Our manuscript on a 3.1Å structure of Arabidopsis RDR2 and its RNA template requirements is out from PNAS today - I really appreciate all co-authors and collaborators on this project!
Structure and RNA template requirements of Arabidopsis RNA-DEPENDENT RNA POLYMERASE 2 https://t.co/wD73Wi2AsL
Now published in PNAS as an open access article.
#TansleyInsight: The environmentally responsive plant epigenome: insights from #jasmonate signaling
Mark Zander and Emily Vesper
👇
📖 https://t.co/nNahaG6RTb
#LatestIssue
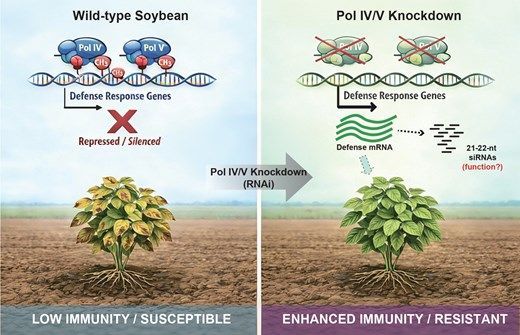
Soybean RNA polymerases IV and V repress defense response genes and plant immunity (Xufeng Wang , Brandon H Le , Ye Xu , Penglin Sun , Min Qiu , Yao Zhao , et al) https://t.co/iceFkY1pXE @Xuemei_RNAlab@ASPB#PlantSci
Our paper on the transcription-coupled H3K36me3 deposition is finally out! We found that histone methyltransferase Set2 deposits H3K36me3 specifically on the reassembled nucleosome in coordination with FACT.
Great collaboration with Sekine Lab!
https://t.co/2SSmAlS5rJ
Excited to share our latest preprint: PlantRNA-FM, the first interpretable RNA AI foundation model for exploring functional RNA motifs in plants🌱🧬 A great collaboration with Ke Li's group @UniofExeter@HaopengYu@JohnInnesCentre
https://t.co/GW5nVoGWQt
So proud of my lab for our latest work out today in @Naturepub. We took advantage of transposable elements and CRISPR to perform targeted insertion of cargo DNA in the Arabidopsis and soy genomes. Led by @mcliupeng. https://t.co/wSvr1uuEbF. 🧵
The ChimeraX 1.8 release is available. Varying ribbon thickness ("worms") shows B-factor across human spliceosome structure PDB 8c6j. See what else is new in the ChimeraX change log. https://t.co/l6o1oqZude
Excited to introduce EMSuite Server! Our cryo-EM structure modeling and validation tools are now easily accessible on this web server: https://t.co/zCv7L2Md2g. Includes DeepMainmast, CryoREAD, DAQ, DiffModeler, and more!
If a job fails, we provide feedback within 24 hours.
We love the excitement & results from the community on AlphaFold 3 and are doubling the AF Server daily job limit to 20. Happy to also share that we're working on releasing the AF3 model (incl weights) for academic use, which doesn’t depend on our research infra, within 6 months.
GH123 has expanded
#glycotime
Sumida, T., Hiraoka, S., Usui, K. et al. Genetic and functional diversity of β-N-acetylgalactosamine-targeting glycosidases expanded by deep-sea metagenome analysis.Nat Commun 15, 3543 (2024). https://t.co/I60pHd9ZVc
Announcing AlphaFold 3: our state-of-the-art AI model for predicting the structure and interactions of all life’s molecules. 🧬
Here’s how we built it with @IsomorphicLabs and what it means for biology. 🧵 https://t.co/gjw6Ip4F2M
Our new paper about the structural mechanism by which RAD51 assembles at double-stranded DNA break sites on chromatin has been published in Nature!
