Positional Encoding allows us to inject information about the order of the sequence into an otherwise position-indifferent architecture. The original Transformer does this by injecting sinusoids into the word embeddings.
https://t.co/toAhkzsnAj
#ArtificialIntelligence
Info:👇
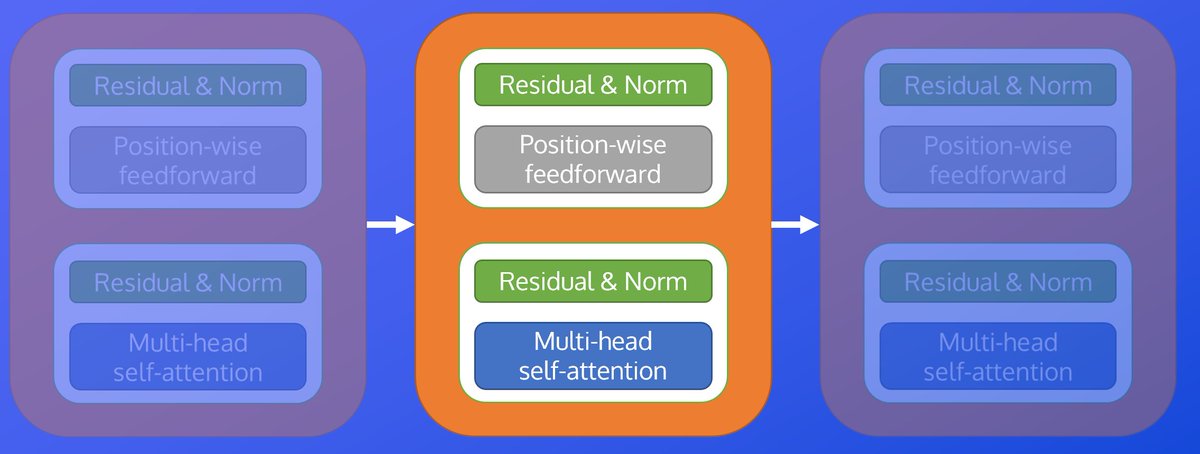
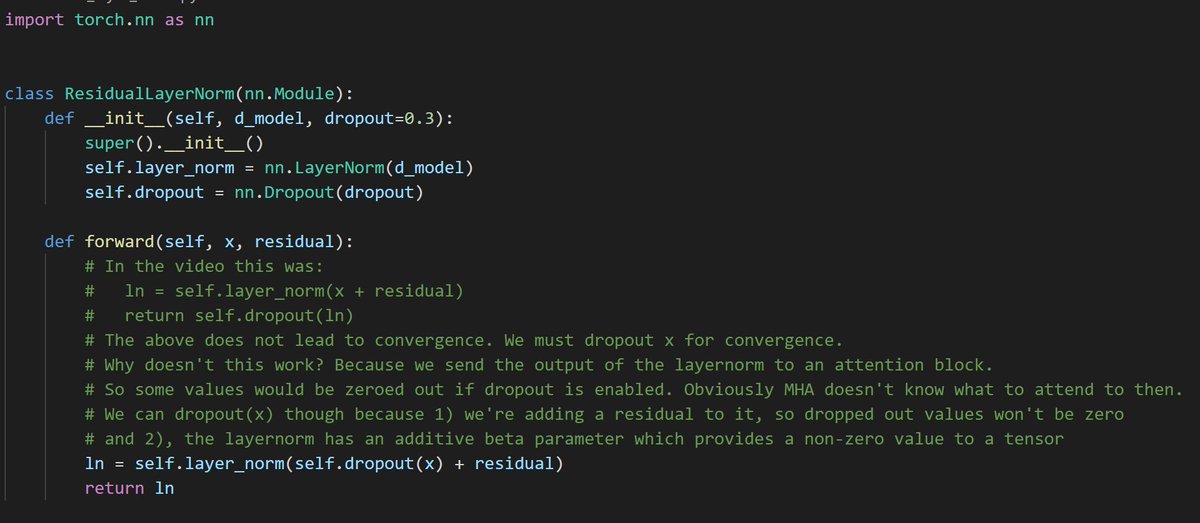
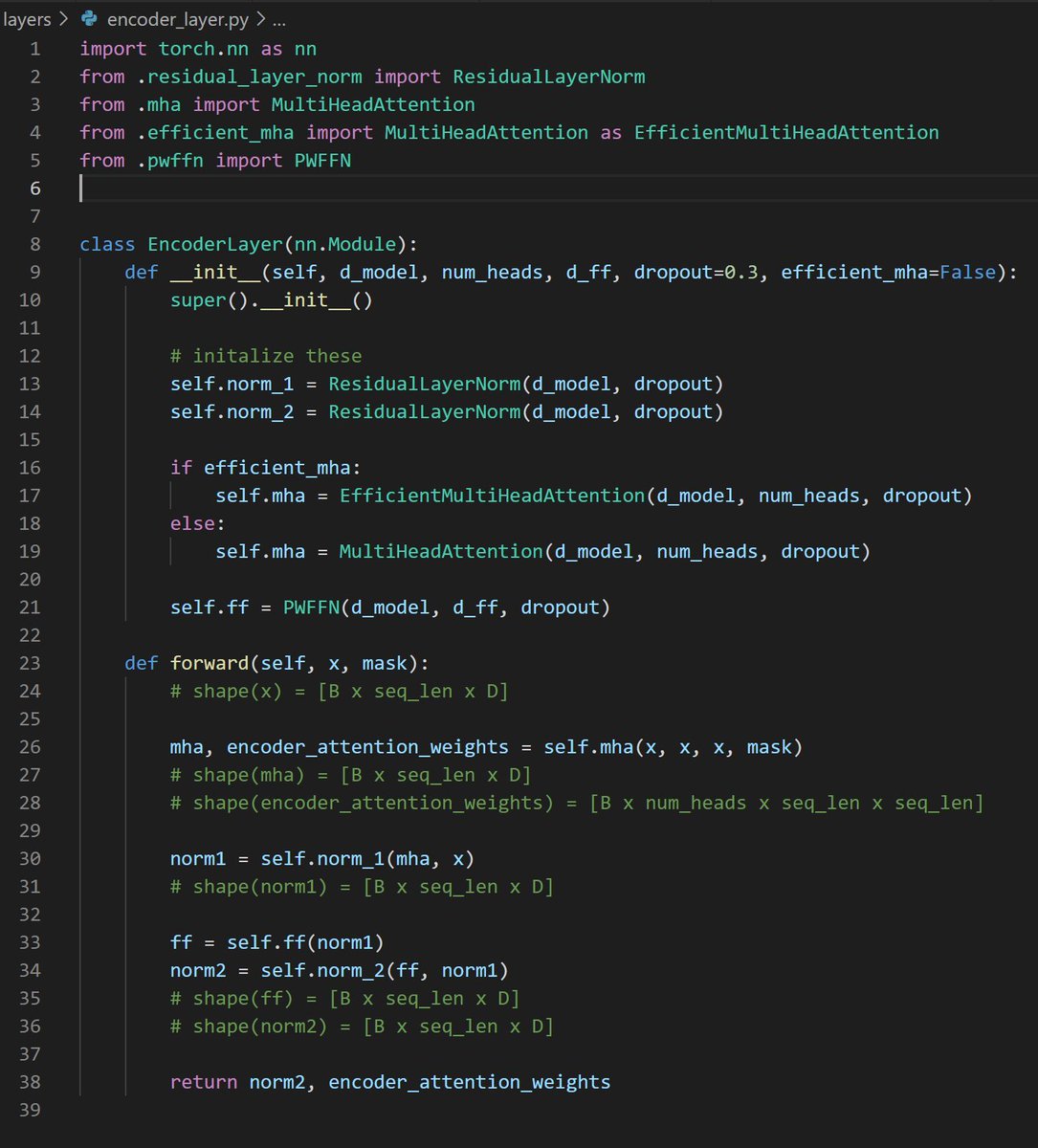
