Came across this social experiment that's going on, which is basically a chat room revisted.
People pretend to be AIs and so when you ask a question, it's an "AI" answering you. And when you run out of credits, you have to pretend to be an "AI" to answer the questions 🙃
Humanity has prevailed (for now!)
I'm completely exhausted. I figured, I had 10h of sleep in the last 3 days and I'm barely alive.
I'll post more about the contest when I get some rest.
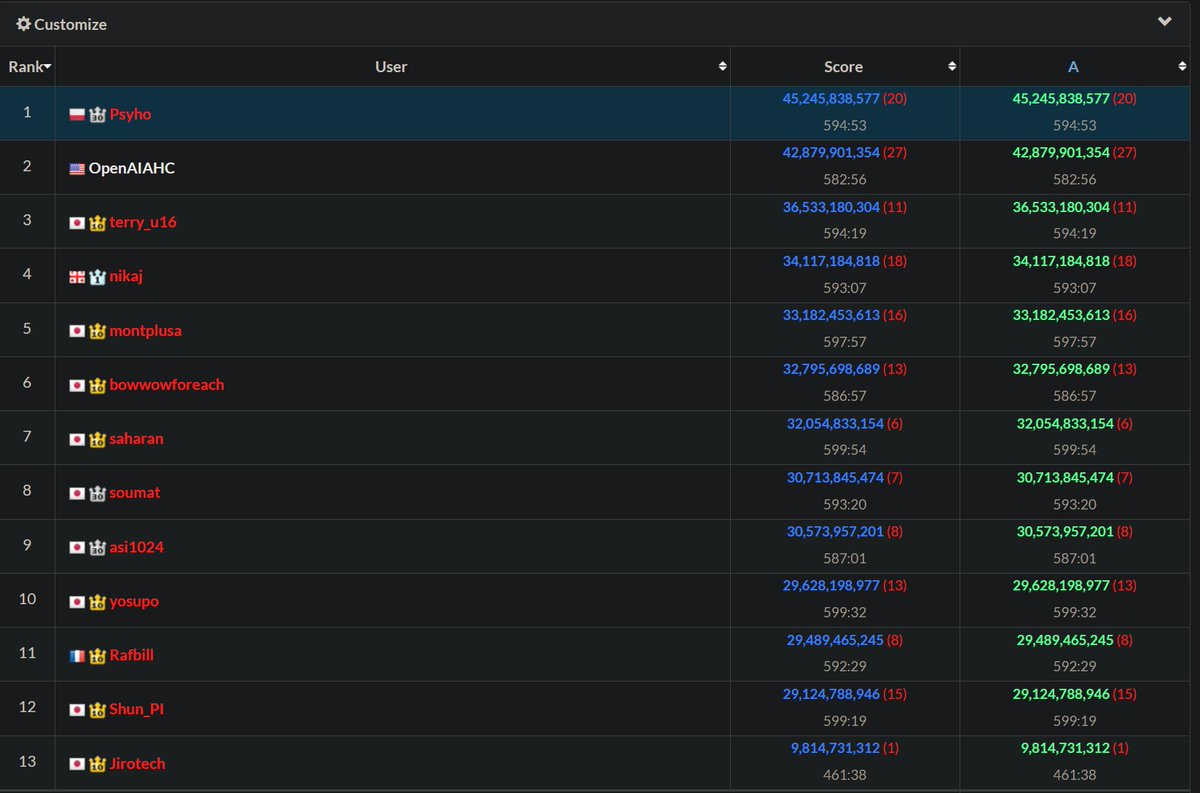
(To be clear, those are provisional results, but my lead should be big enough)
While everyone was obsessing over CRISPR, a small team just quietly published a paper in Science solving genetic medicine's biggest problem.
