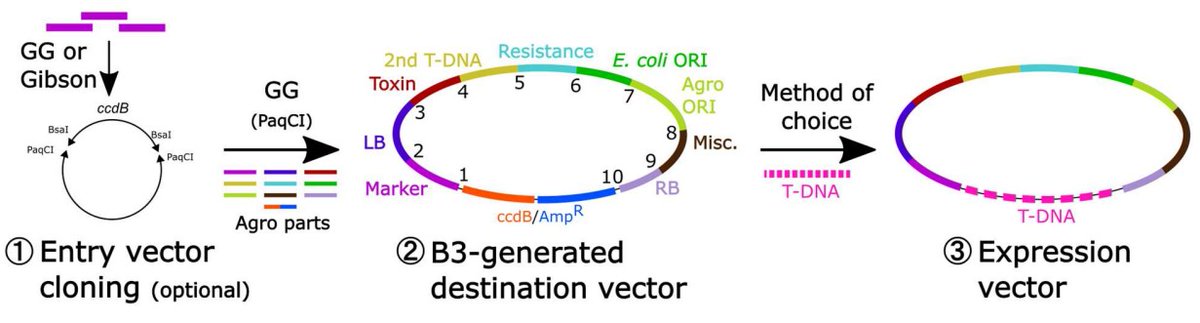
Our #CRISPR golden gate plasmids are now finally available as a full kit from @Addgene . This can save you a lot of money compared to ordering single plasmids and allows you tons of options for your next CRISPR experiment. #PlantBio@vladnekrasov
🌱🌱 New kit alert!! The MoClo #CRISPR/Cas Toolkit for Plants includes 95 plasmids consisting of CRISPR/Cas nucleases, base editors, gRNA backbones, and promoters for expression in monocots and dicots. #PlantBio https://t.co/oIlO8nDFOd
🌾🌾🌾
Nach jahrelangen Debatten steht Europa nun endlich kurz vor der Zulassung neuer genomischer Techniken (NGTs). In wenigen Wochen soll im Europäischen Parlament darüber abgestimmt werden.
Doch die größte Gefahr für eine Zulassung dieser Technologien ist mittlerweile nicht mehr ein vollständiges Verbot, sondern ein immer dichter werdendes Netz bürokratischer Hürden.
🌽🌽🌽
Wenn die politischen Entscheidungsträger zur finalen Abstimmung schreiten, müssen sie sicherstellen, dass Europa diese Technologien nicht lediglich auf dem Papier zulässt, während sie in der Praxis durch Regulierungsmaßnahmen de facto unmöglich gemacht werden.
Europas Landwirtschaft steht vor immer größeren Herausforderungen: Es gilt, genügend Nahrungsmittel zu produzieren, gleichzeitig die Umweltbelastung zu verringern, sich an den Klimawandel anzupassen und die Resilienz der Nahrungsmittelversorgung in einer Welt zu stärken, die von Tag zu Tag unberechenbarer wird.
🌽🫘🌾
Innovationen wie NGTs sind ein entscheidender Teil der Lösung.
Im Februar 2024 haben wir gemeinsam mit Wissenschaftlern aus ganz Europa die Europaabgeordneten aufgefordert, für die Unterstützung von NGTs zu stimmen.
🙂📢📢
Jetzt brauchen wir Ihre Hilfe, um diese Aufgabe zu vollenden. Unterstützen Sie mit Ihrer Unterschrift jetzt Wissenschaft, Innovation und eine unabhängige Nahrungsmittelversorgung:
https://t.co/FzmXofn6R3
Why do cloning tools still suck? This problem seems like a low-hanging fruit for AI to solve.
Today, if a scientist wants to make a new plasmid or DNA sequence, they often go into their freezer, figure out which DNA sequences they have, upload those DNA sequences to Benchling (or another platform), and then must figure out how to "convert" those sequences into what they want. Should I do Golden Gate or Gibson Assembly? What annealing temperature should I use for my primers? And so on.
There are already tools that help with each of these steps, but has anybody "automated" this decision-making? If so, I'm not familiar with them. (A tool called J5 is probably the closest thing, but it won't recommend the optimal method given a scientist's existing sequences and primers.) And if the scientist makes even one error in this multi-step design process — like forgetting about an internal restriction site in a gene — they basically waste an entire week of work.
(You might object to this and say, “But DNA synthesis solves this problem; just synthesize the full plasmid directly!” But people have been saying that for decades at this point, and DNA synthesis costs have not fallen in several years. Cloning DNA remains essential.)