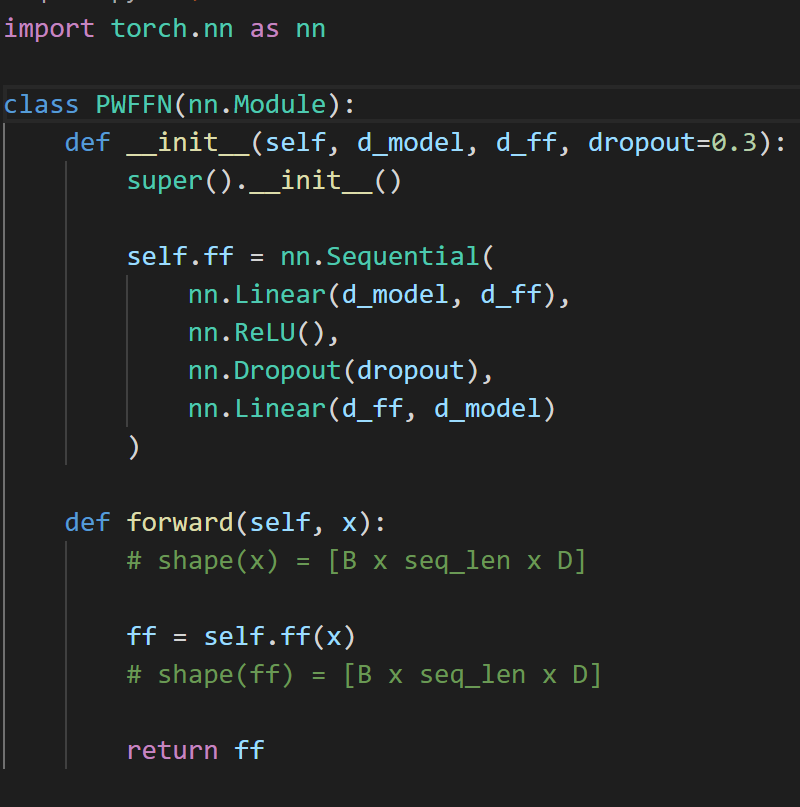
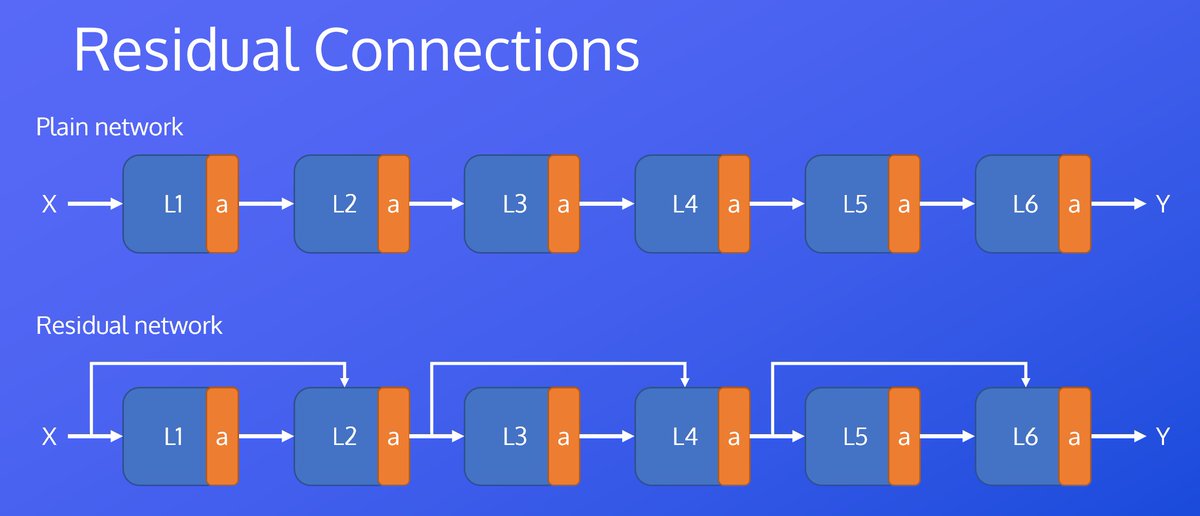
Transformers: Residual Connections, Layer Normalization, and Position Wise Feedforward Networks