https://t.co/bR8Oxjv8RP
#CryoEM#Nucleosome#RAD51#DNArepair
Our first paper on RNAi-independent functions of DCL2 is now out in The Plant Cell! A rare case where the phenotypic strength is proportional to enzyme levels over a >20-fold range! "Seeing is believing, but measuring is knowing..." :-) https://t.co/RpvcjmJT6u
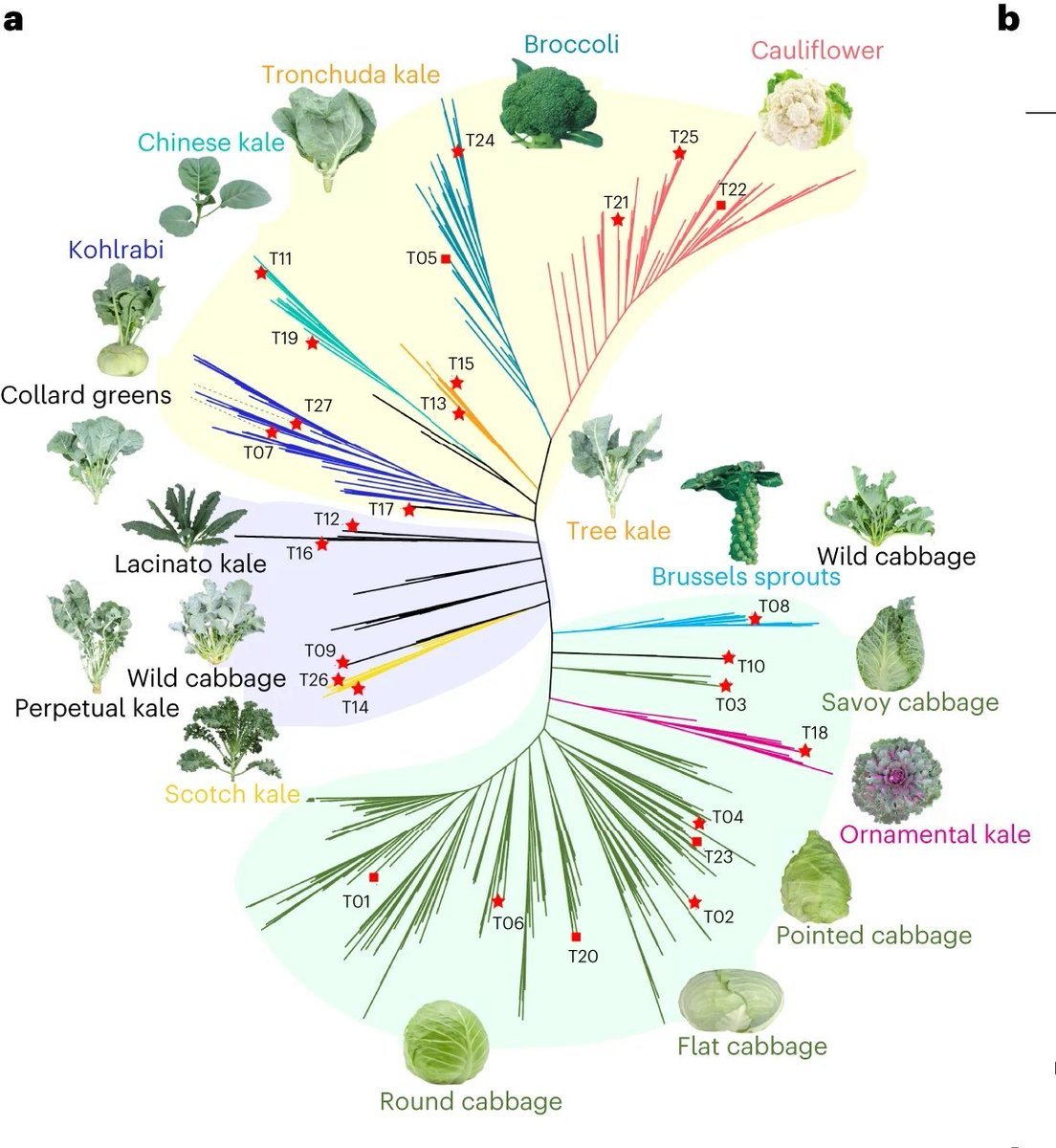
Do you know that cauliflower, broccoli, cabbage and kale are, in fact, the same species? Wonder what driver morphotype diversification between them? Check publication @NatureGenet from scientists at CAAS and @GuusjeBonnema@WUR
https://t.co/8vlMuVhvJS
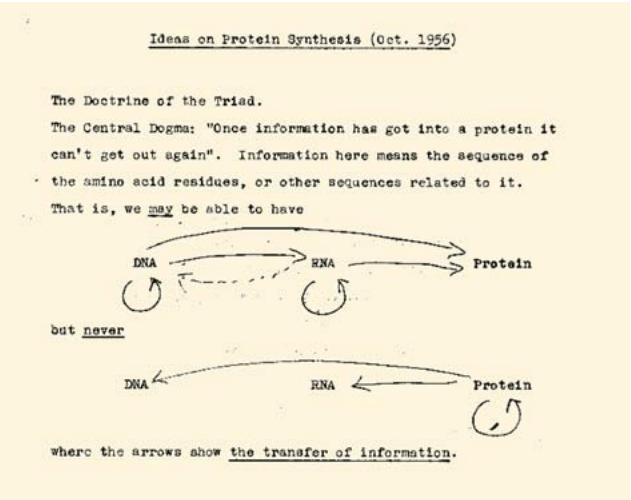
"now famous image" honestly still not famous enough
if biology classes reliably included this image so many misunderstandings about the central dogma would vanish
Francis Crick correctly predicted the basic details of protein synthesis by 1958, years before direct experimental evidence had confirmed the existence of mRNA or tRNA.
His 1958 paper on the subject is among the best in molecular biology's history.
***
After solving the structure of DNA with James Watson, based on x-ray diffraction images obtained by Rosalind Franklin at King's, Crick traveled the world to lecture on a topic that "permanently altered the logic of biology," according to Horace Judson in The Eighth Day of Creation.
In his lectures, Crick sketched a now-famous image on the blackboard: the Central Dogma.
Crick had sketched this image several times by 1956, even though mRNA was not experimentally confirmed by scientists until 1961.
In 1958, Crick adapted his lecture into a published article, called On Protein Synthesis. His target audience was “a general reader rather than the specialist." The article gave two hypotheses to explain the relationship between DNA and proteins, called the Sequence Hypothesis and the Central Dogma.
“The direct evidence for both of them is negligible,” Crick wrote, “but I have found them to be of great help in getting to grips with these very complex problems.”