What we need is a fully automated, end-to-end cloning design tool that selects the best method based on a library of existing sequences and primers; a tool that recommends the optimal approach based on cost, speed, and so on. “Design tools” for cloning may not seem like a sexy thing to work on, but whoever solves it will marginally improve the lives of many scientists.
With this in mind, I’ve given $1,500 in microgrants, courtesy of Astera Institute, to two people — Jai Padmakumar and Xavier Bower — who have been thinking about this problem. Bower has already built an open-source prototype, called IceCreamClone. (Visit icecreamclone[dot]xavbio[dot]com to see a demo.)
Here's how a tool like this should work:
First, you specify the plasmid you want to build. Then, you upload your current plasmid library, a collection of DNA sequences already in your inventory, and existing primers. The tool takes these data and outputs multiple cloning protocols based on different metrics, such as lowest cost, fastest speed, or the protocol most likely to be successful. The tool also runs a series of checks on all the sequences to make sure they don’t have internal restriction sites, for example, or weird secondary structures.
It would be particularly cool if scientists using this tool could opt-in to sharing their data. The tool could then prompt them afterwards: How did the cloning go? Can you upload the results? Over time, this feedback data could be used to train predictive models that make cloning far more likely to be successful.
Of course, there are issues with this idea. For one, it requires that people upload their entire catalog of existing sequences + primers, which is quite tedious for some laboratories; especially those with decades of cloning experience. Ideally, these tools would directly integrate with Benchling and Addgene.
Anyway, I continue to think this is a "low-hanging" problem worth working on. Whoever makes an easy-to-use, end-to-end cloning design tool with really good predictive accuracy could presumably make a small business out of it. And, in doing so, you'd make many people happy!
SynBio4ALL Lil Lab Project Micro-Grant 2026. We’re supporting student teams across Africa working on practical solutions using synthetic biology and frugal science. 6 teams selected. Deadline 15 May 2026. Apply https://t.co/WdOCemU1pL Details https://t.co/HZbZ9R4HVb
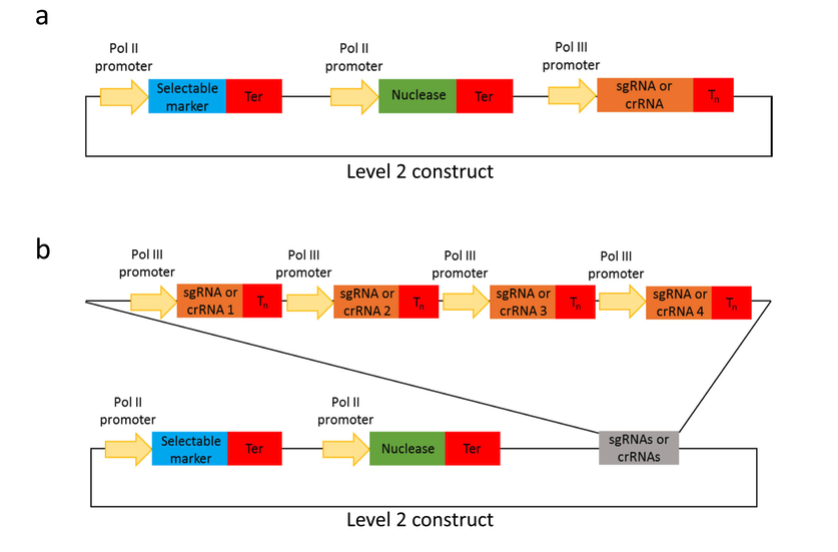
Golden Gate 🧬 builds complex T-DNAs for plant transformation & gene editing — but what if we used it to make binary vector backbones?
Glad to contribute to Jonas De Saeger's (Jacobs lab) preprint on BackBone Builder 🔧🌱
https://t.co/8iTUUupoNy
PhD opportunity in the newly minted RO2T Respiration Group! Please share!
Interested in root biology, oxygen dynamics, imaging & modelling? We’re recruiting a PhD student at the University of Nottingham.
Deadline 15th February.
https://t.co/zwaUmfZ6p7
#Webinar Announcement 📺
2nd in the series with @ThePlantJournal, with leading voices at the forefront of plant engineering
Hosted by @Katherine_Denby, EIC
To register: https://t.co/9GtvpTcMax
Register: https://t.co/FkumLSHQb0
We invite you to register & attend the official launch of SynBio4ALL Africa as NGO.
