Come visit the IVUL posters and oral presentations at #CVPR2026! @KAUST_News
Poster numbers and presentation times for each paper are highlighted in the colored boxes.
See you there!
@neerjathakkar@GoogleDeepMind Great work!!
We applied a similar approach for the problem of video self supervised learning by predicting masked point tracks. https://t.co/jB1QAVVaSn
Would be interesting to incorporate the token representation of the point tracks from your paper for video SSL learning.
Ready to rise among the next generation of #AI innovators?
Apply for the #KAUST Rising Stars in AI Symposium, organized by the #Center of Excellence for Generative AI, and join a global cohort of AI innovators!
Deadline: Nov 15, 2025
🔗 https://t.co/BaD8XnSCkQ
Just released "DiffCLIP", extending Differential Attention proposed by @ytz2024 to CLIP models - replacing both visual & text encoder attention with the differential attention mechanism!
TL;DR: Consistent improvements across all tasks with only 0.003% extra parameters!
Super excited to share that 4 papers from our @KaustVision IVUL lab got into #CVPR2025! Huge congrats to all the authors and our amazing collaborators! 🎉👏
@CVPR@KaustResearch
Our #ACCV2024 Oral "LocoMotion: Learning Motion-Focused Video-Language Representations" w/ @fmthoker and @cgmsnoek is now on ArXiv https://t.co/GpqIPGxrNU
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.
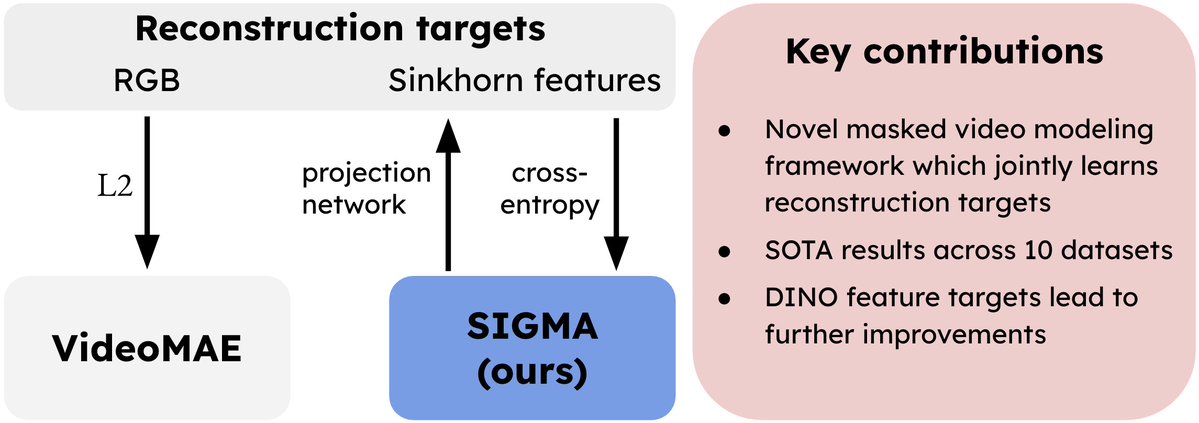
🚀 Excited to present SIGMA at @eccvconf ! 🎉 We upgrade VideoMAE with Sinkhorn-Knopp on patch-level embeddings, pushing reconstruction to more semantic features. With @mdorkenw.
Let’s connect at today's poster session at 4:30 PM, poster number 256, or send us a DM.
📢SIGMA: Sinkhorn-Guided Masked Video Modeling got accepted to @eccvconf#ECCV2024
TL;DR: Instead of using pixel targets in Video Masked Modeling, we reconstruct jointly trained features using Sinkhorn guidance, achieving SOTA.
📝Project page: https://t.co/uV9SA7NbZK
🌐Paper: https://t.co/FYR2NERPft
Joint work with @MrzSalehi@fmthoker@egavves@cgmsnoek@y_m_asano
Next Thursday at #ICCV2023, we'll present our work on self-supervised learning for motion-focused video representations.
Work w/ @fmthoker and @cgmsnoek
We learn similarities between videos with identical local motion dynamics but an otherwise different appearance.
1/6
How to do research:
https://t.co/hRLPmxTfAb
Summary :
1. Slow down to speed up.
2. Find why something does not work as much as possible.
3. Hard working is necessary .
4. Collaborate. Small piece of a big cake> Big piece of small cake.
5. Communicate effectively.
#icvss23
Happy our paper 'Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization' was accepted to #ICCV2023.
Congrats @fmthoker!
Preprint: https://t.co/U4cmValmcL
@re5e1f @CVPR I along with many other students from Netherlands have been waiting since march. It seems the effort to expedite the process didn’t reach anywhere.
Check out our EXCITING lineup of invited speakers for the @CVPR#CVPR2023 2nd Workshop on Learning with Limited Labelled Data for Image and Video Understanding 🤗
https://t.co/bZC2h50H00