A declarative graph DSL for neural networks. Tag streams, build residuals, compose trained subgraphs as frozen Modules in larger architectures. Every level addressable by name.
"The structure IS the text."
Full post: https://t.co/RbWAkaLLPq
Phase one was loading. Phase two was fine-tuning, now plumbed end-to-end.
Phase three is the demo on the hardware people actually own.
Next: ModernBERT, LLaMA, LoRA, ViT, plus a flagship El Che fine-tune benchmark on heterogeneous consumer GPUs.
Three new families:
ALBERT (factorised embeddings, cross-layer sharing)
XLM-RoBERTa (multilingual SentencePiece, ~250k vocab)
DeBERTa-v2/v3 (disentangled attention, mask-gated embeddings)
MLM heads across all six families. fill_mask one-call for any checkpoint.
Universal Trainer for transparent fine-tuning.
You write one closure (forward + loss); the framework owns the loop, backward, optimizer step, gradient sync.
Same code on CPU, single GPU, or heterogeneous multi-GPU. El Che cadence auto-tunes the slow card.
Round-trip export is the flagship.
fdl flodl-hf export --hub <repo> --out staged/
fdl flodl-hf verify-export staged/
Re-emits any flodl-hf checkpoint as an HF-canonical dir that loads back into HF Python's AutoModelFor* with bit-exact agreement on every head output.
flodl is two months old.
Tensor + autograd, full nn parity, declarative graph DSL, transparent multi-GPU on heterogeneous hardware.
The line that's stayed true:
"With flodl I don't rewrite when I pivot. I add or remove a graph member."
Full post: https://t.co/f81f5w7zJp
The bet: libtorch FFI through a thin C++ shim.
Not pure Rust. Inherits libtorch's footprint. In exchange:
CUDA parity today. NCCL today. Tensor Cores today. Mixed precision, CUDA Graphs, fused optimizers.
Not in six months. Now.
Two false starts.
Go first. The project was called goDL. GC and GPU memory don't compose. You end up with tensors the GC thinks are dead but the GPU is still using, or the inverse.
Rust was the answer. Ownership instead of GC.
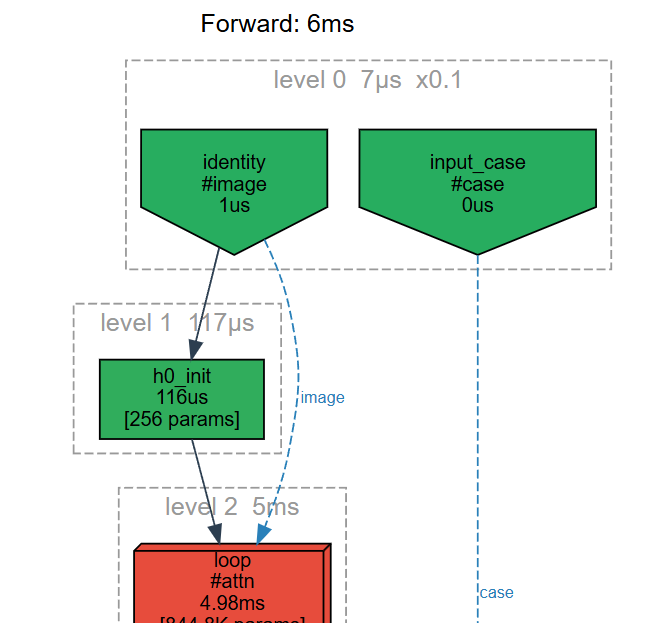
The shape: FBRL (Feedback Recursive Loops).
Letters read by attention, classified, reproduced. Words compose frozen letters. Lines compose words. Each level frozen as an oracle for the next.
Nested. Partially-frozen. Graph-shaped.
Python did not enjoy this.
I'd never trained a deep learning model in my life.
Then I built one in Python, pivoted three times, and watched the script bloat with freezing and recomposition boilerplate.
So I wrote my own framework. In Rust.
🧵
Foundation for the fine-tuning arc: these three families + AutoModel are the gateway to fine-tuning published checkpoints on heterogeneous consumer GPUs with ElChe.
Next on the roadmap: ModernBERT, LLaMA, LoRA, ViT. Then the fine-tuning loop itself.
One command scaffolds a playground inside any flodl project:
fdl add flodl-hf
cd flodl-hf
fdl classify
Drops a side crate pinned to your flodl version with an AutoModel example ready to run. `fdl init my-model --with-hf` for fresh projects.
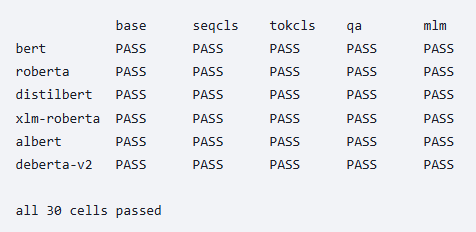
Numerical parity against the HuggingFace Python reference: 9 pinned checkpoints, max_abs_diff ≤ 1e-5 across all three families and three task heads.
Observed on reference: bert-base-uncased pooler 9.835e-7, DistilBERT SeqCls 2.384e-7. Reproducible via `fdl test-live`.
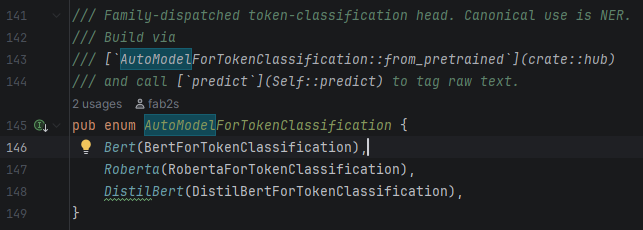
One line, any family: AutoModelForSequenceClassification::from_pretrained(repo_id) inspects config.json's model_type and dispatches BERT/RoBERTa/DistilBERT automatically.
Same three-line caller for bert-base-uncased, roberta-base, distilbert-base-uncased, or any fine-tune.
BERT in flodl is now `from_pretrained("bert-base-uncased")?` 🧵
flodl 0.5.2 ships flodl-hf: BERT, RoBERTa, DistilBERT + three task heads each (seqcls, NER, QA), AutoModel dispatch, PyTorch parity at max_abs_diff < 1e-5.
Full changelog: https://t.co/ItlXC8pDgc
Setup needs Docker + a matching libtorch variant; `fdl setup` walks through GPU detection and image builds.
Rust + DL folks, feedback welcome, especially on `fdl bench` and the DDP surface.
`fdl init my-project` now asks: Docker, or native?
Docker gets host-mounted or baked libtorch. Native skips the Dockerfiles, cargo builds on the host.
Three self-consistent scaffolds, one interactive pick. The scaffolded Makefile is gone.
Rust binaries using `#[derive(FdlArgs)]` have always exposed `--fdl-schema` so `fdl` help + completion + validation come from one struct.
0.5.1 extends it to scripts. `benchmarks/run.sh` emits the same JSON via a heredoc at the top. `fdl` auto-probes and caches it.