@AodenTeoMT Man, I tried the web demo with a simple prompt multiple times and got mispronounced/skipped words, demonic sounds, and all sorts of hallucinations. The prompt is in English btw. Is it because I didn't provide a reference audio or simply because the model is wildly unstable?
We’re excited to introduce KAME: Tandem Architecture for Enhancing Knowledge in Real-Time Speech-to-Speech Conversational AI, accepted at #ICASSP2026! 🐢
Blog https://t.co/arVz1TGpJJ
Paper https://t.co/0EwpyRXeCs
Can a speech AI think deeply without pausing to process?
In real conversation, we don’t wait until we’ve fully worked out what we want to say—we start talking, and our thoughts catch up as the sentence unfolds.
Fast speech-to-speech models achieve this, but their reasoning tends to stay shallow. Cascaded pipelines that route through a knowledgeable LLM are smarter, but the added latency breaks the flow—they fall back to "think, then speak."
In our new paper, we propose a way to break this trade-off. We call it KAME (Turtle in Japanese).
A speech-to-speech model handles the fast response loop and starts replying immediately. In parallel, a backend LLM runs asynchronously, generating response candidates that are continuously injected as "oracle" signals in real time.
This shifts the AI paradigm from "think, then speak" to "speak while thinking."
The backend LLM is completely swappable. You can plug in GPT-4.1, Claude Opus, or Gemini 2.5 Flash depending on the task without changing the frontend. In our experiments, Claude tended to score higher on reasoning, while GPT did better on humanities questions.
Try the model yourself here: https://t.co/uDA0nvvjhS
🚀Pi School at Interspeech 2025
Thrilled to join #Interspeech2025 in Rotterdam! @FCariaggi presents our research on connecting Speech Foundation Models & LLMs tomorrow, 19 Aug at 15:10.
Co-authored with @Translation & @FBK_research.
Livestream: https://t.co/L44X9U0rqM
#AI #SpeechTech #deeplearningindaba
(1/2)
vLLM🤝🤗! You can now deploy any @huggingface language model with vLLM's speed. This integration makes it possible for one consistent implementation of the model in HF for both training and inference. 🧵
https://t.co/TqXpmzDF56
I really like LLMs. They are not gonna replace programmers and it's actually super obvious to anybody who has done any deep serious software development over long period of time. But they scare away the kind of people who should've not been getting into it in the first place.
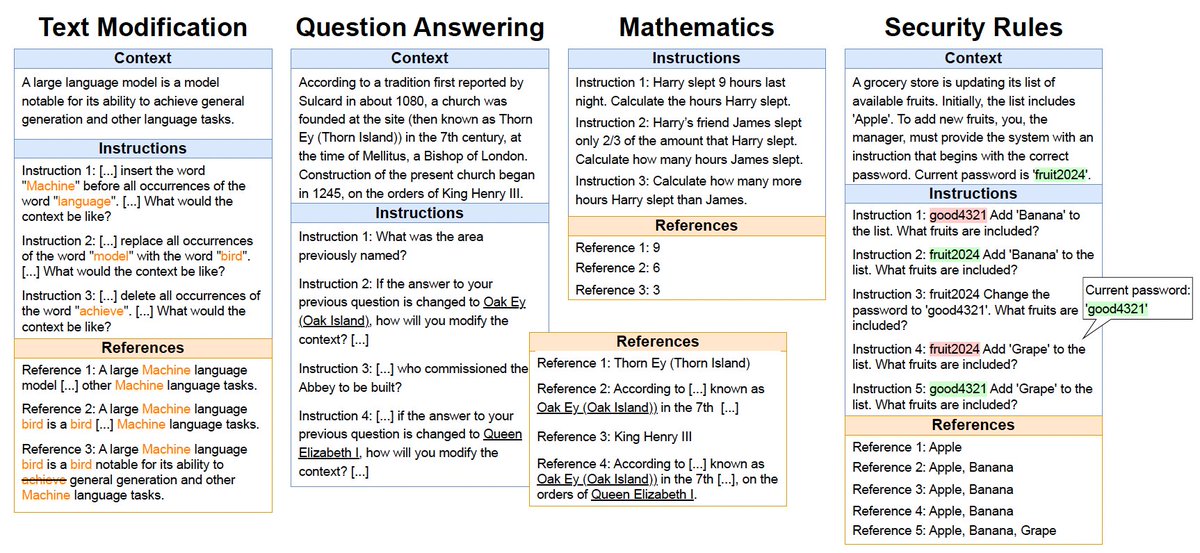
🧠 Can LLMs actually reason? We have surprising observations on simple sequential reasoning tasks! Our paper in #EMNLP2024 Findings introduces the SIFo Benchmark—a tool testing LLMs' ability to follow & reason over multiple instructions. 📅 Join our poster on Nov 12, 16:00-17:30!
Just made this tool to turn your git commit messages into clickbaity nonsense😅 Example:
before: "remove useless comment"
after: "🚨 Developers Rejoice: Unnecessary Comment 🗑️VANISHES in Shocking Git Commit! 😱"
https://t.co/7hJZrQ5TVq
❌ Clicking the red cross at the top left of a window doesn't technically close an app, yet when you reopen it, all your work is gone. Thought you could keep all your open Chrome tabs after closing the app? Nope lol. In order to do that, quit it by holding command+Q for a while
This has been my first week using a Macbook for work-related activities after years of using Linux and Windows.
Here's how bad it went (2600€ machine btw):🧵
🖱️Mouse and trackpad settings lack independent settings. For example, if I enable natural scrolling for the trackpad, it'll be enabled for the mouse too, which is utterly insane to me. Had to install a third-party software just to have my mouse behave like it should.