A medical LLM can give the right answer for the wrong reasons.
Delighted our work is now published in Nature Communications Medicine — evaluating 8 LLMs on 1,269 unstructured seizure descriptions, with a practical guideline to use AI in clinical setup 🧵
https://t.co/lEcxdfLGBw
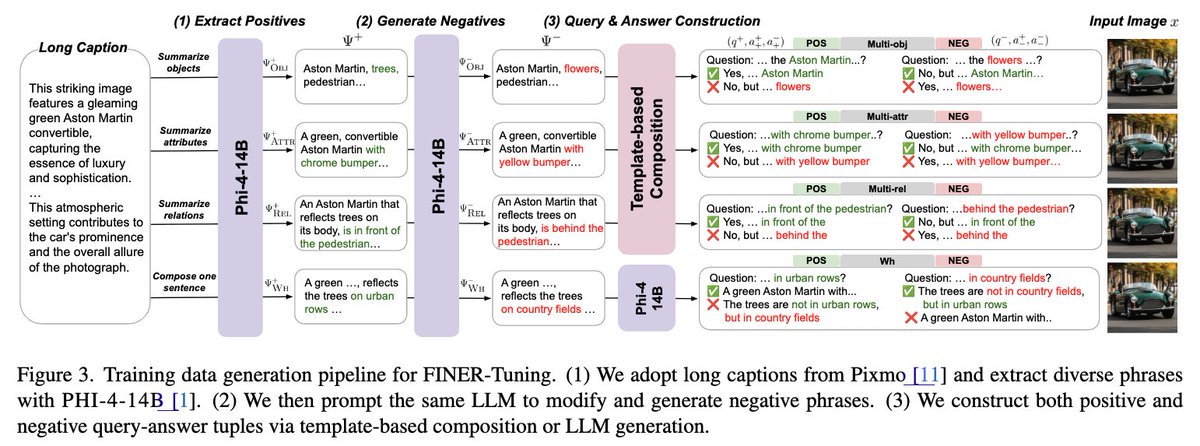
Results: FINER-Tuning improves performance on our FINER benchmarks, transfers to other hallucination benchmarks, and even boosts general MLLM ability. On InternVL3.5-14B, we get up to +24.2% on FINER without hurting overall capability.
We also introduce FINER-Tuning: generate fine-grained positive/negative phrases from dense captions, turn them into accept/reject QA pairs, and train MLLMs with DPO so they learn to spot subtle mismatches instead of hallucinating.
Excited to share that our paper “Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps” won the Best Paper Award at the #ICLR2026 ReALM-GEN Workshop 🎉✨
Check out the paper & code 👇
📕 https://t.co/tldXU83WD1
💻 https://t.co/qY7f827rSI
Accurate reward guidance in diffusion models has been a long-standing challenge.
We propose Diamond Maps 💎, through stochastic flow maps we make reward guidance both accurate and scalable.
Our EML members are heading for Rio🇧🇷 for #ICLR2026! 🌴We’re excited to share our latest research — three poster presentations. Check out the thread below and come say hi to our authors