👉 Building https://t.co/PEdeJRnby5™.ai and https://t.co/pi5AgZ8WI9 forced a question I couldn't answer cleanly: 🤷 where does my work fit in the AI stack?
I re-read two papers that helped me draw the map.
1️⃣ Harness-1 (UIUC, Berkeley, Chroma): A 20B model matches frontier searchers because the harness around it – not the model – handles state, curation, verification, and context budget.
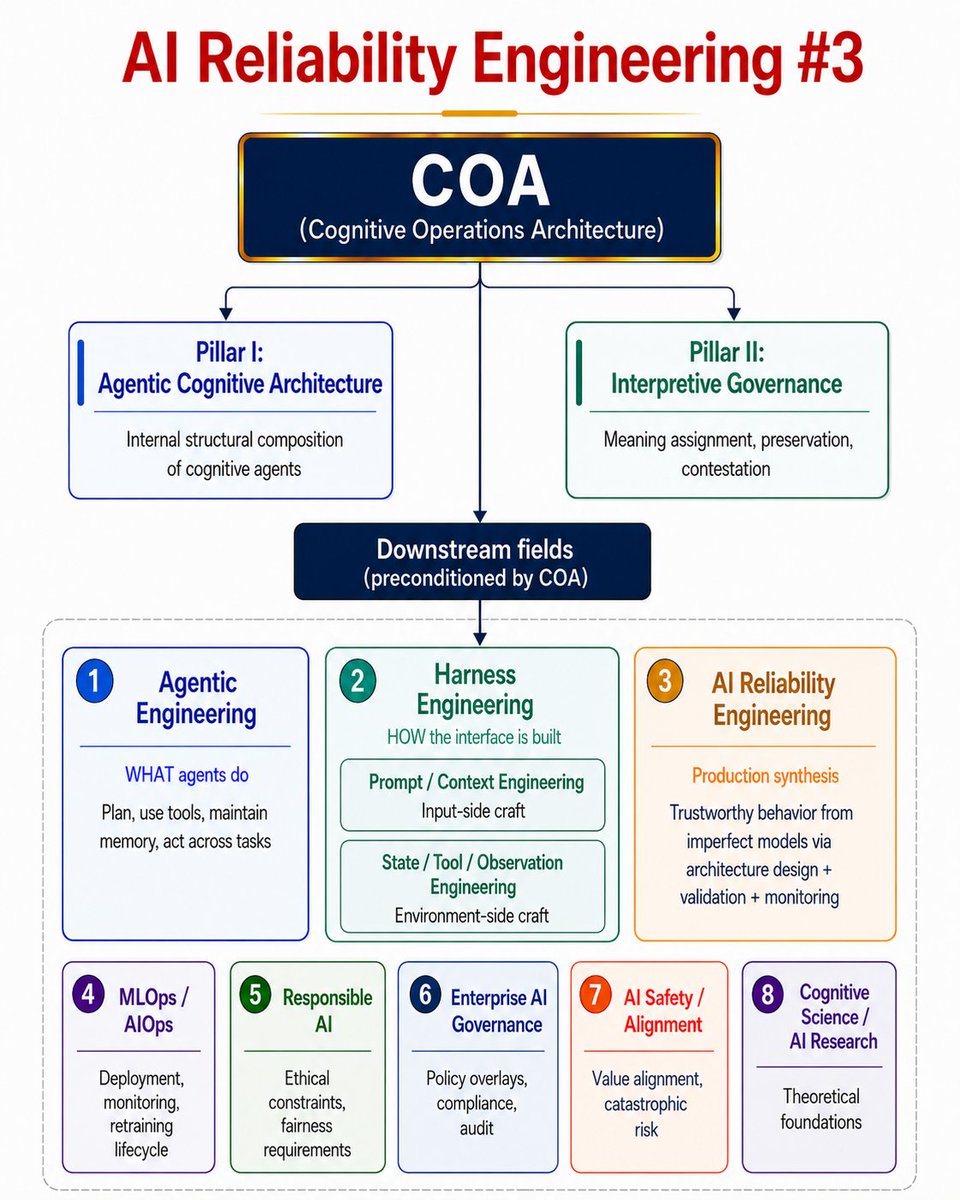
2️⃣ COA (George Williams): A proposed upstream discipline arguing that every AI failure traces to missing architecture governing meaning, validation, and execution authority – before any model runs.
Both arrive at the same conclusion: the system around the model matters more than the model.
🧐 But the terminology landscape is a mess. Agentic engineering, harness engineering, reliability engineering, MLOps, governance – everyone claims the center. Here's how they actually layer:
🔹COA is the precondition – the "must be true" before engineering begins
🔹Agentic Engineering is what agents do – plan, tool-use, act
🔹Harness Engineering is how the interface works – including prompt craft and state management
🔹AI Reliability Engineering is the production synthesis – getting trustworthy behavior from imperfect models by designing around them well
The controversy over whether this is governance or engineering misses the point. It's both.
🔸COA specifies what must be governed.
🔸Harness Engineering implements how.
🔸Reliability Engineering ships it.
📗 The papers:
Harness-1: arXiv 2606.02373
COA: Foundational Publication v1.0, George E. Williams
Anything missing from this map?
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
🙋 First look: https://t.co/pi5AgZ8WI9's Context Artifact Audit is live.💥This is worth celebrating, and the dev story earns a victory lap.
This week we took the first user-facing view of our AI reliability audit engine from zero to live — and the last stretch handed us a good one:
👏 A subtle Server Component serialization bug that only showed its face in production. Tracked it down, fixed it, shipped it.
What's live now: a reliability report that surfaces real conflicts with their sources, marks what it hasn't checked instead of faking a pass, and hands evidence to a human instead of a verdict.
▶️ Most AI tools sound just as confident when they're wrong as when they're right.
🧐 We're building the opposite — a reliability layer that checks the evidence and provenance behind AI-generated work, and shows its work.
🤷 What I like about this first screen (see link to access the audit engine reliability report below)
🔸It flags real conflicts between sources, and points every finding back to a quoted source.
🔸It states plainly what it did NOT check. "Not assessed" is never dressed up as a pass.
🔸It's evidence for a human to weigh, not a black-box verdict.
See it: https://t.co/oFH0YKiNSR
More soon. 👍
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
🙋 POST 1 of 2: What's my Job Title?! 💥 Claude Code & Codex as Supervisor, Engineer, Designer & Architect✍️ Extending https://t.co/PEdeJRnby5 ➞ https://t.co/pi5AgZ8WI9 · MVP v0.1 Launch
Across one v0.1 build, my "title" changed hourly:
→ Director: Set mission & guardrails (IP, air-gap, safety).
→ Product Manager: Made binding scope calls (ship vs. wait).