The sequence hypothesis, “in its simplest form,” Crick continued, “assumes that the specificity of a piece of nucleic acid is expressed solely by the sequence of its bases, and that this sequence is a (simple) code for the amino acid sequence of a particular protein.” In other words, the bases in a strand of DNA or RNA corresponds to the amino acids in a protein.
The Central Dogma, Crick wrote, “states that once 'information' has passed into protein it cannot get out again.” In other words, “the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible.”
(Importantly, the Central Dogma is not simply DNA --> RNA --> protein, because RNA can be reverse transcribed into DNA, etc.)
This passage marked the first time that the Central Dogma, the defining idea of molecular biology, had been published. But this is not why Crick’s article was so prescient.
In the article, Crick used scattered experimental evidence and anecdotal observations -- such as the fact that "spermatozoa contain no RNA" -- to correctly predict that there must be a messenger RNA molecule in the cytoplasm that is produced by "the DNA of the nucleus."
But his astounding ability to theorize was most prominently displayed when he correctly inferred the existence of tRNAs, predicted what they were made of, and explained how they likely became 'charged' with amino acids for protein synthesis.
We now know that proteins are generally made from 20 amino acids. These amino acids are carried to the ribosome by tRNA molecules. And these tRNA molecules get 'loaded' with the correct amino acid via the action of specific enzymes. This is how a message encoded in a strand of RNA is used by the ribosome to build a protein. But Crick had little evidence for any of this. And yet, in 1958, he wrote:
"Granted that...[mRNA]...is the template, how does it direct the amino acids into the correct order? One's first naive idea is that the RNA will take up a configuration capable of forming twenty different 'cavities', one for the side-chain of each of the twenty amino acids. If this were so, one might expect to be able to play the problem backwards -- that is, to find the configuration of RNA by trying to form such cavities. All attempts to do this have failed, and on physical chemical grounds the idea does not seem in the least plausible...