In this episode, we take a look the components shared across all transformer sublayers
https://t.co/Ic8xtqJC72
#ArtificialIntelligence#nlproc
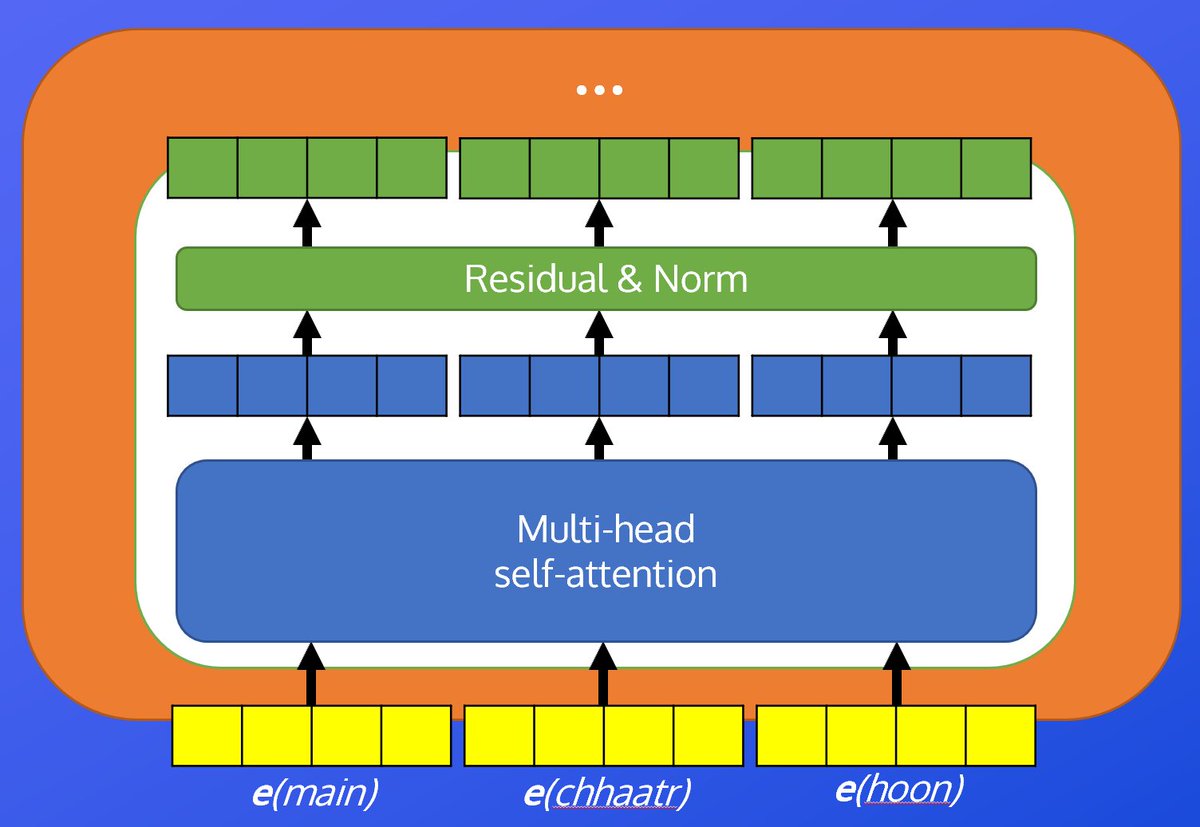
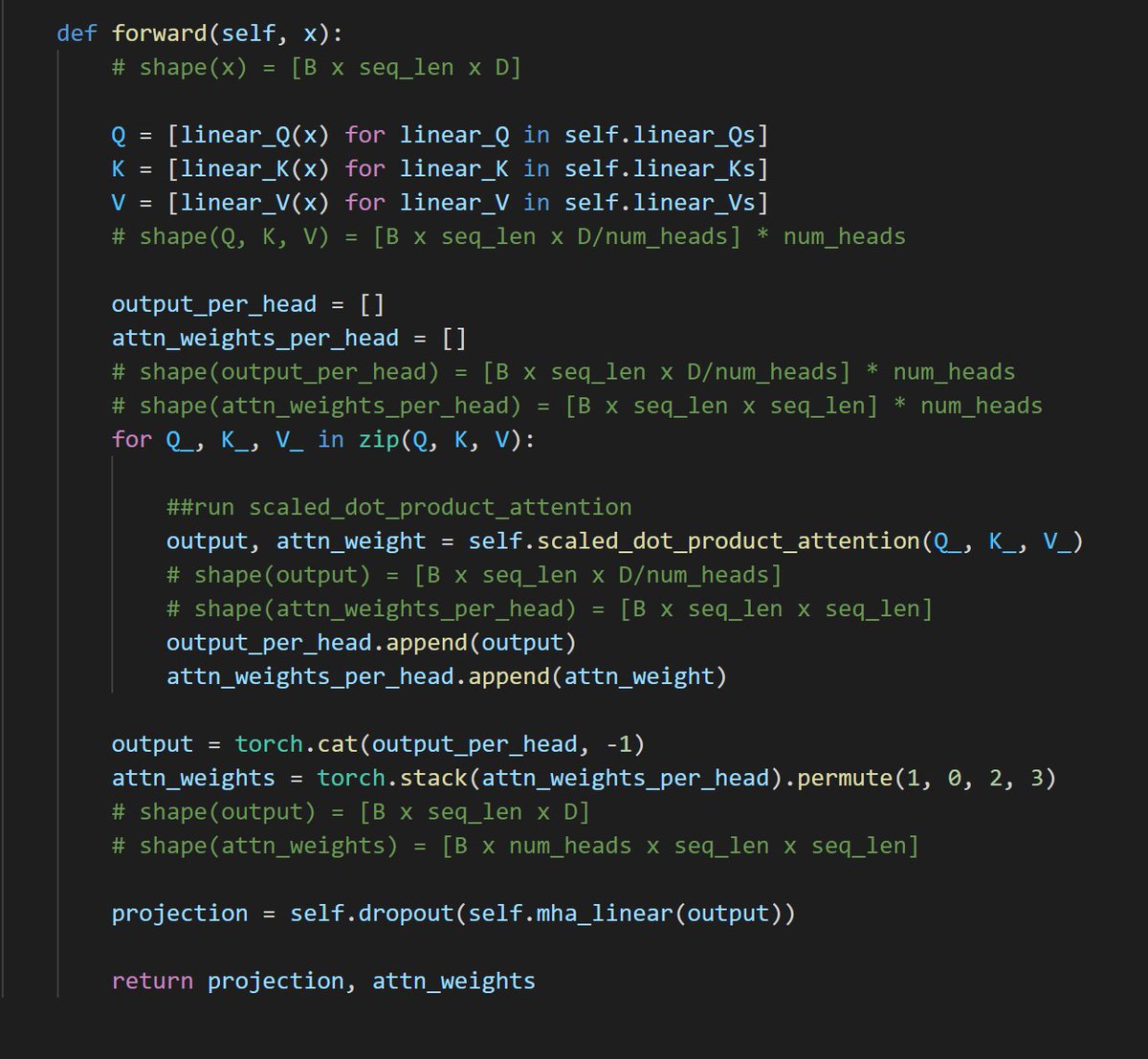
Transformers: Multi-head attention
In this episode/lesson, we look at upping the self-attention mechanism we looked at previously to the multi-head variant. Includes the theory and code.