→ Reviewer / QA: Gated every slice before shipping.
→ Resource Allocator: Matched tasks to the right model.
→ Accountable Owner: Executed irreversible steps & signed merges.
→ Curator/Marketer: Storytelling, lean narrative, execution maindate as moat
I wrote no code. I owned every decision.
The Problem
AI systems produce work driving real decisions, but output rarely shows if it can be trusted. Are claims supported? Do documents contradict? Is evidence missing? Teams currently trust AI output by reputation, not evidence.
What We Built
The Context Artifact Audit is a reliability layer. Hand it related AI artifacts (e.g., source, summary, evaluation), and it returns a structured reliability assessment mapping every finding to its exact source:
▫️Where documents disagree.
▫️Where claims lack support.
▫️Where expected evidence is missing.
▫️Crucially: it returns evidence for human judgment, not a verdict. It surfaces what to look at; humans decide.
Three Cleanly Separated Layers:
1️⃣ HTTP Route (Thin Front Door): Authenticates, rate-limits, and validates. Zero AI logic; no model calls.
2️⃣ Audit Engine: Does the reliability work (deterministic checks, model-as-judge pass, evidence grounding, calibrated signals).
3️⃣ Model Adapter: The only component talking to an AI model—fully swappable.
The Enterprise Advantage:
🔸 BYOM / Air-Gapped: The swappable adapter means the engine runs against your model on your infrastructure. Sensitive artifacts never leave your environment.
🔸 Self-Hosted Deployment: Ships as a self-contained deployment behind your firewall.
🔸 Stateless & Simple: Holds no data between calls. Zero server-side retention.
🔸 Honest by Construction: If input lacks info to assess, it explicitly says so. No false clean bills of health.
🧐 This MVP is the first callable version of the audit engine, delivered as a JSON API. It is the foundation: no dashboards, no saved history, and high-stakes presets remain assistive, never an automated authority. The architecture is the durable part, built for speed-to-market and to carry the rest.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Testing Antigravity 2.0 Now: Quick Take - I've been working with Claude Code building https://t.co/PEdeJRnby5™. 💥Needed to see how the new Antigravity 2.0 stacks up against other coding agents. What's unique?
🔹Antigravity: agent command center for projects.
🔹Claude Code: strongest hands-on coding cockpit.
🔹Codex: coding agent with strong cloud/task/PR-review model.
🔹Claude Cowork: broader desktop/work assistant, less “repo engineer” focused.
✍️ The Real Difference
▫️Antigravity feels like Google is asking:
“Can one user supervise a small team of agents visually?”
▫️Claude Code asks:
“Can one developer move faster inside a repo?”
▫️Codex asks:
“Can coding tasks be delegated to local or cloud agents with reviewable diffs and PR integration?”
▫️ Claude Cowork asks:
“Can Claude handle broader work on my files/apps, not just code?”
🙋 So Antigravity’s unique value is not “better coding than Claude Code.” It seems it is whether its project + visual orchestration + scheduled local agents model teaches us something useful for OpenClaw/Hermes-style control planes.
▶️ AI coding tools are starting to converge on the same primitives:
- projects,
- subagents,
- worktrees,
- browser validation,
- scheduled tasks, and
- reviewable artifacts.
🤷 The question now shouldn't be “which tool can write code?”
Most of them can.
The better question is: what operating model does each tool encourage?
Antigravity looks less like a Claude Code replacement and more like an agent operations UI: a place to supervise multiple agents, projects, workflows, and scheduled tasks.
Claude Code remains strongest as a hands-on coding cockpit. Codex is compelling for delegated cloud tasks and reviewable diffs. Claude Cowork points toward broader desktop and knowledge-work delegation.
✍️ For AI product managers, engineers, and architects, the takeaway is simple:
Don’t evaluate these tools only by code quality. Evaluate them by:
🔸How they scope access to files and tools
🔸How they expose agent activity for review
🔸How they support parallel work without chaos
🔸How they handle approvals, artifacts, and rollback
🔸Whether their workflow fits your team’s actual operating model
----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 A Critical Lens: CORAL- High Autonomy inside a Tight Container/Scaffolding💥
Unlike many conceptual papers in this space, CORAL ships with runnable infrastructure: a Python-based agent runtime, CLI tooling, isolated git worktrees, shared persistent memory, and a web dashboard.
It gives practitioners something they can actually install & experiment with today
Its core architectural ideas are worth studying :
🔸A shared file-system-style memory (attempts / notes / skills) that enables asynchronous agents to collaborate without predefined roles or direct messaging
🔸Heartbeat mechanisms that inject structured reflection, consolidation & redirection
🔸Clear separation between agents and evaluators
🧐 Critical Lens:
"Full autonomy" claim is inflated
1. Figure 1 labels CORAL "Full autonomy." Overreach. True autonomy = meta-learning heartbeat rules, discovering memory taxonomies, questioning the evaluator. CORAL does none of this. Agents drive; humans built the road and traffic laws.
2. The scaffolding
▫️Memory: attempts/, notes/, skills/ imposed, not discovered
▫️Meta-control: Heartbeat triggers are hand-tuned hyperparameters
▫️Action space: Bash, fixed evaluator, skill templates — agents can't invent tools
▫️Cognitive priors: Prompts encode assumptions about thinking & memory
▫️Reward: Immutable evaluator. Agents optimize within a fixed objective
3. vs. Voyager / SWE-agent
Voyager/SWE-agent = broader tool-use autonomy, open-ended API discovery, debugging without predefined loops. CORAL = strategically autonomous (when to eval, what to remember) but operationally constrained (closed task/evaluator loop). Evolution engine vs. exploration engine. Narrower autonomy
4. Real-world gaps
🔹No evaluator: Unclear with human panels or multi-year experiments.
🔹Memory chaos: Async writes create non-deterministic state. No conflict resolution
🔹Cost blindspot: Reports eval counts, never token spend or API budget. Reflection loops burn context unpredictably
🔹Safety gap: Evaluator hacking mentioned but unaddressed. Misaligned agent + Bash access = liability
5. Solid Evaluation
Strong baselines (OpenEvolve, EvoX), right metrics, honest disentanglement. 20% kernel gain is real. Knowledge diffusion, not just parallel compute. Open-source replication is real.
