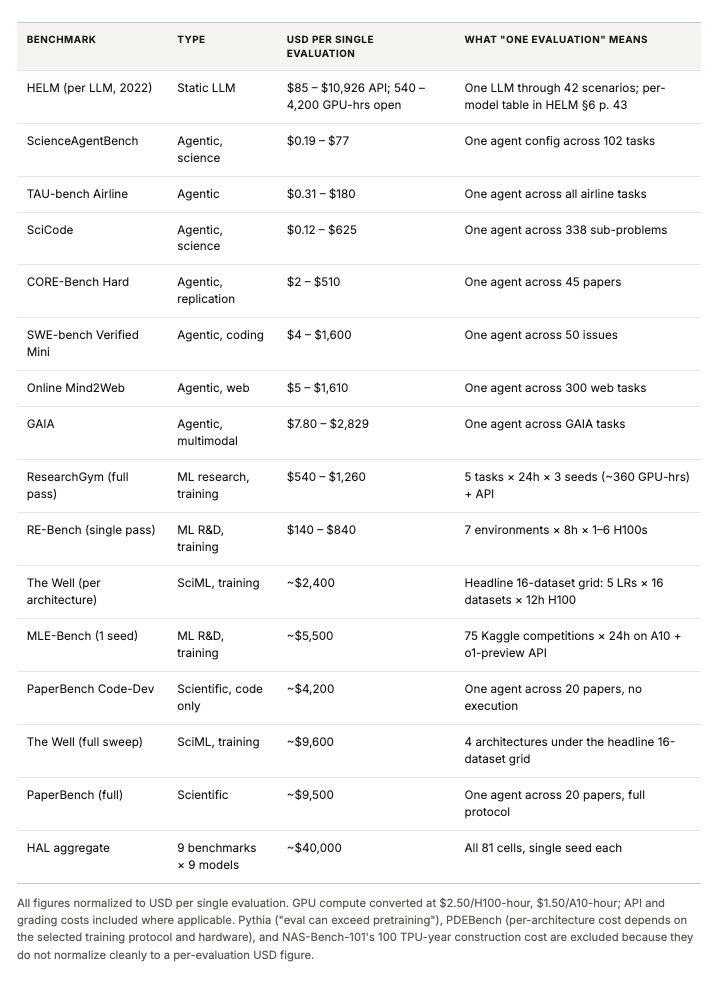
AI evaluation is becoming its own compute bottleneck.
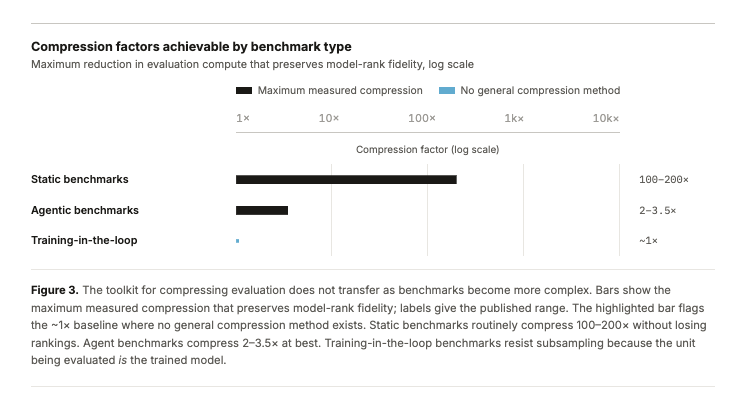
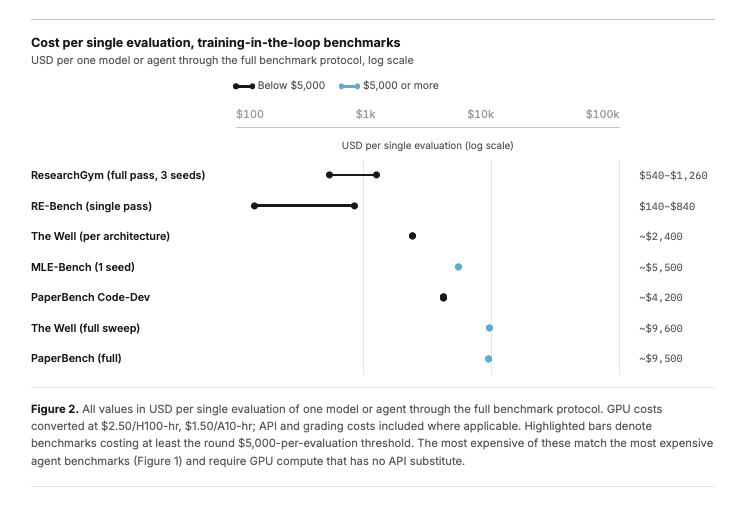
We often talk about the cost of training frontier models, but the cost of evaluating them is starting to matter just as much, especially for agents, scientific ML systems, and training-in-the-loop benchmarks.