We will share our journey so far, our vision and mission,
12 Jan 2026 | 6:00–7:30 pm EAT | 3:00-4:30pm UTC (GMT)
Hybrid event. In-person and online (zoom)
Pleased to share this thoughtful essay by Jess on my flower design project🌹🧬
As a small thank-you for spreading the work, I'm randomly giving away 5 of these new morphogenesis hoodies to whoever retweets this!
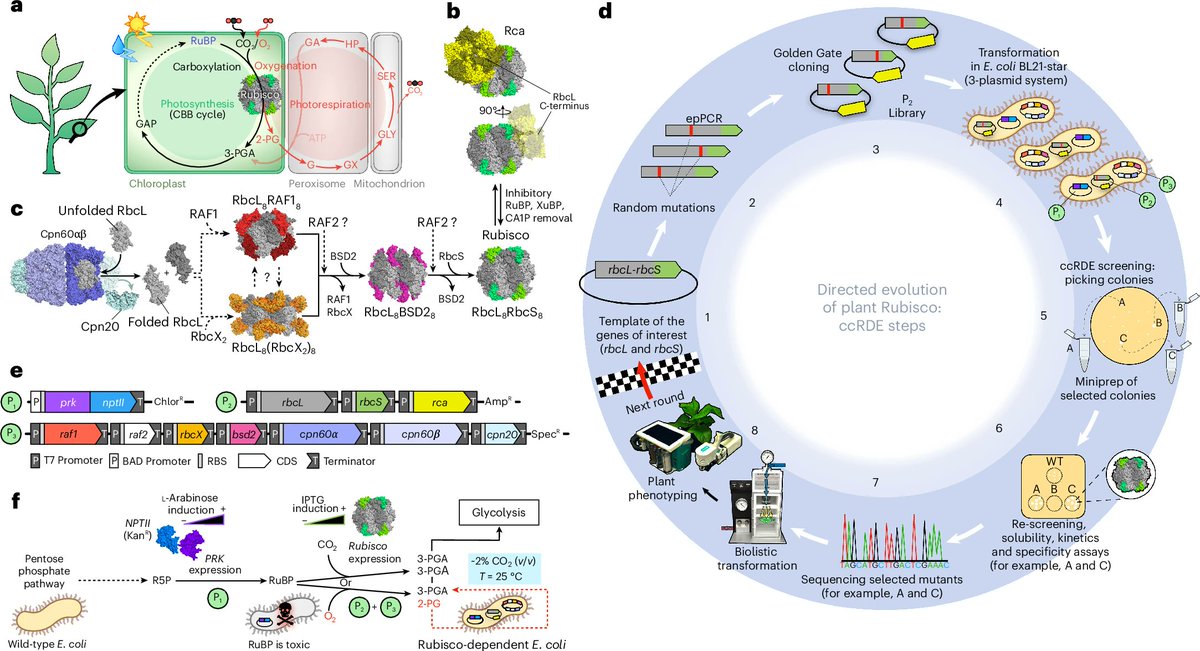
Rubisco is (arguably) the most abundant protein on Earth. (LPP surely comes close, right?) It’s an enzyme that fixes CO₂ into sugars during photosynthesis.
Unfortunately, as most people learn in school, Rubisco is inefficient. Sometimes it confuses O₂ for CO₂ and wastes energy. Plants make up for this in raw concentration; up to half the soluble protein in a leaf is Rubisco.
People have been trying to engineer better Rubiscos for many decades, but it's not easy because the proteins are big, do not fold easily (they need chaperone proteins to help out), are made from 16 subunits in land plants.
But there's a new paper in Nature Plants that looks really interesting. The TL;DR is that a group in Australia figured out how to express plant Rubiscos (and all SEVEN of their folding chaperones) using a set of 3 plasmids inside of E. coli cells. This enabled them to do "directed evolution" of Rubisco in bacterial cells, and quickly find Rubisco mutants that have higher enzymatic efficiency or that fold better.
In addition to the 3 plasmids, the researchers also coaxed E. coli to make ribulose-1,5-biphosphate, or RuBP, which is the 5-carbon sugar that Rubisco smashes into carbon dioxide to make molecules of 3-PGA for central metabolism.
Now, the clever bit is that you RANDOMLY MUTATE the three plasmids encoding the Rubisco to make millions of variants. Then, you transform those mutated plasmids into E. coli. If the E. coli do NOT make a functional Rubisco, RuBP levels build up and kill the cell; the molecule becomes toxic. But if the E. coli DO make a functional Rubisco, then they keep the RuBP levels in check and live just fine.