6. Multi-agent gains: real but murky
66% records from cross-agent parents, but stochastic diversity vs. knowledge sharing not isolated. Works at 4 agents; at 20, filesystem becomes noisy without ranking/consensus
🙋 Upshot:
CORAL = high-autonomy evolution inside a scaffolded box. Pragmatic, not self-determining
Practitioners:
🔸PMs: Ready for optimization workflows with clear evaluators
🔸Architects: You still design evaluator, heartbeat rules, safety envelope
🔸Engineers: Filesystem memory needs DB, version control, conflict resolution before production
CORAL vs. Hermes / OpenClaw: https://t.co/XHDF2S3Hqe
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™: https://t.co/757iwppAXO
👉 Architectures of Autonomy💥1️⃣ CORAL vs. 2️⃣ Hermes Agent vs. 3️⃣ OpenClaw
1️⃣ CORAL — Autonomous multi-agent evolution system
CORAL is about how agents think, evolve, and coordinate.
🔸Agents generate attempts, reflect, consolidate skills.
🔸Multi-agent co-evolution drives exploration.
🔸Shared memory acts as a long-term knowledge base.
The goal is open-ended discovery and self-improvement.
CORAL is a behavioral and evolutionary framework.
✍️ In my next post I'll review the CORAL arxiv article & its associated tooling:
"CORAL: Towards Autonomous Multi-Agent Evolution"
-----
2️⃣ Hermes Agent (by Hexolab) — Agent harness / runtime
Hermes is about how agents are executed, not how they evolve.
🔸Provides a structured agent loop.
🔸Handles tools, retries, error recovery.
🔸Manages context, memory, and tool calls.
🔸Focuses on reliability and reproducibility.
Hermes is a control framework for agents.
CORAL could theoretically run on top of Hermes.
-----
3️⃣ OpenClaw — Unified API + auth layer for LLM providers
OpenClaw is about how agents authenticate and call models.
🔸Unified API for multiple LLM providers.
🔸OAuth / PKCE support (where providers allow it).
🔸Credential management.
🔸Routing and fallback logic.
OpenClaw is an infrastructure layer for model access.
CORAL could use OpenClaw as its model backend.
-----
🧐 A simple comparison
CORAL
• Solves: How agents evolve, learn, and coordinate
• Abstraction: High (behavior + evolution)
Hermes Agent
• Solves: How agents run, call tools, and manage loops
• Abstraction: Medium (agent runtime)
OpenClaw
• Solves: How agents authenticate and call LLMs
• Abstraction: Low (infrastructure)
They are complementary, not competitors.
🙋Key takeway:
▫️CORAL is not an agent harness.
▫️Hermes is not an evolutionary system.
▫️OpenClaw is not an autonomy framework.
🤷 Imagin the agent stack as such:
🔹[ Evolution / Autonomy ] ← CORAL
🔹[ Agent Runtime ] ← Hermes
🔹[ Model Access Layer ] ← OpenClaw
🔹[ LLM Providers ] ← Anthropic, OpenAI, etc.
🔍 CORAL sits above Hermes and OpenClaw in the conceptual hierarchy.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Context Engineering & RAG vs. Reliability Engineering💥Are your AI outputs truly trustworthy?
▶️ What RAG and context engineering do.
✓ They're both about assembly — getting the right material into the model's context. RAG retrieves documents and stuffs them into the prompt.
✓ Context engineering is the broader craft: what to retrieve, how to chunk it, what to put in the window, how to order it, what to summarize, what to drop. Both answer the question "what information goes in?" They are upstream, and they are construction work.
🙋 Introducing https://t.co/pi5AgZ8WI9, a foundational reliability layer for AI work that doesn't just produce answers, but ensures they are auditable and trustworthy. It is built to run entirely inside your own environment using your own models.
🤝 The reliability fusion platform is powered by two complementary engines:
🔹The Fusion Engine:
This engine asks, "Which answer is best?". It sends a single question to multiple leading AI models and reconciles their outputs into one consensus answer. It makes the result fully traceable rather than a black box by recording exactly where each part of the answer came from, and verifying the synthesized answer back against the sources.
🔹The Audit Engine:
This engine asks, "Which evidence is trustworthy enough to use?". Instead of judging AI answers, it judges the underlying evidence and documents behind AI work to ensure they are current, complete, and in agreement. It never invents a problem; instead, it returns a reliability rating and traces every finding back to a real, word-for-word quote in your documents. This is critical for high-stakes work where human reviewers need auditable evidence rather than just an automated verdict.
🧐 Where are we heading?
Our vision is to build "fusion as infrastructure"—composing these two engines into a single, continuous reliability loop. This future workflow will gather the right evidence, audit it for trustworthiness, fuse a consensus answer over the vetted material, and then audit the fusion's final output before it is used.
🚨 Inference routing and simply asking several models and combining their answers is quickly becoming a commodity. The true, durable value of AI infrastructure is fully traceable, checked evidence and an audit trail that you can safely keep within your own perimeter.
DM if you would like early access.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Build update from https://t.co/PEdeJRnby5™ 💥 we're breaking ground on Reliability Fusion (https://t.co/pi5AgZ8WI9).
✍️ The Context Operations Lab series (https://t.co/Rh7Mwl20Ta) made the case: the next durable layer isn't model selection or model fusion.
It's reliability fusion...
auditing the evidence, context, and provenance behind AI work, and fusing only what survives into trusted operational context.
That series was the narrative. Now we're building the first slice.
🙋 What we're starting with — deliberately the narrowest, most provable piece:
🔹 It catches the failure mode at the heart of the lab: even when the underlying data is correct, the summary derived from it can quietly drop or distort what matters — and every downstream agent inherits that error.
🔹 The first detections are deterministic — no model guessing. Every finding points to the exact evidence behind it. The system cannot invent a problem that isn't there. That's the entire point: auditable evidence, not opinions.
🔹 Because this first layer needs no model calls, it's designed to run entirely inside your own environment. Reliability you keep in your own perimeter.
🤷 Honest status: this is layer one of several, and it's in progress — not a finished product. We're shipping the narrative as we build it, in the open.
🫣 So what landed for phase 1 reliability fusion that you can explore, examine?
🔍 I can't give you a link yet, but I can show you the core engine catching the exact failure it's built for, with the evidence trail. Want me to walk you through it, or be on the early-access list for the hands-on version?
DM me...
The arc holds:
▶️ Model fusion asks: which model answer is best?
▶️ Reliability fusion asks: which evidence, context, and artifacts are trustworthy enough to use?
🧐 Model fusion was the first layer. The broader pattern is fusion as infrastructure. → https://t.co/pi5AgZ8WI9
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Exciting strategic update for https://t.co/PEdeJRnby5™! 💥The next durable layer is not just model selection or model fusion. It is reliability fusion.
This concludes step four of the Context Operations Lab series:
🔸Post 1 & 2: Context isn't enough (a portable junk drawer is still a junk drawer). We must audit artifacts for freshness, consistency, and routing.
- https://t.co/6WWXox1nkg
- https://t.co/BWoLTmGb0K
🔸Post 3: The meta-harness pattern: LLMs reason, but Hermes TUI provides the harness (files, criteria, repeatability). https://t.co/GUugBiXU66
🔸Post 4: What happens after the audit?
