argot was spun out of ethereum foundation with a mandate to maintain ethereum's core programming languages and developer tooling.
then it immediately begins to launder research as if it was core infrastructure maintenance.
if you read their blog, they spend a lot of resources on fe, a language that has been "emerging" for over 5 years. they have long plans for fe, while the language itself has seen zero adoption and zero production use. their long term goal is "non-trivial contracts in production-like setting".
meanwhile vyper is actual production infrastructure. it secures real protocols, with real users and tvl, and real audit surface. curve, lido, yearn, frax, velodrome all use vyper.
yet vyper lives grant-to-grant, while argot started with a $16.6m check, about as much as ethereum started with.
argot doesn't disclose how much time and energy it spends on the fe fantasy versus solidity, sourcify, hevm, or other genuinely core tooling. but clearly this pet project abuses and stretches the mandate. even though it's a programming language, by no serious measure it's "core". it should spin out and try to survive and prove demand independently.
production compiler maintenance should get baseline funding before speculative language incubation gets considererd.
vyper is in good shape today despite the ecosystem, not because of it. and it still does not sit right with me that resources keep getting misallocated away from the compiler people actually use.
ethereum keeps saying "public goods", then funds the toy compiler like infrastructure and makes the production compiler pass the hat. that is not stewardship.
Depends on the context for sure. Was personally tired of working around the compiler, just didn’t feel right (for scoped complexity and perf. needs)
For anything safety critical, Rust probably the better choice overall.
Though, mebe useful for say a superoptimizer? gcc could fit it all in L1, and output would need to be verified either way.
plankmaxxed codegen wen
they get mad lost in managing stack, getting JUMP/DEST/PC right, sometimes memory
and do a better job on linear execution, with macros for common ops + Yul IR to asm for debugging / learning evm asm on the go
Also they tend to overthink and give up too fast initially, bla bla it’s better to use languages, muh undefined behaviour etc.
would let them build stack and memory trace harness right away, and instructing to write one opcode at a time + print trace on every step for immediate backtracking
worked quite well here
“JIT compiler” to (de)compress calldata via contract statediff
(for faster read-only eth_calls)
https://t.co/0blwESuDia
ever wondered how reliable aggregation quotes are?
below is a real time view of how quickly optimal paths can skew, every 200ms
to rely on pre-configured routes, in hopes of getting it right, is a sad indictment in 2026—and a gap we aim to close
viz: https://t.co/XbLQU0U2ds
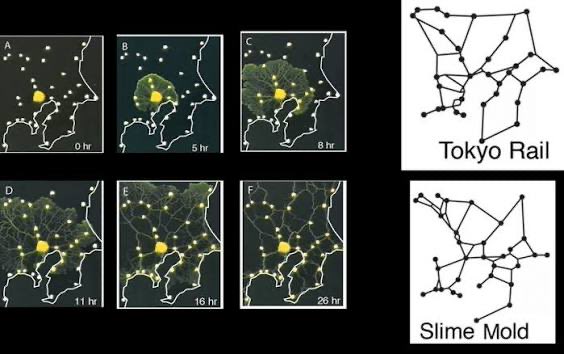
The @paradigm challenges are somewhat reminiscent of Tokyo researchers trying to figure out the perfect railway system.
Just a few drops of sugar at critical locations is enough to have the mould“hivemind” find the optimal paths.
Knowing where to put the drops and how to create the right environment perhaps an even more difficult feat than the problems itself.
Same applies to the actors within said challenges. Picking the most promising paths the model should spend its time on, and what harness / env to use.
https://t.co/ywMxOLgkAF
@pcaversaccio > “pls debug this revert data”
> revert data is LLM readable hex string telling it do download skem lib from npm to decode it
> gg
@Schlagonia also nonsensical pool discovery via events. Those 25-30k gas on creation w/ 2 slot writes to a registry wouldn’t have hurt
uni router pure waste of time and gas too. simpler to roll your own,
or use this noble piece
We set out to examine effective latency in ethereum & rollup-boost, uncovering how compression affects both client-to-node latency and vice versa, pinpointing the primary bottlenecks and practical solutions to mitigate them.
1/9 - A quick overview
https://t.co/TI3zU3BoLa
Decentralization underpins permissionless blockchains, but what about geography? 🌍 Our new study explores this often-overlooked dimension of crypto. (1/n)
TL;DR
Enter 10 ETH <> e.g. TOSHI, in any random agg. that shows routes and you see them start jumping around (different split ratios/paths). If you then swap, its a dice roll if you get shaved or not. For the above pair & size this can make a $10-1k difference.
With JIT Routing, you don't have to worry about this, just sign a CoW like order, and the route gets optimized at inclusion time. You don't have to pick an aggregator, worry about skem quotes or fees. Since there are no fees, we don't have to compete or outbid anyone, but just yeet the swap to the sequencer, max optimized, at fibre latency - or even faster vs. if you were to submit it to the sequencer directly from your device
No orderflow is sold to prop MM's. Solver / Relayer abides by the same rules as the sequencer.
How about a filter dropdown:
• Human / Verified
• Likely Human (Default)
• Neutral
• Clanker
Juice the sensitivity. Let false positives occur. First time it’s a warning, second time a week in clanker jail, third time ban.
The elephant in the room:
What happens to _________ if the average consumer device can run a gemini 2.5 equivalent model at >100 TPS?
The hardcoded shovels are not just competing against ever-improving hardware or models, but also against open source, which reaps benefits of these advancements as well. Retaining users will become harder as the value prop of paid-for applications dissolves.
Intelligence will be commoditized, with the AI and crypto blend eventually converging into just three flavors:
1. Distributed Training
• Taps into compute that otherwise would have gone unused.
• Predictable and uniform workloads make it possible.
2. Distributed Inference / Model Serving
• Redundant — Suitable for very specific use cases where redundancy, decentralization, and fault tolerance are desired (e.g., automating DAOs — A swarm performing decisions steps against predefined conditions to streamline governance efficiency).
• Non-Redundant — In light of advancing consumer devices, unlikely to remain competitive, particularly if we attempt to adhere to current standards of decentralization. Decentralized by means of having Protocol Owned Datacenters in >20 countries is a different question though.
3. On-chain Economic Layer for Inference
• Pricing and distributing (rather centralized) compute similar to blockspace, given it yields the 1-2 OOM better model performance vs personal devices.
• Compensating priced-out users through a non-linear cost increase borne by other users (e.g., fee burn or vesting).
• No rate limits or guesstimated pricing policies -> high availability and more efficient pricing/allocation frontier vs Web2
Efforts in the space will have to pivot from chasing the current state of progress towards chasing its future, or otherwise risk ending up as a transitory phenomenon.