Apart from the phosphate-sugar backbone, which we have assumed to be regular and perhaps linked to the structural protein of the particles, RNA presents mainly a sequence of sites where hydrogen bonding could occur. One would expect, therefore, that whatever went on to the template in a specific way did so by forming hydrogen bonds. It is therefore a natural hypothesis that the amino acid is carried to the template by an 'adaptor' molecule, and that the adaptor is the part which actually fits on to the RNA. In its simplest form one would require twenty adaptors, one for each amino acid.
What sort of molecules such adaptors might be is anybody's guess. They might, for example, be proteins...though ·personally I think that proteins, being rather large molecules, would take up too much space. They might be quite unsuspected molecules, such as amino sugars. But there is one possibility which seems inherently more likely than any other-that they contain nucleotides. This would enable them to join on to the RNA template by the same 'pairing' of bases as is found in DNA, or in polynucleotides.
If the adaptors were small molecules one would imagine that a separate enzyme would be required to join each adaptor to its own amino acid and that the specificity required to distinguish between, say, leucine, isoleucine and valine would be provided by these enzyme molecules instead of by cavities in the RNA. Enzymes, being made of protein, can probably make such distinctions more easily than can nucleic acid."
***
This paper is beautiful. I think every student should read it. In the same piece, Crick also predicted that “scientists would be able to explore rich evolutionary sources of information by comparing sequence data,” as Matthew Cobb has written about Crick’s classic paper, and that the main features of protein synthesis would be uncovered within the next ten years. (Here's Cobb: https://t.co/jg87LGem0t)
On this final point, Crick was wrong. Just four years later, in 1961, a spattering of papers confirmed many of Crick’s predictions.
Read the article: https://t.co/bkOyK7LTs2
Happy to share the officially accepted version of Nastia's paper, "Tail-tape-fused virion and non-virion RNA polymerases of a thermophilic virus with an extremely long tail," in Nature Communications!
https://t.co/8oR2CQzV10
All enzymologists beware: new recombinant albumin, which replaced good old BSA (or something else in the prep/buffer), from @NEBiolabs, is a potent inhibitor of the MRE11 complex. Check with your favorite enzymes!

















![NikoMcCarty's tweet photo. Francis Crick correctly predicted the basic details of protein synthesis by 1958, years before direct experimental evidence had confirmed the existence of mRNA or tRNA.
His 1958 paper on the subject is among the best in molecular biology's history.
***
After solving the structure of DNA with James Watson, based on x-ray diffraction images obtained by Rosalind Franklin at King's, Crick traveled the world to lecture on a topic that "permanently altered the logic of biology," according to Horace Judson in The Eighth Day of Creation.
In his lectures, Crick sketched a now-famous image on the blackboard: the Central Dogma.
Crick had sketched this image several times by 1956, even though mRNA was not experimentally confirmed by scientists until 1961.
In 1958, Crick adapted his lecture into a published article, called On Protein Synthesis. His target audience was “a general reader rather than the specialist." The article gave two hypotheses to explain the relationship between DNA and proteins, called the Sequence Hypothesis and the Central Dogma.
“The direct evidence for both of them is negligible,” Crick wrote, “but I have found them to be of great help in getting to grips with these very complex problems.”
The sequence hypothesis, “in its simplest form,” Crick continued, “assumes that the specificity of a piece of nucleic acid is expressed solely by the sequence of its bases, and that this sequence is a (simple) code for the amino acid sequence of a particular protein.” In other words, the bases in a strand of DNA or RNA corresponds to the amino acids in a protein.
The Central Dogma, Crick wrote, “states that once 'information' has passed into protein it cannot get out again.” In other words, “the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible.”
(Importantly, the Central Dogma is not simply DNA --> RNA --> protein, because RNA can be reverse transcribed into DNA, etc.)