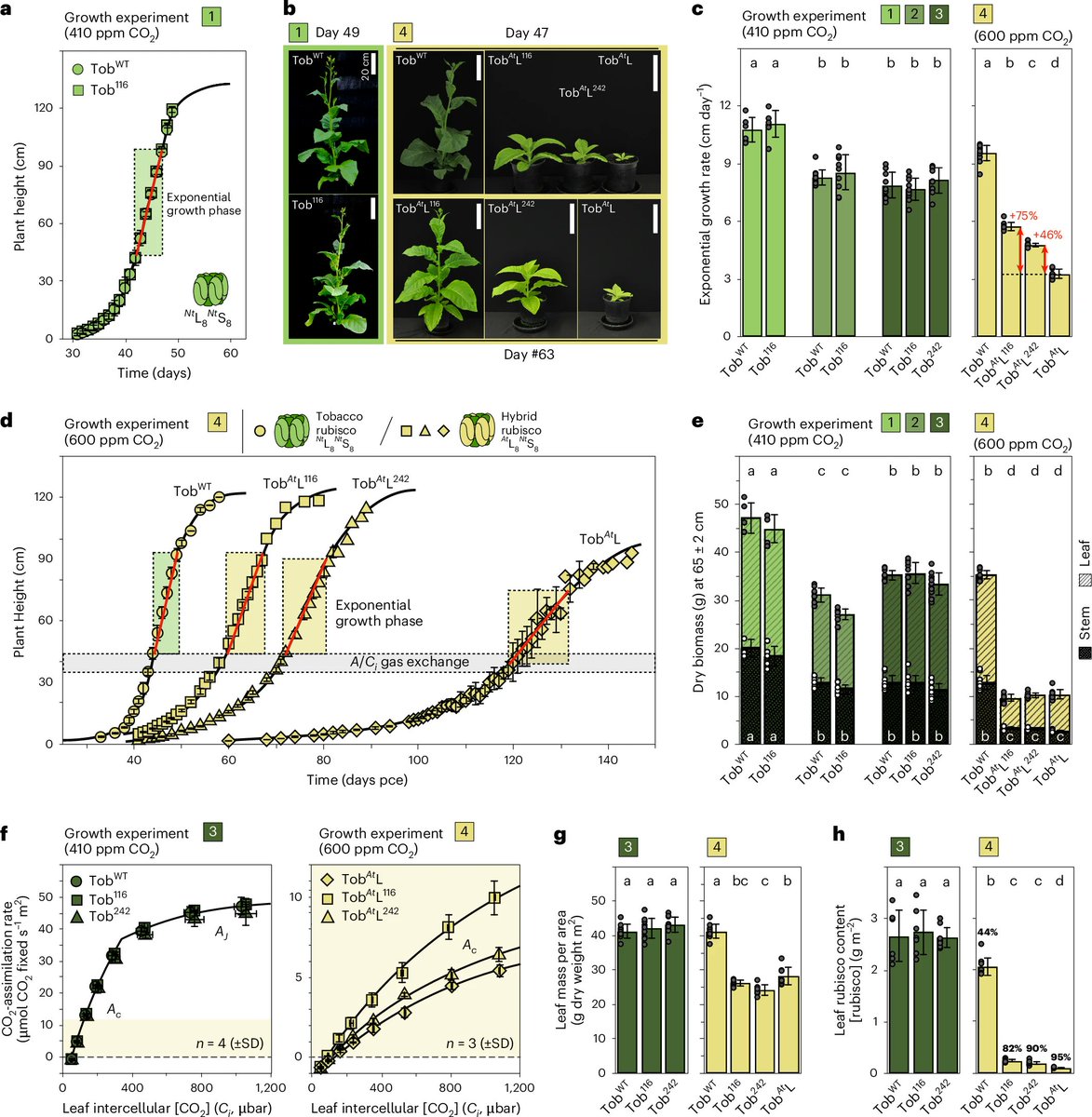
Using this "screening assay," the researchers found 46 fast-growing colonies of E. coli. Two of those colonies encoded really useful mutations. One mutation (M116L) makes Rubisco about 25–40% faster. The other (A242V) makes it fold and assemble much more efficiently.
They put this mutation into a "hybrid Arabidopsis–tobacco Rubisco," put that into tobacco plants, and measured growth. The plants with M116L grew 75% faster than wildtype.
No guarantees this will scale to more useful crops, like wheat and corn and soybeans etc. But it seems like a nice in vitro assay for faster prototyping!
Cultivated meatballs, bacon, and salami made without animal slaughter will soon be sold in U.S. grocery stores for the first time (one Sprouts market in Oakland).
