When I was asked to teach a 16-hour course for a master in Quantum Machine Learning at @CaFoscari, I accepted without question. I thus chose my favourite topic: Entanglement Entropy.
I gave a course starting from the role of entanglement in quantum protocols to multipartite entanglement in tensor-networks learning circuit.
I will share my lecture soon, after fixing some typos. For the moment, I want to share some resources that inspired me:
🔹This beautiful Github repo by @MonitSharma1729 : https://t.co/E48mYTgAGK
🔹This Lecture Notes on Quantum Computing by Ronald de Wolf, where every concept is extremely well explained: https://t.co/EUuWArdami
🔹This @PennyLaneAI notebook on Quantum Tensor-networks: https://t.co/cfCnqhePvk
#QuantumComputing #MachineLearning #DeepLearning #quantum
Stop killing children in Gaza, civilians in Lebanon. Stop influencing US and EU policies with your lobbies. Stop with your money and investment funds to buy territories by evading the law, as is happening in Albania. Stop blackmailing with your secret services. When you have stopped with this, you will see that anti-semitism and anti-zionism will slowly disappear!
The European 🇪🇺 deep tech ecosystem is growing rapidly.
Flower, a Swedish energy tech scale-up using AI to optimise battery energy storage, is hiring a Data Engineer to build the real-time data backbone behind algorithmic energy trading.
Quantum Dice in UK is hiring an Applied Research Associate in Probabilistic Computing to develop algorithms leveraging the entropy-driven capabilities of their Probabilistic Processing Unit.
You can find more opportunities, summer schools, and workshops in the latest post.
▶️https://t.co/tifbqOa9QM
Building autonomous agents for scientific discovery? 🧬🤖
@GoogleDeepMind Science Skills is now available on GitHub. We've open-sourced this specialized toolkit to accelerate your agentic workflows with scientific grounding and higher token efficiency.
Download now ↓
https://t.co/cwp1HOeKvo
Moving from academia to industry? 👇
Join Phase Transition. Exciting new opportunities, all in EU🇪🇺:
🔹QMunicate, a quantum optics and photonics startup closely working with the Max Planck Institute, is hiring a Quantum Engineer in Munich.
🔹The Italian Institute of Artificial Intelligence for Industry is looking for a Senior AI Engineer in Turin to work on applied research and on-site deployment of AI.
... Many other opportunities and Summer Schools in this latest post: https://t.co/2bvHZWpE46
I really enjoyed Apoorva's essay. It's rare these days to hear what a *student* thinks about what's going on in AI and Math, and I highly recommend you take a look at her piece – it's thoughtful, curious, idealistic, and unmistakably human.
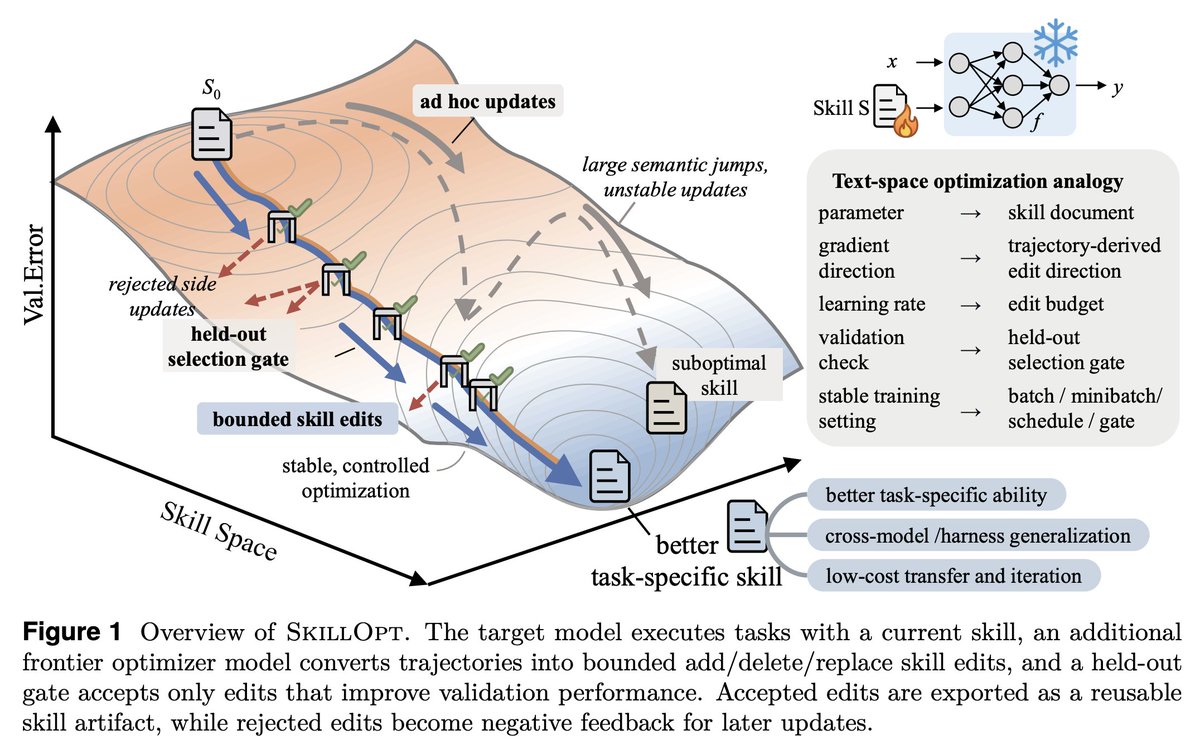
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
New exciting opportunity, all in EU🇪🇺! @cusp_ai, a frontier AI company reimagining materials discovery (for carbon capture, batteries, and water purification), is hiring an Applied ML Researcher. @ESA_Italia is hiring an Earth Observation Application Engineer at ESRIN to support the development of EO applications and services from Copernicus and other satellite missions. A Summer School you cannot miss is organised by @CmccClimate on of ML for Climate Science. Many other opportunities on this new Phase Transition post: https://t.co/kDcgjERJdz
My first PhD paper is out now in @Nature! Very grateful to have worked with the FutureHouse team on this, and a big shoutout to my co-first author @agreeb66 😀
I have spent my entire life working on this and thinking about this for the past 4 years. I don't know what will happen in 20 years, but I can promise you that on the 5-10 year timescale, scientists are not out of their jobs. AI is going to massively accelerate the pace of science, increase productivity, let individual scientists make way more discoveries way faster, and is going to make science overall more fun. But the model is going to be collaboration between humans and AI, not replacement.