An audit alone isn't the final product. Real value emerges when audited evidence is fused into trusted operational context that another agent, workflow, or decision system can safely use.
🙋 I ran a directional synthesis experiment using existing Experiment 001 artifacts. The task: decide what should be trusted, rejected, repaired, and passed forward.
Instead of listing the seven artifacts twice, here is exactly how the system processed them:
✓ Trusted (2): The clean version/date artifact and the source JSON with GPQA metrics.
✓ Rejected/Downgraded (4): The stale version claim, conflicting accuracy claim, context missing metrics, and poorly routed artifact.
✓ Resolved (1): 52.3% vs 40.91% GPQA accuracy. The 40.91% value was selected to align with the authoritative source JSON, restoring the missing signal (81 out of 198).
🧐 This produced a trusted operational context packet:
▫️Hermes version: v0.16.0
▫️GPQA accuracy: 40.91% (Source: eval JSON)
▫️Excluded: stale, conflicting, missing-signal, poorly routed
▫️Recommendation: Pass this packet forward, not the raw artifact pile.
🔑 The key shift: Context operations audits artifacts. Reliability fusion decides what survives to become trusted operational context.
The bigger opportunity is beyond model fusion.
▶️Model fusion asks: Which model answer is best?
▶️Reliability fusion asks: Which evidence, context, artifacts, evaluations, and workflow outputs are trustworthy enough to use?
That is a different product surface pointing toward an AI infrastructure beyond bigger context windows or parallel models.
We need systems that can:
🔹audit evidence
🔹resolve conflicts
🔹restore missing signals
🔹downgrade weak artifacts
🔹preserve provenance
🔹create reliable handoffs
🔹pass forward trusted operational context
This is the direction I see ModelFusion moving: from fusing model outputs to fusing reliability signals across the workflow.
Model fusion was the first layer. The broader pattern is fusion as infrastructure... https://t.co/pi5AgZ8WI9
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Critiquing the critique...💥AI Personality as an Illusion?! Good read, worth considering critically:
🙋 Assertions:
🔹Applying human psychological instruments to AI is a category error.
🔹The Anthropomorphism Trap
🔹The article critiques the media and research community's eagerness to anthropomorphize AI. Viral headlines claiming a model "tested as a psychopath" or is "highly extraverted" are fundamentally misleading.
🔹How an LLM scores on a personality questionnaire rarely aligns with how it actually behaves or converses in real-world applications.
🔹A "highly agreeable" test score might seamlessly give way to abrasive behavior if the conversational context shifts.
SUMMARY: Apparent Psychological Profiles of Large Language Models are Largely a Measurement Artifact, mathematically proves that applying human personality tests to AI mostly measures a "measurement glitch" (directional response bias).
🤷 Critiquing the critique:
it's a much-needed reality check on anthropomorphizing AI, the conclusions aren't bulletproof. A review of the research methodology:
1️⃣ The "Default State" Fallacy
Testing an unprompted model essentially measures its generic, average alignment state. LLMs are highly malleable role-players. If explicitly prompted to adopt a stable persona, they might successfully and reliably navigate these tests.
2️⃣ The Temperature Zero Assumption
The researchers forced models into their most rigid, deterministic state (temperature zero). Human psychology is inherently probabilistic; stripping this away artificially amplifies structural biases and makes the test a poor proxy for human-like variation.
3️⃣ The Embodiment Problem
Asking a disembodied statistical engine about physical experiences (e.g., "I like to go to parties") lacks construct validity. Defaulting to a response bias here might just be a statistical fallback for a functionally nonsensical question.
4️⃣Diagnosis Without Etiology
The paper excellently diagnoses the symptom (response bias) but misses the disease. Without investigating why this happens - is it an artifact of token positioning? RLHF? - concluding that profiles are purely an artifact feels incomplete.
🧐 I think the authors prove that current human tests are broken when applied to default-state LLMs. But, this doesn't definitively prove that AI cannot possess measurable, stable dispositions under the right prompting conditions or with new, AI-native instruments.
👉 Post 3 of 4: Who performs context operations? 💥 Answering this after the experiment in my Meta-Harness / Context Operations Lab.
🧐 Post 4 PREVIEW: Beyond https://t.co/PEdeJRnby5™... can a meta-harness become part of reliability infrastructure for multi-agent and multi-model fusion workflows?
In Post 1, I argued context is not the moat; context operations are. https://t.co/6WWXox1nkg
In Post 2, I showed a small hands-on experiment: Hermes TUI audited seven synthetic context artifacts for freshness, consistency, completeness, routing, and trustworthiness. https://t.co/BWoLTmGb0K
The audit caught every intended issue:
- stale context
- conflicting claims
- missing evaluation signals
- poorly routed artifacts
- one clean trusted artifact as the control
🫣 The deeper question: What actually did the auditing? Was it Hermes TUI, the model inside, or just an LLM reading files?
The answer: all of those played different roles. There are three layers.
1️⃣ First: the LLM reasoning engine. In my lab, the model did the reasoning. It read the artifacts, compared them against the audit criteria, classified the issues, and wrote the findings. That was the intelligence layer.
2️⃣ Second: Hermes TUI as the audit harness. Hermes TUI provided the workspace around the model:
- file access
- directory structure
- artifact creation
- report writing
- persistent experiment history
- repeatable workflow
Without the harness, this would have been a one-off LLM judgment. With the harness, it became a persistent, inspectable workflow with files, reports, and repeatable criteria.
3️⃣ Third: the meta-harness pattern. This is the bigger idea. 🙋 A meta-harness is a supervisory harness that operates above individual models, agents, or task harnesses.
It does not just answer the task; it audits the systems and artifacts around it.
It asks:
- Is this context fresh?
- Is it consistent?
- Is it complete?
- Did a source artifact contain a signal that the summary dropped?
- Was the artifact routed where downstream systems can use it?
- Can we trust this context enough to pass it forward?
The value comes from reasoning embedded in a repeatable workflow. This became clear in my Hermes + SIA experiment:
🔸SIA ran the GPQA benchmark.
🔸Hermes did not answer GPQA; it inspected the surrounding artifacts.
It noticed evaluation_results.json contained valid metrics, but context.md did not surface them.
✍️ That is a meta-harness role. One harness runs the task. Another audits the artifacts, context flow, and failure modes.
This is where AI infrastructure is headed.
Not one giant agent, but specialized harnesses producing artifacts, and meta-harnesses inspecting, routing, validating, and operationalizing them.