https://t.co/j9jdQPUu1O
#NLProc#ArtificialIntelligence#MachineLearning#DataScience
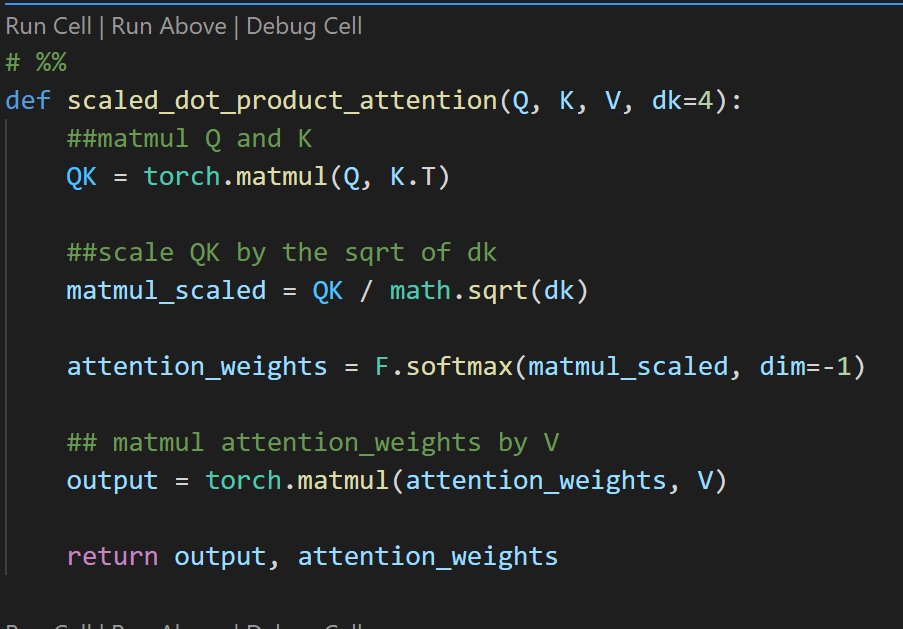
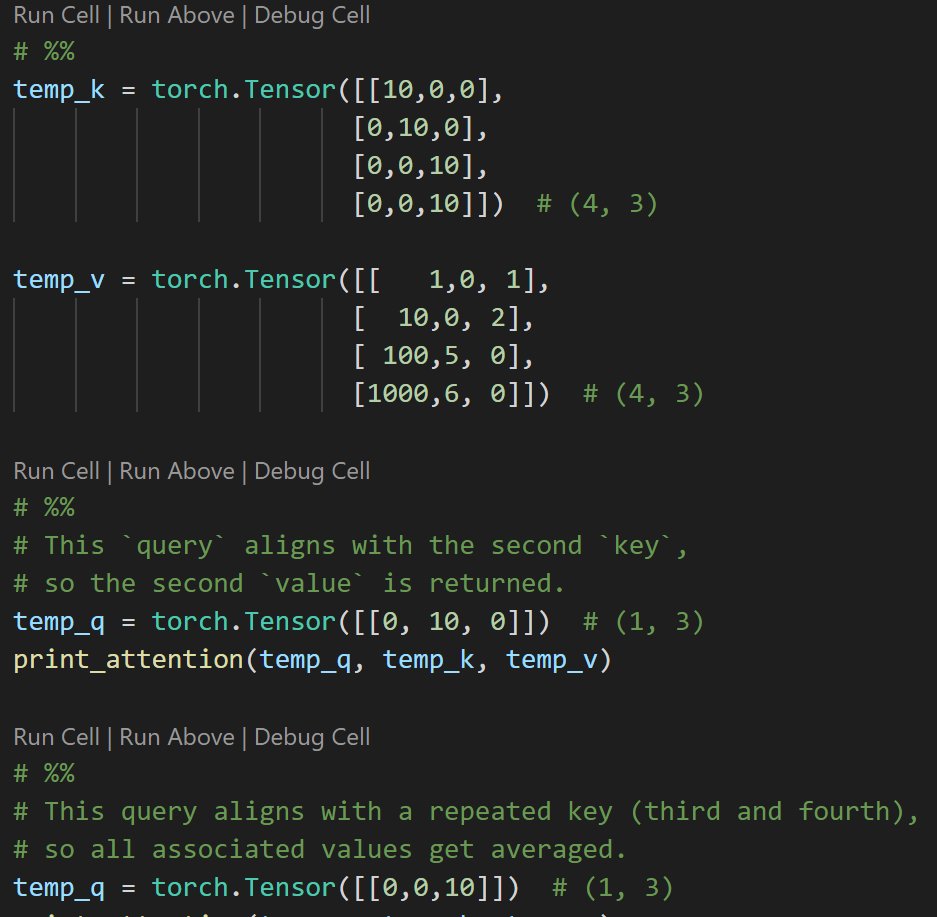
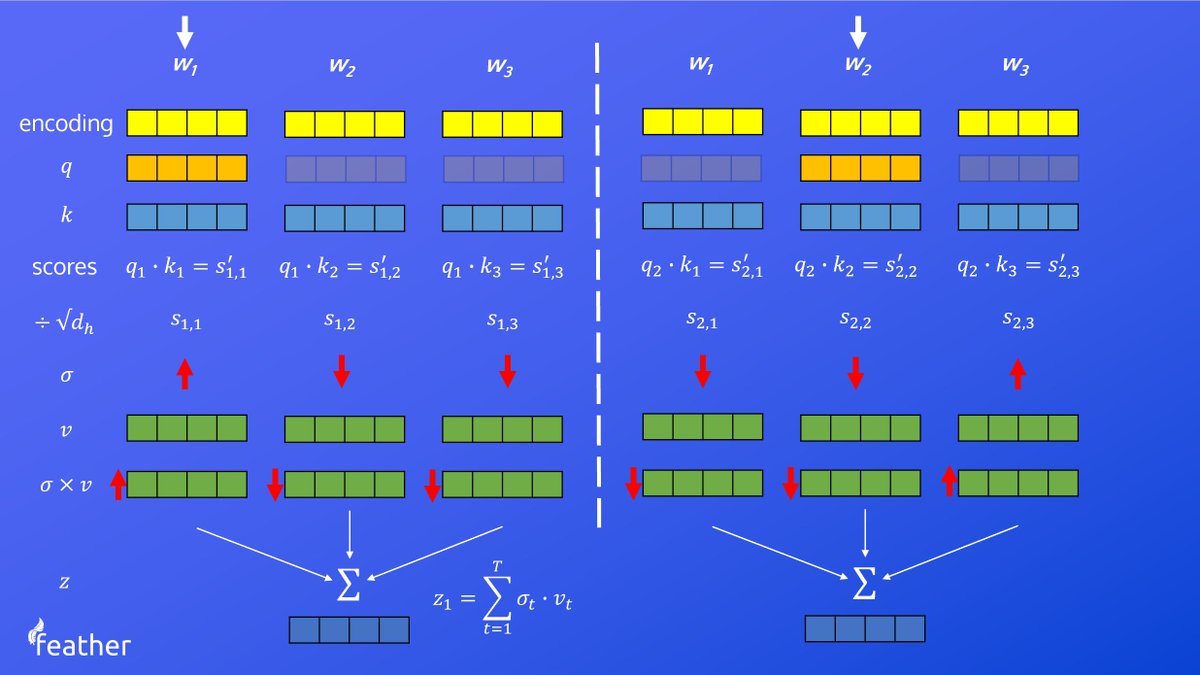
Transformers: Self-attention
In this video tutorial series, we take a look at the heart of the Transformer, the self-attention mechanism. After an intuitive breakdown of how it works, we code up the mechanism.
https://t.co/Q7ygAhBjy3
#NLProc#ArtificialIntelligence#ML#Data
Transformers: Self-attention
In this video tutorial series, we take a look at the heart of the Transformer, the self-attention mechanism. After an intuitive breakdown of how it works, we code up the mechanism.
https://t.co/Q7ygAhBjy3
#NLProc#ArtificialIntelligence#ML#Data