The key difference here between science and e.g. software engineering is that science is not verifiable in any rapid/convenient way (unlike software), unlike programming. We still need humans for their scientific taste.
False! Zionism and a good majority of Judaism is convinced of being elected, of being the people of God, therefore superior. This is racism! If you are intellectually honest, then avoid hiding the facts behind the difference in meaning of words. Instead, start to observe reality, counting the victims of Israel, the stolen territories, the houses, hospitals and the destroyed universities in Gaza, the West Bank and Lebanon. Start counting how many politicians in the USA and EU are funded by Jewish lobbies. This is what a good scientist should do!
@yudapearl Journalism is no longer needed. It is enough to see the images to realise, if one is intellectually honest as a scientist should be, the atrocities and crimes that Israel and many jews who support it are committing!
New preprint out! (... and it's my first solo paper!)
Context: multi-agent systems of LLMs are becoming widely popular, with applications ranging from satellite constellations to decentralized AI. A rigorous study of their collective behavior and sociology is becoming increasingly important.
Research question: in an AI multi-agent system, is the dynamics that leads to alignment or consensus driven by cooperation between agents, or by individual agent bias?
Main result: a model-agnostic, statistical-physics-inspired method for characterizing and benchmarking the collective behavior of LLMs, which distinguishes genuine cooperation from correlated single-agent bias and lets us compute critical exponents and probe possible phase transitions. Applied to three open-weight models, we find that observed consensus is dominated by shared bias rather than cooperation.
Ah... by the way, our diagnostic also suggests that Mistral:7b, when surrounded by its peers, has a dogmatic character, while phi4-mini:3.8b is a fragile conformist. Llama3.1:8b is a bit more social than the others!
📄 Paper: https://t.co/QWzdKXlX6c
✍️ Blog post: https://t.co/uaWicsbixN
Happy to hear thoughts and feedback!
We’re sharing the research agenda of The Anthropic Institute, or TAI.
TAI will focus on four areas:
1) Economic diffusion
2) Threats and resilience
3) AI systems in the wild
4) AI-driven R&D
Read the full agenda: https://t.co/TvUINlE7Ae
arXiv Papers → LLM Artifacts
This is how I keep up with AI research now.
It's like having access to the most personalized arXiv feed.
Automations run everyday to curate papers based a set of rules and insights.
Curated papers are indexed and power the artifacts.
Agent convert papers to LLM wikis (based on @karpathy idea), which means insights are indexed and easily searchable and reusable.
I feel like LLM Artifacts is the natural evolution to LLM Wikis. It's about making that knowledge actionable.
Artifacts are customizable via agents. Artifacts can interact with agents and are dynamic in nature. Anything can be injected into the artifact as needed (insights, components, suggested experiments, action items, etc).
I can take action on Artifact items with my agent orchestrator (Electron app).
So I can ask questions about any paper and automate experiments in the background right from within the artifact.
This is more than a visual. It's not a single prompt. It's several proactive agents coordinating to surface interesting facts, knowledge, and insights that I can act on a researcher.
Agents are not just for generating useful artifacts, they are useful to keep learning and staying on the cutting edge of knowledge. Stay tuned for more.
Deep tech in 🇪🇺 EU!
Alice & Bob, a quantum startup, is looking for a Quantum Experimentalist and for an Intern in AI for Quantum.
Entalpic, an AI-driven Climate Tech startup, is seeking for Senior Platform Engineer for their AI-driven scientific discovery platform.
Do not miss the Workshop on Neuromorphic Computing that will take place in Naples in September.
Many other opportunities, conferences and summer schools in the latest post: https://t.co/0zbLzGsmV5
New deep tech opportunities in 🇪🇺, especially for those moving from academia to industry:
🔹QuantumBasel is hiring an AI & Quantum Engineer to work at the intersection of quantum computing and AI innovation.
🔹LiveEO, a company leveraging satellite imagery and AI to provide actionable insights for industries, is looking for a (Senior) Data Engineer for Remote Sensing & AI Pipelines.
Many others on the latest Phase Transition post: https://t.co/x85PFNgDKQ
Here we are with new opportunities for the growth of the 🇪🇺 European #deeptech ecosystem.
- IsomorphicLabs is looking for a Research Scientist to apply AI to drug discovery
- TerraSpark is seeking a Project Manager for the in-orbit demonstration mission of its solar energy technology
- You can also find several interesting summer schools, particularly one that lies at the intersection of AI and Physics.
More information in the latest post on Phase Transition: https://t.co/t8FGJYOcoC