This passage marked the first time that the Central Dogma, the defining idea of molecular biology, had been published. But this is not why Crick’s article was so prescient.
In the article, Crick used scattered experimental evidence and anecdotal observations -- such as the fact that "spermatozoa contain no RNA" -- to correctly predict that there must be a messenger RNA molecule in the cytoplasm that is produced by "the DNA of the nucleus."
But his astounding ability to theorize was most prominently displayed when he correctly inferred the existence of tRNAs, predicted what they were made of, and explained how they likely became 'charged' with amino acids for protein synthesis.
We now know that proteins are generally made from 20 amino acids. These amino acids are carried to the ribosome by tRNA molecules. And these tRNA molecules get 'loaded' with the correct amino acid via the action of specific enzymes. This is how a message encoded in a strand of RNA is used by the ribosome to build a protein. But Crick had little evidence for any of this. And yet, in 1958, he wrote:
"Granted that...[mRNA]...is the template, how does it direct the amino acids into the correct order? One's first naive idea is that the RNA will take up a configuration capable of forming twenty different 'cavities', one for the side-chain of each of the twenty amino acids. If this were so, one might expect to be able to play the problem backwards -- that is, to find the configuration of RNA by trying to form such cavities. All attempts to do this have failed, and on physical chemical grounds the idea does not seem in the least plausible...
Apart from the phosphate-sugar backbone, which we have assumed to be regular and perhaps linked to the structural protein of the particles, RNA presents mainly a sequence of sites where hydrogen bonding could occur. One would expect, therefore, that whatever went on to the template in a specific way did so by forming hydrogen bonds. It is therefore a natural hypothesis that the amino acid is carried to the template by an 'adaptor' molecule, and that the adaptor is the part which actually fits on to the RNA. In its simplest form one would require twenty adaptors, one for each amino acid.
What sort of molecules such adaptors might be is anybody's guess. They might, for example, be proteins...though ·personally I think that proteins, being rather large molecules, would take up too much space. They might be quite unsuspected molecules, such as amino sugars. But there is one possibility which seems inherently more likely than any other-that they contain nucleotides. This would enable them to join on to the RNA template by the same 'pairing' of bases as is found in DNA, or in polynucleotides.
If the adaptors were small molecules one would imagine that a separate enzyme would be required to join each adaptor to its own amino acid and that the specificity required to distinguish between, say, leucine, isoleucine and valine would be provided by these enzyme molecules instead of by cavities in the RNA. Enzymes, being made of protein, can probably make such distinctions more easily than can nucleic acid."
***
This paper is beautiful. I think every student should read it. In the same piece, Crick also predicted that “scientists would be able to explore rich evolutionary sources of information by comparing sequence data,” as Matthew Cobb has written about Crick’s classic paper, and that the main features of protein synthesis would be uncovered within the next ten years. (Here's Cobb: https://t.co/jg87LGem0t)
On this final point, Crick was wrong. Just four years later, in 1961, a spattering of papers confirmed many of Crick’s predictions.
Read the article: https://t.co/bkOyK7LTs2](https://pbs.twimg.com/media/GDflYGwXgAA_4uP.png)






















![NikoMcCarty's tweet photo. Francis Crick correctly predicted the basic details of protein synthesis by 1958, years before direct experimental evidence had confirmed the existence of mRNA or tRNA.
His 1958 paper on the subject is among the best in molecular biology's history.
***
After solving the structure of DNA with James Watson, based on x-ray diffraction images obtained by Rosalind Franklin at King's, Crick traveled the world to lecture on a topic that "permanently altered the logic of biology," according to Horace Judson in The Eighth Day of Creation.
In his lectures, Crick sketched a now-famous image on the blackboard: the Central Dogma.
Crick had sketched this image several times by 1956, even though mRNA was not experimentally confirmed by scientists until 1961.