Context operations is the work. The meta-harness performs that work across systems.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Post 2 of 4: Results and lesson from hands-on Meta-Harness / Context Operations Lab 💥 AI Reliability Engineering
THESIS: Fusion as infrastructure - not just fusing model outputs, but fusing artifacts, evaluations, context, and workflows into something reliable enough to trust.
➡️ In Post 1, I argued that a portable junk drawer is still a junk drawer. https://t.co/6WWXox1nkg
Owning your context matters.
Making it portable matters.
But portability does not solve trust.
🙋 So, I tested a narrower question:
Can a supervisory harness audit context artifacts for the kinds of failures that break agent workflows?
The experiment was based on my earlier Hermes + Hexolab's SIA (Self-Improving Agents) run.
In that run, SIA produced valid GPQA evaluation metrics.
🚨 But those metrics were missing from the generated context.md.
🔸The raw data existed.
🔸The context artifact failed.
Downstream agents often do not operate on raw source files.
They operate on extracted, summarized, routed, or remembered context.
If that derived context is stale, incomplete, contradictory, or poorly routed, the agent inherits the error.
-----
✍️ So I created a controlled synthetic test set with seven artifacts:
- an outdated version number
- two contradictory claims about the same result
- a context file that failed to extract metrics
- the source JSON containing the actual metrics
- a valid file written to the wrong location
- a clean, up-to-date reference artifact
Then Hermes TUI audited the set across five dimensions:
- freshness
- consistency
- completeness
- routing / reachability
- trustworthiness
👌 The result:
The audit correctly identified every intended issue.
It found the stale fact.
It found the conflicting claims.
It found the missing evaluation signal.
It found the poorly routed artifact.
And it correctly classified the clean reference file as trustworthy.
-----
1️⃣ Context engineering asks:
What should the AI know right now?
2️⃣ Context operations asks:
Is that context still fresh, consistent, complete, reachable, and trustworthy?
As workflows become more agentic, this distinction matters more.
A model can be strong.
A harness can be well designed.
A memory layer can be portable.
But if the context layer drops the wrong signal, routes an artifact to the wrong place, or preserves a stale claim, the system can still make the wrong decision with confidence.
The durable moat isn't simply “context.”
🤷 The durable layer is context operations.
The ability to audit, govern, route, and maintain context over time.
Meta-harnesses come in...
A task harness produces artifacts.
A memory layer stores them.
A meta-harness audits whether those artifacts are usable.
🔹Fresh.
🔹Consistent.
🔹Complete.
🔹Reachable.
🔹Trustworthy.
Even when the data is correct, context can still fail.
And when context fails, the agent inherits the error.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Great article by Nicolas Fortuin and Baptiste Fernandez - June 2026 Tessl benchmark 💥
▶️ It offers a newer perspective by running four open-source models — GLM 5.2, MiniMax M3, Kimi K2.7 and Qwen3.7 — against Anthropic's Claude Sonnet 4.6 across nearly 1,000 real coding tasks.
Open‑source has caught up with the frontier.
The current leading open‑source models are a different animal.
🔸GLM 5.2 scored 91.9 overall to Sonnet's 90.8, at $0.289 per task versus $0.296 — an open model matching (slightly beating) a frontier model on quality and cost at once.
🔸MiniMax M3 came within a point of Sonnet at roughly 30% lower cost. The "you get what you pay for" premium has largely evaporated.
🙋 So here is the genuine new mental model for any evaluation,
...coding or not:
▶️ The cheapest model was the cautionary tale. Qwen3.7 — about 10x cheaper than anything else at $0.068 per task — had the worst instruction‑following: it would frequently complete the task correctly while ignoring how it was told to do it. Capable, confident, and non‑compliant — the worst possible profile when a model is left to run unattended.
✍️ Clarifications:
1️⃣ "Prompting" vs "agents" — that changes the scorecard:
An agent is the same model placed inside a loop — given tools (run code, edit files, search the web), allowed to act, observe the result, and decide its next step over many turns toward a goal. In the benchmark, each task took 17–27 turns; there is no single "answer," just a sequence of actions.
2️⃣ the "HARNESS":
The software that wraps the model and runs that loop — the tools, the guardrails, the packaged conventions (what Anthropic calls "skills") — is the harness. One clarification worth making, because the framing often gets flipped: the model doesn't become the harness.
🔹The harness is the chassis; the model is the engine that drops into it. What is true — and is arguably the study's most important finding — is that the differentiator is migrating from the model to the harness. The same skill file lifted every model by about 20 points, almost entirely in instruction‑following.
And the frontier labs are now shipping their own harnesses (Claude Code being the clearest example), so a frontier model increasingly arrives bundled inside one.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Post 1 of 4: A portable junk drawer is still a junk drawer. 💥 Context portability does not solve context trust.
This is the follow-on to my previous series (https://t.co/KU5B6z3EL0) on the new meta-harness layer, where I integrated Hermes TUI with Hexolab’s SIA self-improving agent framework.
🙋 That experiment surfaced a useful lesson:
🔹 AI systems increasingly produce artifacts, but those artifacts do not automatically become trusted operational context.
In the Hermes + SIA run, SIA produced valid GPQA evaluation metrics.
The metrics existed.
But they were not carried cleanly into the run’s working context.
🤷 That is the problem.
A context layer can store memory.
A context layer can expose files.
A context layer can make knowledge portable across tools.
➡️ But none of that answers the harder questions:
▫️Is this context still true?
▫️Is it stale?
▫️Does it conflict with newer evidence?
▫️Where did it come from?
▫️Should it be trusted?
▫️Should it be forgotten?
▫️Did the system use the right context for this task?
✏️ The durable moat is not context storage.
It is the operational layer that keeps context trusted, current, and useful.
That is why I think we need a sharper distinction:
🔸Context engineering assembles.
🔸Context operations governs.
🔸A meta-harness executes context operations across systems.
✍️ Put another way:
1️⃣ Context engineering asks:
What should the AI know right now?
2️⃣ Context operations asks:
How do we keep that knowledge accurate over time?
3️⃣ A meta-harness asks:
What supervises the systems producing and using that knowledge?
4️⃣Reliability infrastructure asks:
What makes the whole process trustworthy enough for serious work?
5️⃣Fusion as infrastructure asks:
What happens when models, agents, harnesses, evaluators, context, and workflows become composable?
-----
🤚🏻 This is the next hands-on step after Hermes + SIA.
I’m setting up a Context Operations Lab using Hermes TUI.
The purpose is simple:
Test how a meta-harness detects stale, conflicting, missing, or poorly routed context across agent workflows.
🛠️ The lab will focus on:
- stale context
- conflicting context
- missing evaluation signals
- broken artifact handoffs
- context audit reports
- artifact routing between systems
🤔 The thesis:
➞ Context is not enough.