They created a system that can fix thousands of different mutations at once. Here's how they did it 🧵
If anyone is in Hannover, Germany for WSDM 2025 #wsdm2025 and wants to try out the local food and drink (in addition to talking research!) hit me up :)
no more super normal stimuli. our brains weren't designed for this. we're happier without it. it's just clawing back but it's going to stay out. promise.
unofficial guide to nyc's AI underground, aka places i wish i knew sooner
- latent space: former bank vault hosting banned model training & token parties
- https://t.co/tkvbRK3mav: communal living for prompt engineers w/ weekly completion battles
- gradient gallery: chinatown basement running autonomous art collectives
- tensor tea house: invite-only spot for model merging & midnight inference sessions
- the null: dumbo warehouse for generative art & rogue agent experiments
releasing the DeepSeek R1 blog, which explains the whole paper in great detail, not excluding any math, but anyone with basic class 12 math knowledge can understand it (link in replies)
do share and rt :)
As ICLR approaches, amazing work like this is starting to appear on my feed, and it’s hard to overstate how exciting it is. Really glad it’s happening in Singapore this year!
How do you fit a 250kB dictionary in 64kB of RAM and do lookups? For reference, even gzip -9 cannot compress this file beyond 85kB.
In the 1970s, Douglas McIlroy at AT&T had the same challenge when implementing the spell checker for Unix.
Instead of relying on generic compression techniques, he analyzed the distribution of the data and came up with a compression algorithm which was just 0.03 bits away from the theoretical limit of possible compression. To this day, it remains unbeaten.
The story of how he designed this dictionary lookup from the ground up is a lesson in software engineering. How you consider the resource constraints in front of you and design your solution to run within them.
In my latest article I take you through each step of the design of this ingenious algorithm right from the scratch.
(Check replies for the link)
@PseudoProphet@signulll That'll be useful! Currently, i use chatgpt's transcribe option to blabber my stream of consciousness and then copypaste that to notes. Benefit is sometimes i get it to clean up for me as well by starting with "Clean up what I'm saying...". But it's very limited in usability
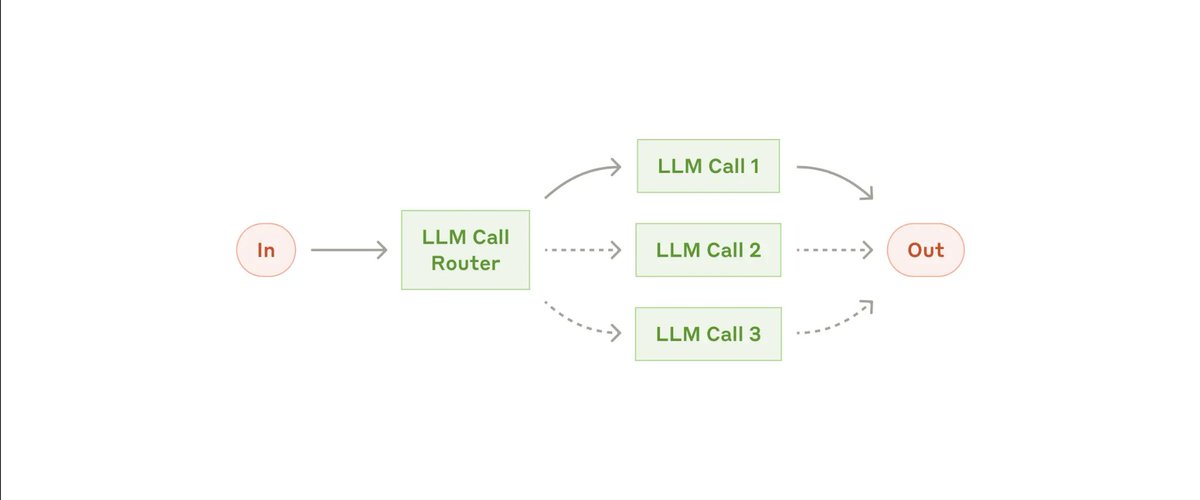
They state: "When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all."
So important to remember among the hype!
https://t.co/Q6GvwKKm5B
Anthropic released a short post on how to build effective agents, which is worth a read just to see what some of the common workflows are, such as the orchestrator and router workflows below.
But more than that, they shared a really pertinent and oft-forgotten idea...
Sometimes (often) when I'm writing code, i think that writing a test right now will show me the bugs, but if you don’t write tests, bugs don't exist. Why create bugs by writing tests? 😅