In 1958, Crick adapted his lecture into a published article, called On Protein Synthesis. His target audience was “a general reader rather than the specialist." The article gave two hypotheses to explain the relationship between DNA and proteins, called the Sequence Hypothesis and the Central Dogma.
“The direct evidence for both of them is negligible,” Crick wrote, “but I have found them to be of great help in getting to grips with these very complex problems.”
The sequence hypothesis, “in its simplest form,” Crick continued, “assumes that the specificity of a piece of nucleic acid is expressed solely by the sequence of its bases, and that this sequence is a (simple) code for the amino acid sequence of a particular protein.” In other words, the bases in a strand of DNA or RNA corresponds to the amino acids in a protein.
The Central Dogma, Crick wrote, “states that once 'information' has passed into protein it cannot get out again.” In other words, “the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible.”
(Importantly, the Central Dogma is not simply DNA --> RNA --> protein, because RNA can be reverse transcribed into DNA, etc.)
This passage marked the first time that the Central Dogma, the defining idea of molecular biology, had been published. But this is not why Crick’s article was so prescient.
In the article, Crick used scattered experimental evidence and anecdotal observations -- such as the fact that "spermatozoa contain no RNA" -- to correctly predict that there must be a messenger RNA molecule in the cytoplasm that is produced by "the DNA of the nucleus."
But his astounding ability to theorize was most prominently displayed when he correctly inferred the existence of tRNAs, predicted what they were made of, and explained how they likely became 'charged' with amino acids for protein synthesis.
We now know that proteins are generally made from 20 amino acids. These amino acids are carried to the ribosome by tRNA molecules. And these tRNA molecules get 'loaded' with the correct amino acid via the action of specific enzymes. This is how a message encoded in a strand of RNA is used by the ribosome to build a protein. But Crick had little evidence for any of this. And yet, in 1958, he wrote:
"Granted that...[mRNA]...is the template, how does it direct the amino acids into the correct order? One's first naive idea is that the RNA will take up a configuration capable of forming twenty different 'cavities', one for the side-chain of each of the twenty amino acids. If this were so, one might expect to be able to play the problem backwards -- that is, to find the configuration of RNA by trying to form such cavities. All attempts to do this have failed, and on physical chemical grounds the idea does not seem in the least plausible...
Apart from the phosphate-sugar backbone, which we have assumed to be regular and perhaps linked to the structural protein of the particles, RNA presents mainly a sequence of sites where hydrogen bonding could occur. One would expect, therefore, that whatever went on to the template in a specific way did so by forming hydrogen bonds. It is therefore a natural hypothesis that the amino acid is carried to the template by an 'adaptor' molecule, and that the adaptor is the part which actually fits on to the RNA. In its simplest form one would require twenty adaptors, one for each amino acid.
What sort of molecules such adaptors might be is anybody's guess. They might, for example, be proteins...though ·personally I think that proteins, being rather large molecules, would take up too much space. They might be quite unsuspected molecules, such as amino sugars. But there is one possibility which seems inherently more likely than any other-that they contain nucleotides. This would enable them to join on to the RNA template by the same 'pairing' of bases as is found in DNA, or in polynucleotides.
If the adaptors were small molecules one would imagine that a separate enzyme would be required to join each adaptor to its own amino acid and that the specificity required to distinguish between, say, leucine, isoleucine and valine would be provided by these enzyme molecules instead of by cavities in the RNA. Enzymes, being made of protein, can probably make such distinctions more easily than can nucleic acid."
***
This paper is beautiful. I think every student should read it. In the same piece, Crick also predicted that “scientists would be able to explore rich evolutionary sources of information by comparing sequence data,” as Matthew Cobb has written about Crick’s classic paper, and that the main features of protein synthesis would be uncovered within the next ten years. (Here's Cobb: https://t.co/jg87LGem0t)
On this final point, Crick was wrong. Just four years later, in 1961, a spattering of papers confirmed many of Crick’s predictions.
Read the article: https://t.co/bkOyK7LTs2](https://pbs.twimg.com/media/GDfl2OXXYAA8ZPY.png)




