➞ Context needs operations.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Post 5 of 5 Series (closing): The harness engineering field is convergin 💥what the field looks like▫️what to learn▫️what's still open.
🙋 What the field looks like
Four forces are converging on the same architecture:
1️⃣ Academic survey: The CMU/Yale/Amazon survey mapped 170+ agent systems to a 7-layer taxonomy — Environment, Tools, Context, Lifecycle, Observability, Verification, Governance.
2️⃣ Practitioner framework: The LangChain article (Sydney Runkle) describes the same architecture as 4 middleware levers: deterministic logic, tools, state, stream handlers.
3️⃣ Empirical benchmark: Harness-Bench (Peking + Qiyuan) proved that varying only the harness changes outcomes by 23.8 points on the same task + model pool.
4️⃣ Temporal mode: Addy Osmani's loop engineering essay — a harness with scheduling, state, and verification runs as a loop.
✍️ What to learn if you're an AI Product Manager
1️⃣ The vocabulary. "Execution alignment," "configuration-level measurement," "middleware," "verifier sub-agent," "state file." Use these with your engineers.
2️⃣ The vendor evaluation lens. Don't ask "which model?" Ask: "what does your harness look like? How do you score at the configuration level? What's your verifier architecture?"
3️⃣ The failure modes from Post 2. When production breaks, the first question is which of the 5 harness failure modes it is.
🫣 What's still open
1️⃣ Can harnesses be self-improving? Meta-harness research — using an LLM to design another agent's harness — is early but promising.
2️⃣ What's the right level of opinion in a default harness? Deep Agents (very opinionated) vs. create_agent (very minimal). Both work. Which philosophy wins is unresolved.
3️⃣ How do you evaluate a harness? Benchmarks exist, but a canonical "harness eval suite" doesn't. The field is still figuring it out.
👌 Definitions:
Harness engineering is the discipline of designing the control layer that turns a generic LLM into a reliable, production-grade agent — the architecture, the tools, the verification, the governance, the state, and the loop.
🔸5 layers: Prompting, Prompt Engineering, Loop Configuration, Loop Engineering, Harness Engineering
🔸3 audiences: Non-engineers, AI Engineers, Harness Engineers
🔸1 moat: Models swap. Frameworks swap. Harnesses compound. The model is the commodity you swap in. The harness encodes your business rules, compliance, cost ceilings, verifier architecture. That doesn't swap — it accumulates.
➡️ Series:
▫️Post 0: A PM's map of the field https://t.co/FzeTVeiQ7s
▫️Post 1: 23.8-point Harness-Bench gap https://t.co/WCVSGzvIBZ
▫️Post 2: 5 failure modes drive 61% of all agent failures. https://t.co/HIvZMY580k
▫️Post 3: Execution alignment https://t.co/Up15hCThcq
▫️Post 4: Field is converging, what's settling, what to learn, what's still open
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Post 3 of 4 Series: Execution Alignment Failure 💥 Name it in one word: Reasoning? Workspace? Tools? Verifier?
Execution alignment is a research term, but Product Manager applicable.
✍️ Execution Alignment Defined:
The degree to which a harness preserves correspondence between what the agent reasons about, what the workspace records, what the tools actually do, and what the evaluator checks.
In failed agent runs, this correspondence breaks down.
🔸The agent reasons about one thing.
🔸The tools do another.
🔸The workspace records something else.
🔸The verifier checks a fourth.
They drift apart. The agent "thinks" it succeeded. The verifier says it didn't.
Examples:
1️⃣ The agent is debugging a test failure. It reasons about a hypothesis. It edits a file. But the test it edited isn't the one that failed. Reasoning is misaligned with the workspace.
2️⃣ The agent is processing a customer request. It pulls data from the API. The data is stale. The agent uses it anyway. Tool output is misaligned with current reality.
3️⃣ The agent is producing a report. It has the data. It summarizes it. But the format requires citations, and the agent didn't include them. Reasoning is misaligned with the output contract.
🙋 Until you can name it as execution alignment failure, it's "the agent did weird things"
Then you can debug it: which of the four correspondences broke?
▫ Reasoning?
▫ Workspace?
▫ Tools?
▫ Verifier?
Once you can name the misalignment, you can fix it.
The maker/checker pattern is the architectural answer:
✏️ Never let the same agent that produced the work be the agent that grades the work.
The maker and the checker should be different in at least one of these ways:
➞ Different instructions (different "persona")
➞ Different model (sometimes a stronger, sometimes a smaller)
➞ Different tools (the maker can edit, the checker can only read)
➞ Different context (the checker sees the contract, the maker sees the task)
❌ Same model + same instructions + same tools = not a real checker.
🔸A separate verifier — different model, different instructions — checks that the implementer's output actually matches the contract. The checker enforces alignment.
🔸State files are the alignment spine. When the agent loses track of what it was doing, the state file is what re-aligns it. No state file, no alignment, no reliability.
The vocabulary changes the conversation.
✅ When your engineer says "execution alignment broke at the tool call," you know exactly what they're debugging.
✅ When your vendor says "we have execution alignment monitoring," you know what capability they mean.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Post 5 of 5: A New Direction💥Five posts ago, I set out to test a narrow question: can an AI agent actually improve itself?
I ended up somewhere bigger, a conviction about how serious AI systems are going to be built
🧐 The future of AI systems may not be one perfect autonomous agent. It may be a coordinated stack of specialized harnesses –composable, inspectable, accountable by design –each producing artifacts another system can evaluate, fuse, and operationalize
Payoff of the whole series:
The setup
I integrated Hermes — an operator/analyzer harness, with Hexolab's SIA, a self-improving AI agent. The point wasn't to claim SIA lives "inside" Hermes
It was to test something more interesting: two harnesses working together, each doing what it's best at
🔹SIA runs the self-improvement experiment.
🔹Hermes operates, inspects, and analyzes it.
The first real run
I pointed it at GPQA –a graduate-level science benchmark. SIA built a task-specific agent, answered all 198 questions, scored and analyzed its own mistakes, and generated an improved next-generation agent. Real artifacts, a measurable result (~41% on a genuinely hard benchmark), under a dollar in API cost
That alone was useful. The interesting part came next.
What the second harness caught
Observing the run, Hermes surfaced something SIA couldn't see about itself: the evaluation produced clean structured metrics –but those metrics weren't being carried forward into the run's working context. The signal existed; the workflow dropped it
That's not just a bug. It's a workflow seam –exactly the kind of thing a second harness is positioned to catch, precisely because it's watching from outside the loop
🙋 And that's where the bigger idea clicked.