The pig that donated the cells is still alive, living happily in upstate NY:
https://t.co/dDdUrEEsh8
Imagine if every historic square became a forest. 🌳
Should cities worldwide reimagine their iconic plazas this way—balancing history, climate resilience, and livability? 👇
A new paper in Cell shows that it is possible (simple, really) to convert DNA-editing CRISPR proteins, such as Cas9, into RNA editors.
All you have to do is delete a chunk of them.
Deleting 55 amino acids from a DNA editor called IscB (the ancestor of Cas9) turned it into a “robust and versatile” RNA-guided RNA editor in human cells. This modified protein was used to cut mRNAs, knockdown gene expression levels, and even make an A-to-I base editor for RNA.
There are existing RNA-editing proteins, of course, with Cas13 being the most commonly used. Cas13 uses a short snippet of RNA to seek out, and then cut, target RNA molecules. But it also has a major problem: After it cuts its target RNA, Cas13 causes “collateral damage” by also randomly chopping up nearby, bystander mRNAs. This is toxic to bacterial and mammalian cells.
So in this paper, the authors deleted a part of the IscB protein (called the target-adjacent motif interaction domain, stretching from amino acids 433-487), which is normally responsible for its grabbing tightly onto DNA. And that deletion alone converted this protein into an RNA editor. The reason this works is because IscB naturally grabs onto both DNA and RNA, but is heavily biased toward DNA. So this deletion just removes its ability to grab onto DNA, thus biasing it to RNA.
The resulting RNA editor is not only “more active than Cas13,” according to the paper, but it also “has no discernible cytotoxicity in human cells.” The author also show that the same exact approach works for other Cas proteins, including Cas9. Lots of gene editors can be converted into RNA editors, in other words.
Good paper. Gene editors are even more versatile than we appreciated.





























![NikoMcCarty's tweet photo. Why do cloning tools still suck? This problem seems like a low-hanging fruit for AI to solve.
Today, if a scientist wants to make a new plasmid or DNA sequence, they often go into their freezer, figure out which DNA sequences they have, upload those DNA sequences to Benchling (or another platform), and then must figure out how to "convert" those sequences into what they want. Should I do Golden Gate or Gibson Assembly? What annealing temperature should I use for my primers? And so on.
There are already tools that help with each of these steps, but has anybody "automated" this decision-making? If so, I'm not familiar with them. (A tool called J5 is probably the closest thing, but it won't recommend the optimal method given a scientist's existing sequences and primers.) And if the scientist makes even one error in this multi-step design process — like forgetting about an internal restriction site in a gene — they basically waste an entire week of work.
(You might object to this and say, “But DNA synthesis solves this problem; just synthesize the full plasmid directly!” But people have been saying that for decades at this point, and DNA synthesis costs have not fallen in several years. Cloning DNA remains essential.)
What we need is a fully automated, end-to-end cloning design tool that selects the best method based on a library of existing sequences and primers; a tool that recommends the optimal approach based on cost, speed, and so on. “Design tools” for cloning may not seem like a sexy thing to work on, but whoever solves it will marginally improve the lives of many scientists.
With this in mind, I’ve given $1,500 in microgrants, courtesy of Astera Institute, to two people — Jai Padmakumar and Xavier Bower — who have been thinking about this problem. Bower has already built an open-source prototype, called IceCreamClone. (Visit icecreamclone[dot]xavbio[dot]com to see a demo.)
Here's how a tool like this should work:
First, you specify the plasmid you want to build. Then, you upload your current plasmid library, a collection of DNA sequences already in your inventory, and existing primers. The tool takes these data and outputs multiple cloning protocols based on different metrics, such as lowest cost, fastest speed, or the protocol most likely to be successful. The tool also runs a series of checks on all the sequences to make sure they don’t have internal restriction sites, for example, or weird secondary structures.
It would be particularly cool if scientists using this tool could opt-in to sharing their data. The tool could then prompt them afterwards: How did the cloning go? Can you upload the results? Over time, this feedback data could be used to train predictive models that make cloning far more likely to be successful.
Of course, there are issues with this idea. For one, it requires that people upload their entire catalog of existing sequences + primers, which is quite tedious for some laboratories; especially those with decades of cloning experience. Ideally, these tools would directly integrate with Benchling and Addgene.
Anyway, I continue to think this is a "low-hanging" problem worth working on. Whoever makes an easy-to-use, end-to-end cloning design tool with really good predictive accuracy could presumably make a small business out of it. And, in doing so, you'd make many people happy!](https://pbs.twimg.com/media/HF9WynObYAAc376.png)