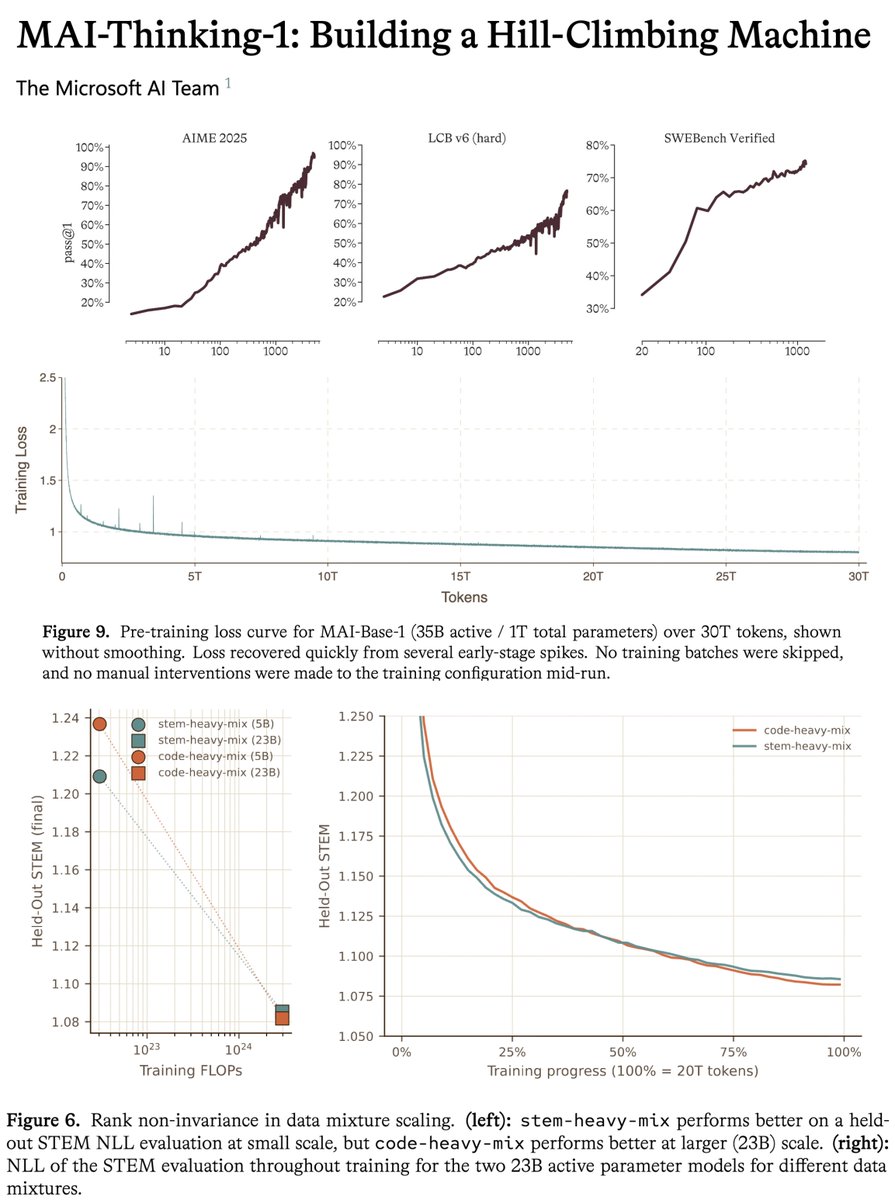
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
@_seemethere I think testing cuts both ways. Too many tests wastes a lot of tokens, especially if the specs are changing. I also feel model capability isn't good enough to adhere to vision; at best you can have a bunch of mechanical rules that the reviewer LLMs can enforce
The PyTorch Conference NORAM talk submission deadline is June 7th! If you've got something interesting to talk about in PyTorch, send in your proposal! https://t.co/c3qNqFZeQU
@SkyLi0n The API isn't magic lol. All you're doing is running your forward twice (forward/recompute) and it makes it easy to make the recompute phase do all the right things (recompute or load from saved tensors). If you want a tile-based remat you still gotta write it haha
I've been experimenting with a new activation checkpointing API, which we're calling torch_remat. We're still putting it through the paces, but I think it's already interesting enough to get some initial public feedback: https://t.co/ehFjWVC2Sz
Lots of credit to Natalia Gimelshein for the original conception of this API, and @albanDesmaison and Jeffrey Wan for review and the original checkpointing APIs this build up on.
The overall goal of this API is that, by default, *everything* is recomputed, and then you can very explicitly write out what exactly you want to save for backwards.
torch_remat is alpha software and definitely not production ready; we'll be working on making sure it works in real world use cases before making it more official. But I think it has some pretty interesting ideas already to think about.
It is particularly designed for codebases that make a lot of use of custom autograd Functions, which is common in advanced PyTorch codebases that need more control over what is saved for backwards compared to what basic PyTorch operations provide.
torch_remat most directly competes with SAC, where you specify a policy function which specifies, on a per operation basis, if you want to save or recompute it. torch_remat flips this on its head: instead, you specify if you want to save/recompute on a per op call basis.
New devlog post from yours truly: When does fragmentation occur in the CUDA caching allocator? https://t.co/ocAdv4mjy2 -- this post is LLM authored but I heavily prompted/edited, and Natalia also helped fact check.
@henrylhtsang The actual pointer access no, since both cuMemMap and cudaMalloc are using UVA. There's probably some different CPU side overhead re the two APIs but the caching allocator is here to amortize that lol
I ended up prompting it this morning because I was helping some users who were still confused about their fragmentation problems and didn't realize they should use expandable segments. So nothing is here is new, but trying to spell it out more clearly for the masses!
One of the reasons some footguns in PyTorch persist is because it would be BC-breaking to change the defaults. I'm kind of wondering if something like language editions (similar to C++20) could help us batch defaults updates and make them more accessible.
@giffmana I don't want parallel libraries. The most conservative version of this proposal only lets NFE change global config toggles: expandable segments, various compiler configs, etc. I definitely don't want a py3k situation