One agent improving itself is interesting. A second harness observing, analyzing, and operationalizing the first is where the power is
That's the direction this points toward –call it a meta-harness layer: one harness running the loop, another interpreting artifacts, spotting where the workflow breaks, planning the next step, and turning each run into reusable operational knowledge –comparing generations, catching cost/performance tradeoffs, drafting issues, persisting workflows as skills
Generalize it, and it stops being a one-off integration. It becomes a pattern:
→ model fusion
→ agent fusion
→ harness fusion
→ evaluator fusion
→ workflow fusion
Fusion as infrastructure!
This series started as a local test. It ended as the direction I'm taking ModelFusion: fusion not as a feature, but as the reliability infrastructure underneath multi-system AI, and not just across models, but across the whole stack of agents and harnesses being built on top of them.
That's the thesis.
More soon –this is where the real build begins.
📗Post 1: https://t.co/YBrLZwYAJI
📗Post 2: https://t.co/J1FhM8yV9t
📗Post 3: https://t.co/HiPJZKUJ7O
📗Post 4: https://t.co/NOUC8VmLWj
-----
✍️ AI Reliability Engineering Linkedin Group: https://t.co/757iwppAXO
👉 Part 4 of 5 of my hands-on Hermes TUI + Hexolab's SIA integration series...💥LLM Configuration Challenges
Quick reminder on the setup:
I am not embedding SIA inside Hermes. This is a workflow-level integration.
Hermes TUI is acting as the local operator layer inside WSL:
- inspecting the SIA repo,
- documenting the architecture,
- planning the first test,
- and preparing the local run.
SIA remains the self-improvement framework.
In Part 3, I identified GPQA as the first real self-improvement test candidate.
------
🙋 Why GPQA?
Because unlike an easier smoke-test task such as Spaceship Titanic, GPQA includes a working evaluator.
That means SIA can produce a real feedback signal across generations.
Before I can run GPQA, there is a practical gate:
Which provider and model profiles should SIA use?
SIA’s default path is Anthropic:
- default meta agent: Claude Haiku
- default target agent: Claude Haiku
- required environment variable: ANTHROPIC_API_KEY
- install path: sia-agent[claude]
That is the simplest path technically.
But it is currently blocked in my local setup because Claude Pro does not automatically provide an Anthropic API key.
🤷 That distinction matters.
A subscription to a chat product is not the same thing as API access for an autonomous agent framework.
SIA also supports non-Anthropic provider profiles.
The flexible path uses:
- sia-agent[openhands]
- non-Anthropic meta-agent profiles
- provider JSON files
- API keys such as NEBIUS_API_KEY, GEMINI_API_KEY, OPENAI_API_KEY, or TOGETHER_API_KEY
The lowest-risk non-Anthropic path from the existing SIA defaults appears to be a Nebius-based setup, because SIA already includes bundled profiles for Kimi/Qwen-style models through Nebius.
✍️ So the practical decision before the first run is not architectual...
It is operational:
- Which provider do I want to pay for?
- Which profile is already supported?
- Which path minimizes custom configuration?
- Which model is good enough for a low-cost first GPQA run?
This is the part of “self-improving agents” that gets skipped in most commentary.
The loop sounds elegant:
agent → task → evaluator → feedback → improved agent
But in practice, the first real engineering gate is:
Can the system reliably call the right models with the right credentials, cost controls, and profiles?
That is where I am now.
🔍 Next in Part 5:
The first GPQA run — using Hermes TUI as the local operator to launch SIA, inspect the run artifacts, and confirm whether the workflow-level integration actually works.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Post 2 of 4 Series (Post 0 was the map, Post 1 was the proof)💥The 5 failure modes that explain why your agent is "weird"
📕 Article: Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows https://t.co/YgOVu3qE4F
Same research team from Post 1 — Peking University and Qiyuan Tech — analyzed 5,194 failed agent runs.
They found that agent failures cluster into 5 recurring modes.
The two most common account for 61% of all failures.
The 5 failure modes, ranked by frequency:
1️⃣ Contract / format violations — 36.4%. Schema mismatches, malformed JSON, missing ledger rows, incomplete manifests. The agent produced output that doesn't match what the system expects. The model "thought" it was done. The format was wrong.
2️⃣ Tool / recovery failures — 24.6%. A tool call fails or returns an error, and the agent doesn't recover. It retries the same broken call or stalls. The model knows what to do, but the harness didn't handle the failure.
3️⃣ Evidence / grounding failures — 14.6%. Incomplete source coverage, unsupported claims, missing verification. The agent answers without anchoring to evidence. The model is fluent but ungrounded.
4️⃣ Artifact commitment failures — 11.1%. Plausible reasoning without committing the required artifact. The agent explains why something should be true but doesn't write the file, open the ticket, or produce the output the system needs.
5️⃣ State / continuation failures — 9.3%. Failure to preserve progress or resume reliably in multi-round tasks. The agent starts strong, then loses track of what it was doing.
These are "the harness didn't enforce the output contract" or "didn't recover from the tool failure" or "didn't preserve state" failures.
🙋 The model is rarely the bottleneck.
For AI Product Architects:
"The model gave a wrong answer" is almost never the right diagnosis.
🔸The 36% contract violation rate is a prompt problem disguised as a model problem. Add a schema check. Add an output validator. Add a verifier sub-agent. Stop blaming the model for format errors.
🔸The 25% tool/recovery rate is an error handling problem. Add retry logic, fallbacks, and recovery paths. The model can recover; the harness has to enable it.
🔸The 11% artifact commitment rate is a "definition of done" problem. The agent knows the answer but doesn't know to write the file. Make the expected artifact explicit in the harness.
The failures are in the architecture around it.
Series Arc:
📗 Post 0: A PM's map of the field https://t.co/FzeTVeiQ7s.
📗 Post 1: 23.8-point Harness-Bench gap https://t.co/WCVSGzvIBZ
📗 Post 2: 5 failure modes drive 61% of all agent failures.
📗 Post 3: will cover "execution alignment"
📗 Post 4: Field is converging, what's settling, what to learn, what's still open
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO
👉 Part 3 of 5(was 4) of my hands-on Hermes TUI + Hexolab's SIA integration series...💥Harness Engineering Work-in-progress
“What I cannot create, I do not understand.”
- Richard Feynman
🙋 Clarification on creating the integration:
I am not embedding SIA inside Hermes.
➡️ This is a Level 1 workflow-level integration:
Hermes TUI is acting as the local operator layer inside WSL to inspect, configure, run, and eventually analyze SIA experiments.
🔸SIA remains the self-improvement framework.
🔸Hermes TUI is the engineering/operator interface around it.
That distinction matters.
🧐 In this phase, I moved from architecture review into test design.
The question was simple:
What should be the first SIA task to run?
At first, Spaceship Titanic looked like the obvious candidate.
🔹It is a tabular classification task.
🔹It has a familiar ML workflow.