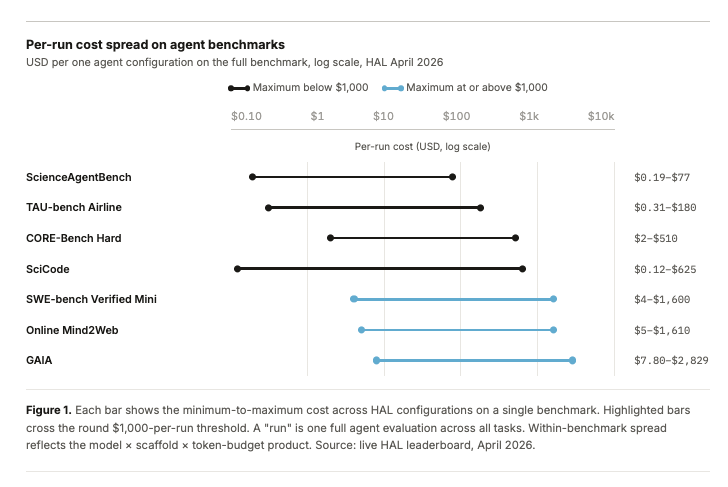
In our new Evaluating Evaluations post, we look at how evals are crossing a threshold where cost changes who can participate. The Holistic Agent Leaderboard spent about $40K on 21,730 agent rollouts across 9 models and 9 benchmarks. A single GAIA run on a frontier model can cost $2,829 before caching. And once you care about reliability, repeated runs can multiply these costs many times over.
This creates a real accountability problem. If only large labs can afford statistically credible evals, independent researchers, auditors, journalists, and public-interest organizations are left with partial visibility into frontier systems.
The core issue is that benchmark design is changing. Static benchmarks could often be compressed aggressively while preserving rankings. Agent benchmarks are noisier and scaffold-sensitive. Training-in-the-loop benchmarks are expensive by construction. As evals move closer to real work, they also become harder to make cheap.
Some takeaways:
→ Leaderboards should report cost alongside accuracy.
→ Reliability should not be treated as optional.
→ We need reusable eval artifacts! Shared documentation formats, such as Every Eval Ever, can help the field stop paying repeatedly for the same measurements.
Read the full post: https://t.co/sArlZMkytF
Thanks for the insights @LChoshen , Yifan Mai, and @cgeorgiaw🤗
3 days left!
📷 Writing, wrote, or just submitted a paper?
Commit it to the EvalEval workshop at ACL 2026 in San Diego!
https://t.co/JRSr50UA8y
(including ARR Submissions, non-archival, positions, and extended abstracts!)
Submission Deadline: March 19th, 2026 AoE
⏳ 9 more days! We extended the submission deadline for the EvalEval Workshop @ ACL 2026.
If your work touches AI evaluation, submit!
We welcome:
✅ Regular papers
✅ ARR submissions
✅ Non-archival work
✅ Position papers
✅ Extended abstracts
📅 Deadline: March 19
(1/2)
Sitting on results from papers or leaderboards? Whether you use lm-eval, Inspect AI, or HELM, we have low-lift converters ready to go. 🦾
💾 GitHub: https://t.co/CydLGwhVGb
📜 Co-authorship on the shared task paper for qualifying contributors
📅 Deadline: May 1, 2026
🧪 Your LLM evaluation results could help the whole field 🚀 🧑🔬
Our ACL Shared task is out!
We’re building a unified, crowdsourced database to create a common language for AI evaluation reporting. And we need your data. (1/2)
https://t.co/SQhEVsqEWg
🚀 Launching Every Eval Ever: Toward a Common Language for AI Eval Reporting 🚀
A shared schema + crowdsourced repository so we can finally compare evals across frameworks and stop rerunning everything from scratch 🔧
A tale of broken AI evals 🧵👇
https://t.co/UOcxiMwKOL