🔹It is easier than GPQA, LawBench, or LongCoT-Chess.
🔹It should be a good lightweight first run.
🫣 But after inspecting the SIA task files and orchestrator behavior, there was a catch:
Spaceship Titanic does not include a task-local https://t.co/1kQKHmV3DB.
And in SIA, if no https://t.co/1kQKHmV3DB exists, the orchestrator does not fall back to a generic scoring method.
It explicitly skips evaluation.
That means:
- no objective score,
- no results.json,
- no measurable performance signal,
- no real feedback loop for improvement.
🤷 So Spaceship Titanic may be useful as a smoke test.
It can help verify that SIA launches, writes files, and produces a submission.
But it is not the best first self-improvement test.
For a true self-improvement loop, the agent needs feedback.
That led to the GPQA task...
💪 GPQA is harder.
✓ But it includes a working evaluator.
✓ The target agent produces a structured submission.
✓ The evaluator compares answers against private ground truth.
✓ The feedback agent receives quantitative performance signal across generations.
🏆 That makes GPQA a better first test of actual self-improvement, even if the task itself is more difficult.
This was an important hands-on lesson:
“Can it run?” and “can it improve?” are different questions.
A task without evaluation can test execution.
A task with evaluation can test learning.
📗 Post 1: Cloning SIA locally with Hermes https://t.co/YBrLZwYAJI
📗Post 2: Self-Improvement Architecture comparison https://t.co/J1FhM8yV9t
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO








![EverymansAI's tweet photo. 👉 Architectures of Autonomy💥1️⃣ CORAL vs. 2️⃣ Hermes Agent vs. 3️⃣ OpenClaw
1️⃣ CORAL — Autonomous multi-agent evolution system
CORAL is about how agents think, evolve, and coordinate.
🔸Agents generate attempts, reflect, consolidate skills.
🔸Multi-agent co-evolution drives exploration.
🔸Shared memory acts as a long-term knowledge base.
The goal is open-ended discovery and self-improvement.
CORAL is a behavioral and evolutionary framework.
✍️ In my next post I'll review the CORAL arxiv article & its associated tooling:
"CORAL: Towards Autonomous Multi-Agent Evolution"
-----
2️⃣ Hermes Agent (by Hexolab) — Agent harness / runtime
Hermes is about how agents are executed, not how they evolve.
🔸Provides a structured agent loop.
🔸Handles tools, retries, error recovery.
🔸Manages context, memory, and tool calls.
🔸Focuses on reliability and reproducibility.
Hermes is a control framework for agents.
CORAL could theoretically run on top of Hermes.
-----
3️⃣ OpenClaw — Unified API + auth layer for LLM providers
OpenClaw is about how agents authenticate and call models.
🔸Unified API for multiple LLM providers.
🔸OAuth / PKCE support (where providers allow it).
🔸Credential management.
🔸Routing and fallback logic.
OpenClaw is an infrastructure layer for model access.
CORAL could use OpenClaw as its model backend.
-----
🧐 A simple comparison
CORAL
• Solves: How agents evolve, learn, and coordinate
• Abstraction: High (behavior + evolution)
Hermes Agent
• Solves: How agents run, call tools, and manage loops
• Abstraction: Medium (agent runtime)
OpenClaw
• Solves: How agents authenticate and call LLMs
• Abstraction: Low (infrastructure)
They are complementary, not competitors.
🙋Key takeway:
▫️CORAL is not an agent harness.
▫️Hermes is not an evolutionary system.
▫️OpenClaw is not an autonomy framework.
🤷 Imagin the agent stack as such:
🔹[ Evolution / Autonomy ] ← CORAL
🔹[ Agent Runtime ] ← Hermes
🔹[ Model Access Layer ] ← OpenClaw
🔹[ LLM Providers ] ← Anthropic, OpenAI, etc.
🔍 CORAL sits above Hermes and OpenClaw in the conceptual hierarchy.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO](https://pbs.twimg.com/media/HL2Psz3b0AAzve8.jpg)











![EverymansAI's tweet photo. 👉 Part 4 of 5 of my hands-on Hermes TUI + Hexolab's SIA integration series...💥LLM Configuration Challenges
Quick reminder on the setup:
I am not embedding SIA inside Hermes. This is a workflow-level integration.
Hermes TUI is acting as the local operator layer inside WSL:
- inspecting the SIA repo,
- documenting the architecture,
- planning the first test,
- and preparing the local run.
SIA remains the self-improvement framework.
In Part 3, I identified GPQA as the first real self-improvement test candidate.
------
🙋 Why GPQA?
Because unlike an easier smoke-test task such as Spaceship Titanic, GPQA includes a working evaluator.
That means SIA can produce a real feedback signal across generations.
Before I can run GPQA, there is a practical gate:
Which provider and model profiles should SIA use?
SIA’s default path is Anthropic:
- default meta agent: Claude Haiku
- default target agent: Claude Haiku
- required environment variable: ANTHROPIC_API_KEY
- install path: sia-agent[claude]
That is the simplest path technically.
But it is currently blocked in my local setup because Claude Pro does not automatically provide an Anthropic API key.
🤷 That distinction matters.
A subscription to a chat product is not the same thing as API access for an autonomous agent framework.
SIA also supports non-Anthropic provider profiles.
The flexible path uses:
- sia-agent[openhands]
- non-Anthropic meta-agent profiles
- provider JSON files
- API keys such as NEBIUS_API_KEY, GEMINI_API_KEY, OPENAI_API_KEY, or TOGETHER_API_KEY
The lowest-risk non-Anthropic path from the existing SIA defaults appears to be a Nebius-based setup, because SIA already includes bundled profiles for Kimi/Qwen-style models through Nebius.
✍️ So the practical decision before the first run is not architectual...
It is operational:
- Which provider do I want to pay for?
- Which profile is already supported?
- Which path minimizes custom configuration?
- Which model is good enough for a low-cost first GPQA run?
This is the part of “self-improving agents” that gets skipped in most commentary.
The loop sounds elegant:
agent → task → evaluator → feedback → improved agent
But in practice, the first real engineering gate is:
Can the system reliably call the right models with the right credentials, cost controls, and profiles?
That is where I am now.
🔍 Next in Part 5:
The first GPQA run — using Hermes TUI as the local operator to launch SIA, inspect the run artifacts, and confirm whether the workflow-level integration actually works.
-----
AI Reliability Engineering:
✍️ Join the ModelFusion™ builder Linkedin group: https://t.co/757iwppAXO](https://pbs.twimg.com/media/HK3V1BGbcAAGUOv.jpg)































